
Topics
-
TSMC, the world's biggest chipmaker, is planning a significant price hike. Reports from Nikkei Asia indicate that they'll be increasing their chipmaking costs by as much as 10% starting in 2027. This move could impact the cost of many electronic devices we use daily. View the full article
-
Q891 Scenario An organization sells something to a large base of customers — this could be a product, a subscription, a service, tickets, or a booking. Right now it charges one price for everyone. Its yearly revenue is about $50M. An AI pricing model can switch this to personalized pricing: instead of a single price, it sets a price tuned to each customer, based on signals like their history, timing, location, and how much they seem willing to pay. Some customers would be offered less than today



Leaderboard
-
Vishwadeep Khatri
Administrators20Points6,686Posts -
Sumukha Nagaraja
Fraternity Members15Points23Posts -
Ayomide
Members13Points10Posts -
Pavitra Jain
Members8Points5Posts



Popular Content
Showing content with the highest reputation since 07/21/2025 in all areas
-
At our e-commerce product company, we have an AI powered search and recommendation engine feature. It can be configured on each customer project to leverage multiple data sources (ERP, e-commerce, PIM, purchase history) to personalize search and product recommendations. Personalization features include adjusting results based on purchase history, brand preference, and customer profiles. Our learning has been The recommendation engine can personalize shop assortment for different customer segments. While designing customer flows for this feature, we must ensure that the engine does not unintentionally limit catalog visibility or surface exclusive categories disproportionately. If historical purchase data, browsing patterns, or segment profiles reflect societal biases (e.g., preferences along gender, age, ethnicity, or socioeconomic lines), the algorithms can and will replicate and propagate these biases—such as recommending certain products less to some demographic groups or showing limited assortments. Segment-based catalog restriction could reinforce silos and limit choices for certain customer groups, mirroring or reinforcing pre-existing marketplace or data biases. Customizing algorithmic weighting based on customer profiling without scrutiny could favor or disadvantage groups. We had a real example of a sports attire retailer using our product where we experienced that “Inclusive Sizing” (sizes beyond standard American XS–XL, such as plus sizes or petite/tall fit) appeared in only about 10% of products in a given search result. The dynamic facets logic tended to omit these size attribute from the filters entirely. As a result: Customers seeking inclusive sizes were unable to filter effectively. The represented bias favoured mainstream size ranges, thus marginalizing niche segments. The system then further skewed visibility toward products that align with majority sizing, and had potential to worsening representation over time. Some real world complains from users were - "I can never find anything smart with a good price in my size unless they are your top-of-the-line products" - "I see models wearing new designs in the ads but I can't find enough trendy but age-appropriate colours on the website" Additionally, one real risk that was evaluated was that our model/engine might consistently push popular products from high-traffic regions, while under-representing niche or emerging markets. This not only skews visibility but may also limit growth opportunities for less dominant segments. Some steps that we have attempted to apply Design Phase - Curate diverse and representative data inputs - Allow manual overrides for known critical attributes and for attributes deemed socially or commercially significant (e.g., inclusive sizing, accessibility features) were treated as “defined facets,” ensuring consistent visibility regardless of prevalence. - Ethical guardrails in personalization logic: Forbid certain features (like region or size) from driving recommendation weighting unless justified. Testing Phase - Synthetic Test Profiles across demographics - Manual Testing to find if the engine is developing such biases Monitor and Audit Facet Presentation - Track which facets are consistently hidden across queries and evaluate whether they represent systematically underrepresented groups or product lines - Before releasing compliance review is emphasized on Legal, Privacy(GDPR), Security & Accessibility These proactive steps are now taken on early and help ensure our AI serves all buyers fairly, avoiding the “bias in, bias out” trap in new implementation projects.6 points
-
Is AI solution biased? Well before asking this question, let us dwell more into human nature, is human response or process building biased, it has to be, it forms the basis of selecting criteria, a baseline on which the entire process is set or supposed to operate. Similarly, when we create an AI agent there will be a bias in AI-enabled customer service processes, especially in banking—can have serious consequences, from unfair treatment of customers to regulatory violations. Let’s break this down using your example of a third-party contact center handling banking queries, such as Annual Maintenance Charges (AMC) or unauthorized UPI transactions, and explore how bias can creep in and how to mitigate it. What Bias Can Appear in Banking Customer Service and Where? 1. Case Prioritization Risk of bias: AI may prioritize cases based on customer profile (e.g., high-value customers), potentially delaying resolution for others. E.g: AMC-related queries from senior citizens may be deprioritized if the model learns they are less likely to escalate. 2. Action Recommendations Bias possibility: AI may suggest refunds or escalations based on historical patterns that reflect biased decisions. Example: UPI fraud cases from Tier-2 cities may be less likely to get recommended for escalation due to historical underreporting. 3. Response Generation Bias Risk: Regional models may respond taking into consideration the tone of voice, choice of words, AI agent will respond differently given the tone, politeness and choice of words for customers based in northern part of India versus the same AI agent might find the customer’s similar language or choice of words as rude or condescending and might deny service in southern part of India. Language models may respond differently based on customer name, language, or tone. Example: A polite query may get a more helpful response than an agitated one, even if both are valid. 4. Billing Model Influence Bias Risk: If billing is based on connect minutes, agents may be incentivized to prolong calls. If based on call count, they may rush. Example: AMC queries may be wrapped up quickly without full resolution under a per-call billing model. So, what do we do to minimize bias in Design, Testing, and Monitoring A. Design Phase Diversify Training Data Be it low income customers or high rollers, you might want to include varied customer profiles, geographical regions of customers, languages, net worth of customers, and complaint types. Low amount frauds or frauds based on a certain amount should not matter when a customer is complaining of an unauthorized transaction by a merchant. There is a possibility of bias setting in based on a low or high amount transaction, AI might prioritize only high amount unauthorized transaction cases. We must ensure representation of certain vulnerable groups (e.g.,low income, senior citizens, rural customers). Provide clear objectives that kill bias Design AI models with fairness constraints (e.g., equal resolution rates across demographics). Avoid optimizing solely for efficiency metrics like AHT (Average Handling Time). Human-in-the-Loop Keep humans involved in sensitive decisions (e.g., refund approvals, fraud escalations). B. Testing Phase Inclusion of Bias Audits Test model outputs across different customer segments. Use synthetic data to simulate edge cases (e.g., same query from different regions). Scenario-Based Testing Create test cases for AMC and UPI queries with varying tones, languages, and urgency levels. Check for consistency in response quality and resolution. Metric Diversification Track fairness metrics alongside performance metrics (e.g., resolution equity, escalation parity). C. Monitoring Phase Set up real-time dashboards Monitor call outcomes by customer segment, query type, and agent behavior. Flag anomalies (e.g., unusually short calls for UPI fraud cases). VOC : Feedback Collect customer feedback post-call and correlate with AI decisions. Use feedback to retrain models and adjust flows. Billing Model Alignment Ensure billing models don’t incentivize biased behavior. Consider hybrid models (e.g., quality-adjusted call count) to balance efficiency and fairness. How do we break the “Bias In, Bias Out” Cycle Continuous Learning: Regularly update models with new, unbiased data and feedback. Make it transparent: Make AI decision-making explainable to agents and supervisors. Assign ownership: as a check mechanism, assign accountability for bias monitoring and remediation. Cross-Functional Collaboration: Involve friendly customer base, compliance team, QA team, and customer experience teams in AI governance.3 points
-
Here's a methodical and useful way to keep track of versions, make sure performance is good, and produce clear documentation for AI processes and prompts that vary over time: 1. Make a formal versioning system Think about AI processes and prompts as code instead of making arbitrary changes: You can save your prompt and flow definitions as text files (JSON, YAML, Markdown) in Git or a program like it. Semantic Versioning makes it easy to communicate about changes: Major: A substantial alteration in the design's purpose or flow. Minor: New features or better prompts. Patch: Fixes or small modifications. Add commit messages that say what the change is meant to do and why it was made. Put both the prompt text and the evaluation/test cases in the same repository so that you can observe both the inputs and the outcomes over time. 2. Make a registry for Prompt and store information about it. Keep a well-organized register (this might be a spreadsheet, a Notion database, or an internal tool) that has: ID of the version Date of Release Writer/Owner Changes Explained Results of tests that are connected Cost, accuracy, latency, and satisfaction are measured/ indicates performance. Rollback Reference - to the previous version This registry is your traceability source to/whether you compare or go back. 3. Check Before You Start To make sure that upgrades are useful and not harmful: Use fake and real test cases from the past to execute the new flow/prompt in a sandbox environment. A/B Testing: Send a small quantity of traffic to the new version and see how it compares to the baseline version. Regression Checks—Check that crucial KPIs don't go down for scenarios that are known to be good. When you can, automate tests by generating a list of queries and expected outputs ahead of time and running them on both old and new versions. 4. Document errors/problems with corresponding causes If you change something, be sure to add: The problem statement, such - users didn't understand step 3 in the flow. The theory, like - making the language easier should lead to more people finishing. The proof after deployment, such as - the recall rate improved from 72% to 84%. You or another developer will be glad know what was wrong when you look at older versions again. 5. Be ready to go back Make sure that the last stable version is always straightforward to install. Make it easy to roll back your deployment process, ideally with only one click or command. Write down when and why rollbacks occurred. They can be just as useful as changes that happen in the future. 6. Find a way to blend stability with new ideas. The Innovation Track is an experimental branch, where you may test new techniques to get engineers to work without putting the stability of production at risk. Stable Track: Flows that are ready for use and only get revisions after a lot of testing. Changes from innovation should only be merged to stable when the metrics/performance are fine. This is basically a two-speed paradigm for development: fast testing and slow release. An example of a workflow Create a new prompt in any AI tool. Make your commitment clear: Make step 3 clearer to cut down on drop-offs. Do automated testing and have people look at old cases. Send 10% of traffic to A/B testing. If the metrics improve, merge into the main branch and change the version. Put notes and numbers in the Prompt Registry. Conclusion Managing different versions of AI flows and prompts requires the same amount of attention as building software. The best method to do this is to put together: Git and semantic versioning are examples of structured version control. Centralized Documentation (a registry with performance logs and other information that is easy to access) Strong testing and rollbacks, such sandboxing, A/B testing, and automated regression checks Two-speed development means having a solid track for production and an innovation track for testing. This makes sure that every change can be logged, tested, and undone, which helps teams come up with new ideas quickly while keeping things stable. In short, always have a way back, write down the why, and test the what.3 points
-
When we first started using AI to track production downtime patterns, I built a simple flow that pulled operator inputs and generated quick insights for the shift leads. At one point, I decided to tweak the prompt that asked operators to describe the issue, just to make issues clearer and easy to understand by the technical team. I thought it was an improvement. A week later, my phone was buzzing during a site visit because the reports coming out of the system suddenly had big gaps. Turns out my “clarity” change made operators give shorter answers that didn’t have enough detail for the analysis to work. Since then, I’ve treated AI flows exactly the way I treat any process change in manufacturing: I save every version before I touch it. Not just the file but a quick note on what I changed and why. I run the new version in a controlled test with a small team, not the whole plant. If it performs better on the KPIs we care about like accuracy, speed, usability, then it graduates to live. If it doesn’t, I roll it back in minutes because the last good version is sitting in my folder. I also keep two environments: the stable one for what’s proven, and a “playground” for experiments. That way, I can test bold ideas without worrying about disrupting a live process. It’s the same mindset I use in CI projects: measure first, change deliberately, and always keep the option to go back. With AI flows, that discipline makes the difference between steady improvement and a messy guessing game.3 points
-
How I Would Build a Feedback System for an AI Customer Service Agent? It’s like hiring a new customer service rep. - you would not throw them in front of customers on the first day and hope for the best, instead you would watch how they perform, collect feedback from customers and supervisors, and help them improve. An AI agent needs the same kind of ongoing training. Three Ways to Collect Feedback Ask Customers Directly but Keep It Simple: After the AI helps with a real question, show three quick buttons: thumbs up, neutral face, or thumbs down. Include a small text box so customers can add a quick note such as “Did not understand my mortgage question” or “Gave me the right answer but sounded robotic.” The key is to ask only after meaningful conversations, so customers are not continuously prompted after every single interaction. Have Human Experts Check the AI’s Work Once a week, experienced supervisors can review a sample of conversations, focusing on ones with poor ratings, long resolution times, or high-stakes topics like compliance. They will spot details that metrics miss, such as “The AI gave correct information but did not recognise that the customer was frustrated about a fee.” Reviewing a sample, rather than every conversation, keeps the process manageable. Track the Numbers Monitor essential metrics such as first-time resolution, the number of cases escalated to human agents, and average resolution time for each case. Occasionally, you may send test questions where you already know the correct answer to ensure the AI is still performing well. Making Sense of the Feedback Collecting feedback is easy, making it useful takes work. Start by grouping similar issues together, such as “Does not understand regional accents,” “Too formal when customers are upset,” or “Provides incorrect information.” Prioritise by severity. A calculation error is far more serious than sounding overly formal. Look for patterns, for example, whether accuracy drops on Mondays when there is a backlog from the weekend. Three Speeds of Improvement 1. Quick fixes can be made in a day or two, such as updating outdated information. 2. Regular updates can happen once a month, retraining the AI on the most common issues identified in the feedback. 3. Big changes, such as adding advanced document-reading capabilities such as OCR, will take longer and require more planning. Avoiding Feedback Overload Too much feedback can overwhelm the team; focus on the interactions that reveal the most. Address urgent issues immediately and save routine improvements for the monthly review. Once an issue has been resolved and stays fixed for a few months, stop monitoring it closely and turn your attention to new challenges. Keep People Involved Let customers and employees know their feedback matters. If you improve the AI’s ability to answer product questions based on someone’s suggestion, say so: “We have improved how our AI handles product inquiries based on your feedback.” When employees see that their input leads to real improvements, they will continue offering valuable suggestions. The Bottom Line Maintaining an AI agent is like maintaining a car. You make small adjustments as needed, schedule regular check-ups, and only conduct major repairs when something fundamental needs to change. The goal is steady improvement, so the AI gets better every week without frustrating customers or overwhelming the team.
 3 points
3 points -
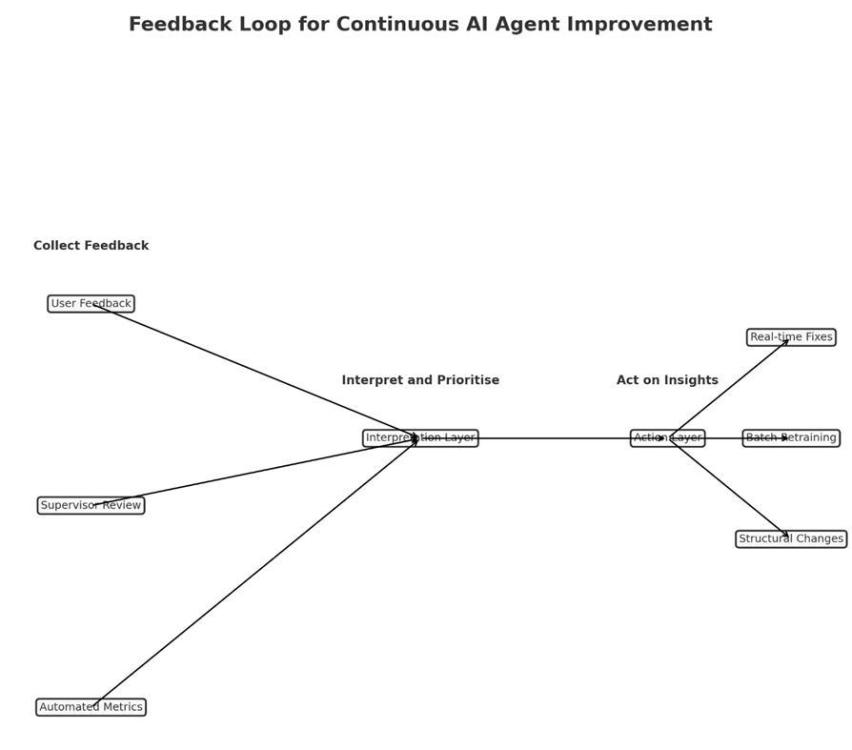
Let's look at a real-world scenario to see how to construct a strong and valuable feedback loop for improving an AI agent after it has been put into operation. For instance, an AI customer service person that works for a company that provides financial services. This assistant helps people who have inquiries about how to manage their accounts, make purchases, and receive support with items. A Look at Feedback Loop Design There would be three stages of the feedback loop: Feedback that the user begins (Explicit) Feedback that the system gives you (implicit) Human (Supervisor or Lead) in the loop (HITL) should check it out. A centralized feedback processing pipeline receives feedback from each layer, sorts it, rates it, and sends it to either Automated learning modules for modifications that aren't too risky People look at significant or private issues in lineups Ways to collect feedbacks or comments 1. Clear feedback from users After each communication, you can give them a thumbs up or down or a star rating. Inline modifications or recommendations, like "That's not what I meant," start the process of capturing the intended revision. Short surveys after each session to get qualitative feedback Design tip: Keep it light and optional. Only ask for help after a big interaction or when a task is finished or not. 2. Implicit Feedback on Behavior: When a user quits a chat in the middle of it, they are giving feedback on their behavior. Asking the same inquiry over and over or getting a human agent involved Latency or hesitation (the user takes a long time to respond or suddenly changes the subject) To locate places where people are having problems interacting, these signals are marked and given a score. 3. Comments from the supervisor and the audit There are notes about human agent escalations, such as "AI got the request wrong." Random encounters are scored and grouped by quality during periodic audits (for example, tone mismatch or outdated information). Tagging for compliance, especially in sensitive areas like delivering financial advice Feedback that has been marked by a boss is more important. Getting criticism and learning from it Tiered Processing Pipeline: Automatically tagging and grouping similar problems, such "tone issues" and "entity mismatches," using heuristics and NLP classifiers. Making a decision based on risk assessment: Is it possible for the model to fix itself by retraining? Do you need to update the template or prompt? Or should this go to human developers? Routing Feedback: Adjusting the prompt or retraining on grouped samples automatically applies low-risk fixes. A person must look over and approve high-risk fixes before they may be added. How to Avoid Getting Too Much Feedback: Threshold-based Sampling: Only reveal feedback when there is a pattern, such when five or more people complain about the same item. A way to put feedback in order: Impact (frustration score) twice Frequency is the same as Priority Score Digest of the Day: Dashboards for teams that illustrate the most significant issues, possible solutions, and plans for putting them into action. Feedback Archiving Windows: Old feedback that has been dealt with is put away so it doesn't happen again. Finding Tone Mismatches: An Example in Action Users give the bot a "rude" rating in more than 10 sessions when it responds to late payments. A high pace of escalation in those negotiations is an implicit sign. The supervisor says that three interactions are "too formal." The system puts these together and offers a prompt modification to soften the tone: You haven't paid yet. Please repair this right now. To: "It looks like your payment is late. Let's work together to make it better! Used through A/B testing, watched, and proved that it got better Summary: Why This Works Practical: in the Real World Uses real signals (both implicit and explicit), automates low-risk tasks, and gets people involved when they need to be. Relevant: directly applicable to areas such as healthcare, HR support, financial services, and others. Balanced: teams are always getting better without too much stress, and there are built-in safety safeguards and human oversight.3 points
-
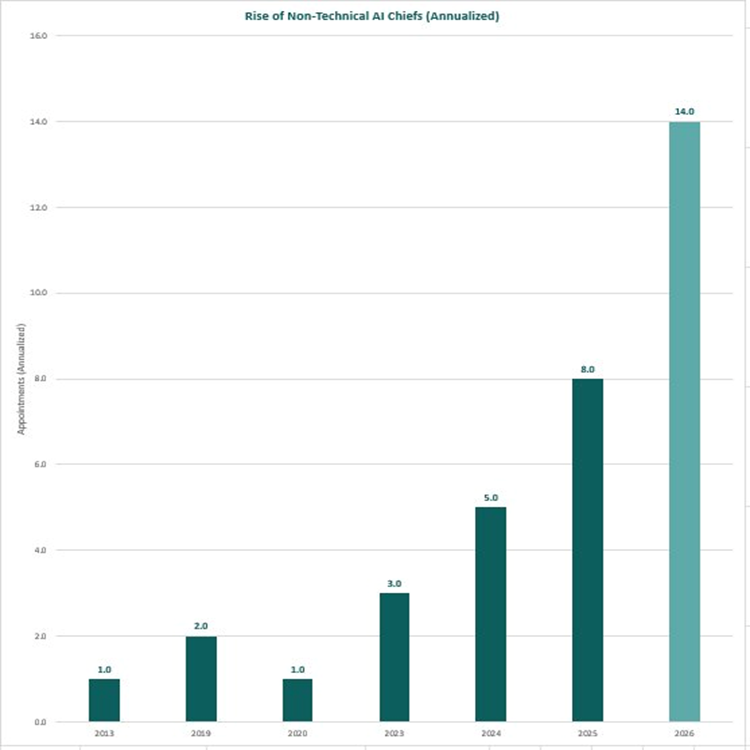
For years, the assumption was that “Chief AI Officer” meant a machine learning PhD, a data scientist, or a software engineer who could build models. That assumption is rapidly being dismantled. A clear trend is emerging across global enterprises, law firms, governments, and financial institutions: non-technical business leaders — lawyers, consultants, operations executives, economists, and brand strategists — are being appointed to the most senior AI leadership roles. And the pace is accelerating dramatically. The Numbers Don’t Lie Year New Non-Technical AI Chief Appointments Annualised Rate 2013 1 1 2019 2 2 2020 1 1 2023 3 3 2024 5 5 2025 8 8 2026 6 (Jan–Apr only) 14 (annualised) Rise of Non-Technical AI Chiefs (Annualised) In just the first four months of 2026, six non-technical leaders have already been appointed to Chief AI Officer or equivalent roles. Annualised, that projects to 14 appointments for the full year — nearly double the 2025 figure, and 14× the rate seen in 2019. This isn’t a blip. It’s a structural shift. Who Is Actually Getting These Roles?Below are documented appointments of non-technical leaders to Chief AI Officer and equivalent roles across major organisations: Organisation Role Background Date Herbert Smith Freehills Kramer (major international law firm) Global Chief AI Officer Lawyer (tech transactions, leveraged finance, legal innovation); former Senior Counsel at Mastercard, Global Head of Innovation at McKinsey Legal November 2025 WTW (Willis Towers Watson) Chief AI Officer Co-founder and former CEO of Newfront (AI-native insurance brokerage); MBA Stanford; finance and scaling expertise (non-coder) April 2026 Louisville Metro Government Chief AI Officer 25+ years in enterprise transformation and AI upskilling at Intel; former paralegal; English/paralegal degrees November 2025 Microsoft Chief Responsible AI Officer Law, Public Policy 2019 Goldman Sachs Chief Information Officer (AI-led transformation) Business + Tech Strategy (not pure coding role) 2019 / 2022 O.C. Tanner Chief Technology Officer (AI-led strategy) Business Strategy December 2013 Deloitte Global AI Institute Leader Business, Consulting ~2020 NTT DATA ($30B+ global tech services) CEO & Chief AI Officer Former McKinsey Senior Partner (TMT); MS Industrial Engineering (Stanford), B.Tech Mechanical Engineering (IIT Bombay); management consulting June 2024 / September 2025 Anthropic Chief AI Readiness Officer / COO Former founding COO of Google DeepMind; prior roles at Coursera (COO), Kleiner Perkins, Intel; engineering degree ~2026 IFS Nexus Black (industrial AI) CEO Former Chief Product Officer for LegalTech at Thomson Reuters; AI product strategy at GfK and Sage; founded AI for Good UK; MA Advanced Computer Science July 2025 HSBC Chief AI Officer COO of HSBC Corporate and Institutional Banking; nearly 20 years in operational and commercial banking roles April 2026 KPMG Vice Chair / Global Head, AI & Digital Innovation Former Head of KPMG US Consulting (15,000+ people); MBA and Master's in Professional Accounting October 2023 / August 2025 Littler Mendelson (employment law firm) Chief Artificial Intelligence Officer Nearly 15 years of employment law experience; led practice innovation at national employment law firm April 2026 Edelman UK Chief AI Officer, UK Communications and brand strategy executive; led integrated campaigns for global consumer and tech brands; Cannes Lions awards September 2024 LVMH Chief Data and AI Officer Director of Strategy and Innovation for EMEA at Nike; strategy and marketplace operations background March 2024 U.S. Department of Homeland Security Chief AI Officer & CIO Cyber and intelligence operations (U.S. Marine Corps); operational and intelligence background, not AI research March 2025 Wells Fargo Head of Artificial Intelligence (also Co-CEO, Consumer Banking & Lending) Former CEO of Consumer & Small Business Banking; former Head of Wells Fargo Technology; appointed from a business-leader seat November 2025 Mastercard Chief AI and Data Officer Former EVP of Corporate Strategy and M&A at Mastercard; corporate strategy and deals background, not engineering 2024 New York State (Office of Information Technology Services) Chief AI Officer Researcher at United Nations University; founded UN's first AI policy research lab; AI policy and governance background, not engineering January 2026 State of Oklahoma (OMES) Chief Artificial Intelligence and Technology Officer BBA in Management Information Systems; career in technology modernisation and business transformation across Fortune 500 and public-sector; business-and-operations rather than coding background November 2025 U.S. Department of Agriculture Chief AI Officer (also Chief Data Officer) Started in private-sector biotech; led data analytics team providing genomic services; data strategy and analytics leadership rather than ML/coding 2023 U.S. Department of Energy Acting Chief AI Officer Former Director for Technology and National Security at the White House NSC; policy and national security background, not engineering December 2023 U.S. Department of Labor Chief AI Officer Earlier Deputy CAIO at DOL; over a decade at the Bureau of Labor Statistics; operations and program management rather than AI research June 2025 U.S. Social Security Administration Chief AI Officer (also Deputy CIO) More than 20 years at SSA in IT operations and enterprise leadership; agency-veteran operational profile 2024 Morgan Lewis (global law firm) Chief AI & Knowledge Officer Former Chief Administrative Officer at a global law firm; business operations and process design (non-technical) 2025/2026 Generali Investments Chief AI Officer PhD/MSc in international macroeconomics; Professor of Economics; former Director of Research; senior roles at World Bank/UN PRI; economics/policy/research focus April 2026 Why Is This Happening?The role of a Chief AI Officer has evolved. In its earliest incarnation, it was about building — training models, architecting data pipelines, writing production code. Today, in most enterprises, the hard technical work is being done by vendors (OpenAI, Google, Anthropic, Microsoft) or by internal engineering teams. What organisations actually need at the C-suite level is someone who can: 1. Drive adoption — persuading reluctant stakeholders, managing change at scale 2. Govern responsibly — navigating legal, ethical, regulatory, and reputational risks 3. Connect AI to business outcomes — translating capability into commercial value 4. Work across functions — bridging legal, HR, finance, operations, and technology These are leadership and judgement skills. Not coding skills. The lawyers, consultants, and operators being appointed to these roles are not naive about AI. Many have deep domain expertise, years of AI-adjacent experience, and strong track records leading transformation. They simply did not build the models themselves. The Acceleration MattersThe annualised 2026 figure of 14 is not just a data point — it reflects a tipping point. Organisations that once waited for a “perfect” technical candidate are now actively choosing experienced business leaders and structuring the role around strategy, governance, and change management rather than engineering. If this trajectory holds, 2026 will see more non-technical AI Chief appointments than all years from 2013 to 2024 combined. The era of the non-technical AI Chief has arrived. What do you think is driving this shift? Are organisations right to prioritise business acumen over technical depth in these roles? Share your perspective below.
 2 points
2 points -
Process Context My team also manages the central master data management for 50+ plants today, and this will grow to 70+ plants by 2027. The entire fleet data management is handled by two people in my team. Every time we commission a new plant or acquire a new plant, we need to align it’s material master with our fleet database, to avoid duplication, planning errors, and wrong spares being introduced into SAP. In a typical post commissioning and acquisition, we review minimum of 5000+ incoming material records against an existing 345000 item fleet master. Practically for my team, each item review takes at least 6 minutes without AI. The AI-enabled Process To solve this, I built a Python + AI solution using a MiniLM semantic model, combined with rule based checks. The program setup classifies each incoming item into three categories, Auto, high confidence match to directly map & upload in SAP. Review, ambiguous match, reviewed by the master data team. Reject, no valid match, program generates a new master data creation template for my team, to directly load into SAP. You can clearly see, AI does not create master data blindly in this case, it recommends, and the team decides. When We Trust The AI I have defined clear rules after testing the model for almost 10 days with millions of lines, semantic similarity is high & critical identifiers (model number, size, rating). It checks if descriptions and attributes are complete and consistent. One more rule I have setup is to keep standard, low-risk categories, and excluding verified MRP items, and these items directly flow straight into Auto category & are uploaded without manual touch. When We Override The AI Team deliberately does the review when similarity scores are close across multiple candidates, technical digits conflict even if text similarity is high. Then we also look at if item is maintenance critical or safety critical. We jump to the poor descriptions as well. In all such cases, team’s priority is correctness, not the speed. Safeguards That Keep The Balance We have built simple controls to avoid blind trust or even excessive overrides, Strict thresholds for Auto classification, mandatory team’s review for all Review cases, spot audits of Auto mappings, tracking & analysis of override patterns to improve program, and we have clear ownership, AI suggests, Team decides. Impact In Real Numbers Now with this program, my team completes 5000 item migration in 10 days in total instead of 2 months. I have a clear breakdown of 10 days, Data setup + AI pre-load + first analysis is done in 0.5 day SAP mapping for Auto category takes 1 day Manual review is done for Review category in 7 days New MD setup for Reject category is done in 1.5 days This has really improved my team’s output and bandwidth, and also reduced the onboarding risk for new plants, and best part is, it is allowing two people to scale this work for our growing fleet. Bottom Line I trust AI where signals are strong & mistakes are low impact, I override it where ambiguity or risk is high. As you can see, we are improving the overall process, idea isn’t to remove people from the process, it’s to make sure people spend time only where judgement actually matters.2 points
-
Domain: Aerospace MRO - Engine shop for CFM56/LEAP Turbofans for Performance Restoration (€ 220 Million yearly turnover , approx. 1,800 shop visits in a year, AI rolled over since late 2025 to predict HPT module rework needs based on borescope images, oil debris analysis, and in-service data) Specific AI-enabled process: Predictive HPT Blade Rework Forecasting The AI will recommend if the module needs full blade rework, partial (only the tips), or none, all with the goal of eliminating unnecessary shop time and expense without losing the zero escape target on critical parts. It went live on all CFM56/LEAP visits in Q1 2026 and initially deliver an average 18% reduction in TAT on HPT modules. How we ensure & monitor the process continues to deliver intended outcomes We are treating this AI-human decision loop as a live control system and continuing to develop it over time not like one tine install, the focus is on sustainable business value – TAT savings, cost per visit going down, safety and zero quality escapes. What we monitor (daily / weekly / monthly) 1. Leading indicators (daily dashboard – shop floor + engineering) · Prediction accuracy of AI vs. actual rework result (confusion matrix updated every 50 engines). · AI suggestion Override rate by technicians / engineers (accept, tweak, reject AI recommendation). · Confidence score variation (how often is the model <80% sure?) · Data drift indicators, distributional shift of input variables (eg iron particles in oil, borescope crack density, EGT margin so on) 2. Lagging business outcomes (weekly review – operations + finance) · HPT Module: Turn Around Time Variance (target < 35 days). · Rework cost per engine vs. Baseline · Escape rate / quality holds on HPT (target 0) · Spare Parts Consumption vs. Forecast (Over/Under-Stocking Signals) 3. Model health metrics (monthly deep dive – MBB + data team) · Population stability index (PSI) on key inputs (>0.25 = moderate drift, >0.5 = severe). · Calibration plot (predicted probability vs observed rework rate) · Feature importance drift (which inputs is most important to the model now vs at launch) How we react when the going starts getting tough We have a three-level escalation protocol: Level 1 – Minor Drift (Weekly Trigger) · Override rate >25% or confidence <75% on >20% of cases. Response: · Immediate feed back loop i.e. every override by enginers requires 1-click reason (dropdown + optional voice note). · Retrain model based on last 100 engines + overrides justificatipn. · Notify shop team lead, usually fixes within 1-2 weeks Level 2 – Business impact emerging (weekly trigger) · TAT +3 days or rework cost increased +8% vs rolling 4-week average · OR escape / hold on HPT (even one) Response: · Hold AI recommendations - return to manual disposition within 48 hours/ · Root Cause A3 with MBB: Data drift? New failure mode? Change in user behavior? · Temporary rule: AI confidence > 90% required for auto-accept · Full model retrain + validation on hold-out set before re-release Level 3 – Systemic failure (monthly or immediate on escape) · PSI >0.5 on critical inputs OR calibration slope deviates >15% · OR sustained TAT/cost > 15% Response: · Full pause of AI in production · Independent audit: data lineage, labeling drift, concept drift · Notification to the regulator of any escape which occurred · Re-baseline from scratch or switch to a fall-back approach (manual and old rules) · Shared across sites post-mortem – we’ve had one Level 3 (new low-sulfur fuel changed oil debris patterns in Q3 2026) Practical setup we use today · Automated alerts using Teams/Slack when threshold breaches · Monthly “AI Health Review” (30-min standing meeting: MBB, ops manager, data lead) · Quarterly external benchmark against OEM data (CFM/Pratt) · Annual review of AI usage (EASA Part-145 requirement) Bottom line from the teardown bay AI Drift isn’t an ‘if’ but a ‘when’ In MRO, the price of slow degradation can be a long turn-around time, excessive spares, or even a failure in service. The way we monitor our AI is how we would monitor an engine, performing routine checks every day, and only grounding it completely when we have to. The process remains alive since we do not assume model is “set and forget”.2 points
-
Here are the winners of Q821. 🏆 Winner – Adil Khan (Aerospace Heat Treatment😞 outstanding NADCAP-compliant AI certification plan with controlled trials, Cpk > 1.67, and 4-tier sign-off governance. 🥈 Runner-up – Sattar Mohammad Imran (Complaint Chatbot😞 comprehensive multi-departmental certification and oversight framework ensuring fairness and compliance. 🥉 Special Mention – Arul Palani (AI Code Assistant😞 strong readiness and policy-based certification approach using ISO/IEC 42001 standards.2 points
-
AI is very well capable of interacting with customer and make them feel personal in each interaction by merging data, context and empathy at scale without crossing boundaries of trust. Better customer interactions with less customer efforts and high CSAT scores will definitely help the business expand Customer’s expectation from any service are · Quick response on any queries raised · Receive accurate response on queries raised to avoid asking repeat questions · Faster query resolution with minimum interactions · Easy to interact with and have a sense of personal touch by letting them feel valued, heard and understood · Expect trust on data privacy AI helps in better interaction with customer by: · Collecting the context with consent by pulling required data keeping in mind not using hidden data · Knowing customer better and in depth by building customer profile using data from past purchases, past interactions or support tickets, browsing history, etc · Use smart prompts for Bots that works on prefilling summary and also acknowledge earlier context showing respect and care · Feel customer valued by predicting needs and suggesting next steps that will help query resolution prior customer asks the question · Switch tone basis customer tonality and empathize basis sentiment analysis that reflects customer sentiment For example, Account Payable Helpdesk is the function included in Procure to Pay process that handles queries from vendors, internal or external stakeholders related to invoices processed, payments done and PO created. Below are few AI capabilities mentioned that can be used in AP Helpdesk across PTP: · Build AI Chatbots for automated query handling with 24/7 support and less repetitive tickets · Routes the ticket to required department basis query raised for faster and convenient resolution · Captures invoice data using OCR and NLP from documents or emails · Proactively inform vendors or required stakeholders on invoice status thereby reducing escalations · Resolve complex queries by searching policies, SOPs, etc using intelligent search & knowledge base · Adjust the tone basis customer’s response and urgency thereby building trust · Flags invalid invoices, duplicate payments thereby preventing financial losses2 points
-
Do you know how banks are getting smarter? It is by turning Knowledge as a Competitive Edge : The real game-changer is how they're using everything they know by decoding the customer brain through data by studying their patter 24/7/ 365 days. 1. They are ditching the old for the new Simplify and streamline operations: They are replacing legacy systems with modular, cloud-native architectures which was un-thinkable just a few years ago. Use continuous integration and delivery tools are used to reduce development time and improve agility. In action: Bank of America using Cloud Provider: Private cloud infrastructure. Saved approximately $2 billion 2. Investing big in data and AI They are Building a solid foundation: Banks are building unified data views from their scattered data sources. To connect all the dots which was their biggest pain. Use AI and Gen AI to generate insights, automate decision-making, and to give a personalize customer experiences. Example: Several Autonomous Decision Intelligence Platform is developed by banks to turn fragmented data into strategic assets for fraud detection, risk assessment, and marketing. 3. Shifting focus from maintenance to innovation: Redirecting funds: Tech budgets are being redirected from simple maintenance to things that where it is creating new value. Customer-first focus: The focus has shifted to improving the customer experience, personalizing everything, and getting to market faster. 4. Nurturing the right talent and culture Build a tech-savvy board and leadership team. Gen AI training are provided to the leaders along with it’s application. There is a significant Increase in the proportion of in-house engineers and reduce overhead roles. Foster a technology-first mindset across the organization. Example: Another US Bank Capital One, with it’s 12,000-strong tech team transitioned to a cloud-first model and began selling its own software products. 5. Use AI to Enhance Relationship Management AI isn't just for behind-the-scenes—it's also a powerful tool for customer-facing teams. Smarter advisors: Relationship managers are being armed with AI-generated client summaries, risk profiles, and insights. More meaningful conversations: They are spending more time on strategic, high-value conversations because gen AI solution is providing them with the necessary inputs. The payoff: This is leading to a stronger, more profitable customer relationships and faster decision-making.2 points
-
AI-Powered Incident Management System At our e-commerce platform company (PAAS model), we need to support environments of all customers who rely on our system for their online ecommerce sales and we need to have continuous uptime and meet strict SLAs. We use NewRelic as our observability platform which collects massive volumes of logs, traces and metrics. After filtering we are analyzing over 60TB of telemetry data per month. We’re now building a system to query this data for AI model integration, enabling anomaly detection, incident correlation, and predictive analytics. Decision Making Scenario- Analyzing and classifying incidents in real time When an Alert is generated the Operations Manager need to make quick decisions during disruptions like outages, performance degradation, or critical bugs. These incidents needs to be evaluated quickly due to SLA requirements since they directly impact buyer satisfaction, conversion rates, and revenue for our clients. The challenge is to prioritize correctly, weighing severity, scope, resource constraints when choosing action steps. AI Agent Support We have been working on a design of an Incident Response AI Assistant with the final goal that it will - Aggregates and analyzes real-time data, such as error logs, user requests, system metrics, and incident tickets. - Scores incidents by combining: - Business impact (example: conversion drop, cart abandonment) - Customers or geographies affected - Urgency indicators like large number of error log entries, memory or cpu spike - Generates and recommends priority and type based on pre-learned categorization - Suggests response paths to help mitigate the problem - Quick mitigation (rollback the latest patch) - Escalation (pass to development team) - Monitoring (observe performance metrics) - Offers confidence scores on its solution For this we are creating solution with two key components to support the decision-making and the communication 1) Incident Analyzer Bot which will automatically detect system issues using AI/ML Learn from historical incidents to categorize alerts by severity and type and reduce false positives Correlate related events — for example, grouping three different alerts under a single outage — to help managers see the full picture quickly Find and provide reference of related incidents from our historical data to help provide the manager with information about the previous RCA and solution 2) Ops Chatbot is focused on communication (not customer-facing) If a critical issue is detected, it can notify customers automatically and proactively before they notice it themselves. It supports manual overrides, customizable communication methods (like email, message, chat) with pre-defined message templates. Makes message suggestions to the manager, who can review and approve them directly in tools like Microsoft Teams. Manages follow-ups automatically if the issue remains unresolved — for example, sending timed updates like “we are still analyzing your system” every 1, 6, 12 hrs depending on the case. This AI assistant will help to surface and prioritize incidents quickly but the final decision remains with the manager who reviews the categorization, solution recommendation and approves the communication suggested by AI. The manager will be have full discretion to override, approve, or modify the AI’s actions. We have planned to create feedback loop to help the system learn and improve over time and implement accuracy monitoring by comparing AI predictions to actual outcomes, review the AI's confidence scoring especially when AI uncertainty is high. This regular validation against historical incidents should help us ensure that the human/AI-assistant together work towards meeting customer's SLAs.2 points
-
I recently worked on a project where we built what we called a CO-CEO AI agent for a marketing company. The idea was simple: instead of treating the AI as a background tool, we brought it into the decision-making process almost like another executive. Its main job was to help the CEO design marketing strategies for different clients. Now, here’s the twist. We didn’t just let the AI spit out strategies in isolation. It was invited to client meetings, not literally of course, but through structured prompts where the full context of the client’s business, challenges, and goals was fed in. That way, its recommendations weren’t generic “playbook strategies,” but tailored to the actual discussion the leadership team was having. That made it much more of a trusted advisor than a black-box machine. From this project, I learned that there are two layers to making AI advice truly useful and trustworthy for leaders: 1. Where It Should Assist Pattern spotting across campaigns: Leaders don’t always have the time to compare 50 different client reports. The AI could highlight trends (e.g., “clients in retail are seeing 20% higher engagement when campaigns run mid-week”). Scenario testing: Instead of one “best” strategy, the AI could lay out three options: low-risk, high-growth, or balanced. This gave the CEO choices rather than a single directive. Speed on background research: Before walking into a client strategy session, the AI could summarize competitor campaigns, past results, and market conditions in minutes. These are areas where AI’s scale and speed give leaders an advantage without replacing their judgment. 2. Checks to Keep It Reliable Context gatekeeping: The AI was only as good as the context it had. We made it a rule that client objectives and constraints must be captured first (almost like a briefing note) before the AI gave advice. No context, no strategy. Audit trail of reasoning: Every recommendation had to come with a short rationale, “this works because past campaigns in similar industries showed X, Y, Z.” This gave the CEO confidence in the “why,” not just the “what.” Version control for prompts: As we refined how we asked the AI questions, we tracked changes. For example, when we shifted from “generate campaign ideas” to “act as a CMO and propose three strategies with risks and trade-offs,” we documented it. That way, if a change caused worse outputs, we could roll back quickly. Human override always on: The AI was never treated as final authority. The CEO still made the call, but with stronger input in less time. Honestly, what made this whole setup work wasn’t the AI being “super smart.” It was the way we used it. We never treated it like it was going to run the company or make the final call. Instead, it was more like a second set of eyes, someone in the room who could throw out a few options, show the risks, and spot patterns the rest of us didn’t have time to see. The clever part wasn’t the output, it was the process: making sure it only answered once we’d given it the right context, tracking how we asked questions so we didn’t lose improvements, and always keeping a paper trail of its reasoning so it didn’t feel like magic. At the end of the day, the CEO still made the decisions. The AI just made those decisions faster and more informed. That’s really the trick to building trust. You let the AI contribute, but you don’t hand over the steering wheel. It’s not there to replace judgment, it’s there to make good judgment easier.2 points
-
The roots of an organization lie in its culture. To stay competitive, be the innovator and the go-to market brand, organization transformation is needed at a cultural level. For an organization to have this transformation journey, AI can be one of the trusted partner only if used judiciously. Let us debate this with an example. To promote organization wide learning and development, upskilling and efficiency improvement, from a strategy point of view an organization invested on an AI solution. Every month AI report was shared which gave visibility on number of training hours spent at Department level. Say we have Department A with 40 hrs and Department B with 240 hrs. It was but obvious that Department B got recognized. This was misleading as Department A had 5 team members with an average of 8 hrs per spent on training per member whereas Department B had 120 team members with an average training hrs of 2 per member. The feedback was given to the involved stakeholders and right behaviors were promoted. AI workflows were rebuilt to trigger training modules as per Department needs and dashboard was re-aligned to report correct metrics. This was possible because leadership had the visibility to the dashboards and timely actions were taken to make the AI platform more interactive and enabled the organization to promote a learning culture. An average 2hrs of training spent per member moved to an average 8 hrs of training per member within 6months.This also contributed to employee engagement and continual improvement initiatives. For AI to be the trusted advisor for leaders, recommending following steps to be taken by leadership - Creation of Core team - Before onboarding the AI journey, it is crucial to have the buy in and alignment of all key stakeholders. Create core cross functional team having leaders representing domain, business and technical expertise. Strategic Initiative - Leaders are the influencers for setting the strategy. Leaders need to communicate the need and the objective for adoption and adaptation. Corporate to sponsor the strategic initiative. Go big bang with communication. Set the tone at the top. AI goals, KPIs , resources, etc. AI tools to be part of the short-term Annual Business Plan and long term 5-year strategy roadmap. AI awareness – Educate leaders on what AI is and make them aware of its limitation. Leaders to be mindful and cognitive to overcome biases related to cost, technology and speed. Message from leaders to team to maintain ethics and transparency. Building capability – One of the key reasons why AI can be the trusted advisor is for the speed of data availability, accuracy, reliability and faster decision making. Core team to explore and build AI solutions that would meet the business objectives. Core team to involve domain and technical expertise for bias in and bias out checks. Few key criteria’s for evaluation could be Cost, Quality, Risk of failures, Flexibility – Scalability, Processing Time, Implementation speed, data collection, processing, storage capability and ROI. Proof Of Concept - Create prototypes, use cases, assess opportunity, prioritize and validate, design, build, test and deliver. Course correct if needed. Calibrate, train and update knowledge repository. Roll out the solution. Communicate – Address myth that AI is people reduction method and promote it as value creation to customers and business. Send organization wide communication when milestones) are achieved. Share failure and success stories. Capture lesson learnt and submit solution in Knowledge repository. Governance and oversight – Management to have periodic governance. Reinforce ethical adoption of AI and compliance to data security and privacy and role based access to daily dashboards for better monitoring and oversight. Reward & Recognize – To promote and encourage continual improvement celebrate achievements and reward all those involved in making and leading the transformation. AI thus can be the trusted advisor for leadership if adopted in spirit and maintaining integrity and business ethics at the root level.2 points
-
Great answers from all respondents. The best answer has been provided by Pavitra Jain. Well done. Answer from Swapnil is also a must read.2 points
-
Q. Bais in, Bais Out: How to break the cycle? Answer - In a service delivery context given example of prioritizing cases, recommending actions and responding to customers, following steps can be take at various stages of solution development – Design stage – · Assess project objective, scope, metrics and success measures with timelines · Reach out to stakeholders incase of difference of opinion. · Interview and empathize the issues faced · Brainstorm and validate assessment criteria.Design FMEA · Course correct metrics and success measures if required · Involve Developers, testers in the kick off call Testing phase – · Develop use test cases. · Build Agentic AI workflow with what-if scenarios, And OR logic · Link knowledge base repository with correct calibrated clean database Monitoring phase – · Intelligent dashboards with powerapps workflow when any shift in data is observed · Calibrate and retraining AI for precision and accuracy. · Periodic governance This is how one can let the Bias IN and then Bias it Out through careful design, testing and monitoring to break the cycle.2 points
-
The Process that I would elaorate on would be the Loan origination / Management system that encompass the interaction of the system with below players . Either the solution is a black box to them or it is transparent and up to what extent they can can draw the line of explainability and simplicity . The key stakeholders involved included 1. the applicant , 2. the loan officer / Manager processing the loan. 3. Underwriter who is there as a second line of verifier The AI agent in below process touch point at key stages where decision and assessment are done. 1. The Applicant interaction with the AI agent A way to avoid long waiting time in branches to get serve for a loan request is to use the AI agent via the available channel put in place by the bank which could be via mobile or on the website. In terms of Transparency and simplicity, the applicant interacts with the chatbot and ask queries that he /she would have ask the branch staff in order to take a decision. The system will keep the response simple for the applicant to understand it in a layman terms. For the applicant given that they will not get all the analysis done in detail, it is like a blackbox to them on the decision taken, In the event it is a positive response to their request for a loan its fine , but when it gets rejected , then rational behind the rejection is not clear to them 2. The branch staff retrieving the details of the applicant For the branch staff , it implies the degree of interaction with the system , how knowledgeable they are with the AI agent . the front lines normally are all the time taken up with many tasks at the same time and they take the output and analysis of the system since they just want to get a quick answer and move it to the next level which is the underwriting team, This is where the gap prevails and the applicant and the branch staff are not able to have a clear conversation on the outcome of the request 3. The underwriter second layer of verification The system will come up with the eligibility of the applicant and will have some keys parameters set by the bank to filter good or bad customers who can be eligible for a loan In reality there are certain events that can allow for a leap way for an applicant to get the loan approved which the AI agent will reject based on the information provided on its configuration. The underwriting team have the in & out of the criteria to accepts and put forward to the committee for approval. These information does not go back to the branch people or event to the applicant as it can be taken as a given for most of the reject cases. Thus the balance of ex explainability and simplicity is vital to make it succesful and workable for the bank and the applicant As a conclusion , the system helps to moderate the expectation of all the key stakeholders involved in the process, but should not be the sole reason to take the final decision. The bank has to play the role of the good cop and bad cop as and when required
 2 points
2 points -
I believe that show transparent the agent should be depends on the needs of the user and the context as well. If the context is pretty simple, like recommending content, drafting a message, then a short rationale should be enough because as mentioned "sometimes users just want the answer quickly". However, in more crucial cases, such as healthcare, finances, business, etc - the agent or system should provide more reasoning and detailed audit trail (if required) to secure trust.2 points
-
How transparent ? I think is a grey area question. Can AI be transparent on logic used behind providing solutions ? The answer is Yes and No. The answer is as simple as the prompt provided and resources provided by user and as complex as are we providing a knowledge base and references to AI or sending AI on a goose chase on open internet. The transparency of AI agents depends upon what are we providing it as an input. At my place of work: banking customer service domain where decisions can significantly impact a customer's financial life, AI transparency is not just a nice-to-have — it's crucial. We can look at it from three different perspectives. Depending on the level of complexity we have build an AI agent in a customer service environment. If it is low risk and low stakes or high risk and high stakes. AI Transparency in Low Stake Transactions: · Short rationale: A brief explanation like “Based on your credit score and income, you're eligible for a lower interest rate.” · Confidence score: medium, but helpful to show how certain the AI is. Why: Customers want quick answers but appreciate knowing why they got a certain suggestion, so when we provide a rationale that because of your low credit score this is the best interest rate you can get. It satisfies the customer’s query. Why is this low stake? Because it is just an information and customer might not be loosing anything monetarily. AI Transparency in medium risk and Medium-Stakes Interactions (e.g., loan pre-approval, document verification) · Steps of rationale: what can be shared : Outline key factors considered (e.g., income, employment history, credit utilization). · Audit trail: Since this info is internally logged for compliance and review, not necessarily shown to the user. Why: Customers may want to contest or understand decisions, and regulators may require traceability. For e.g. if a home loan application gets rejected or rate of interest changes upon careful review of applicants credit history, customers will definitely seek explanations. The AI agent build might not provide the rationale behind the decision taken since it is based on a lot of internal criteria and due diligence by specific branch managers. Now if we consider a AI agent transparency in High Risk and High-Stakes Transactions or Interactions (e.g., loan rejection, fraud detection, dispute resolution) · A more detailed explanation is necessary: A clear, legible reasoning with references to policy or thresholds is necessary so that the customers get a complete picture of why a certain decision was taken, what is the basis. · Audit trail: It should be available for internal review & regulatory compliance. · Confidence score: Important to show uncertainty or borderline cases. Why: These decisions directly impact customer’s financial status, morale and can cause frustration or financial harm, so trust and fairness are critical. AI needs to be fair and transparent when the stakes are high. How to Balance Explanations and Simplicity Draw the line based on user intent and impact: If the customer is just browsing for options, keep it simple. If the customer is making a decision or facing a rejection, offer layered transparency — start simple, but allow deeper insights on request. We should lead with a progressive disclosure: Display short rationale first. Offer the customer, a “Why was this decision made?” button for more details. We can also give downloadable audit logs or summaries for compliance officers or advanced users. Golden Nugget Mining : Now what are some best Practices for AI Transparency in Banking We should use simple language: Avoid technical jargon when explaining decisions. Be open and consistent: If the customers with similar queries fall under same criteria, ensure similar cases have similar explanations. Opportunity of a VOC : Let customers contest, provide feedback or ask for clarification. Comply with regulations: Align with GDPR, RBI, or other local financial regulations on automated decision-making.2 points
-
Below is how I will manage versions of AI flows and prompts in a claims processing scenario, where things are constantly evolving based on feedback from claim examiners, auditors, and compliance. 1. Keep Track of Changes While building claims-processing AI assistant, the prompt that guided the “claims eligibility check” step worked… but only for the first few weeks. Then, business rules changed, compliance flagged some outputs, and examiners started giving us feedback. Instead of editing the prompt and hoping for the best, I store every single version of my flows and prompts in a company GIT repository Each branch is new iteration — for example, feature-improve-prior-auth-check. I clearly document why I made the change: When I deploy a new version, I tag it in GIT and log that version ID in our monitoring dashboard, so when a claim examiner says, “The bot did not process a specific scenario,” I can instantly see which version they were using. 2. Documenting the Story Behind the Change Clearly document story behind the change in order to delineate why I made that particular change v2.1.2 — 2025-08-15 Change: Updated “denial reason explanation” prompt to include ICD-10 lookup when code not in local cache. Why: Several claim examiners escalated cases because the bot said “code not found,” even though it existed in the database. Expected Impact: Reduce “code not found” errors by 20%. This makes it easy for me to tell the story of the bot’s improvement over time 3. Testing Before I Roll Out I never just push changes live. In claims processing, one wrong rule application can delay thousands of claims. Below are few things I follow Shadow Testing: I run the old and new prompts side-by-side on 100 recent real claims (with PHI data masked). Regression Suite: I maintain a set of tricky test cases — like coordination-of-benefits disputes or secondary insurance retro adjustments — to make sure the new version doesn’t break things that used to work. SME Review: I share sample outputs with our senior claim SME for human- in loop- scoring. They tell me if the new explanation is actually clearer or just longer. 4. Metrics tracking and feedback from team After Deployment Once the new version goes live (usually to 10% of examiners first), I: Track auto-adjudication accuracy — if it dips, I know something’s off. Collect feedback tied to the exact version. Categorize any errors: prompt misunderstanding, missing data, or wrong business logic. This way, I don’t just hear “the bot is processing incorrectly” — I know why. 5. Protecting Against New Problems I’ve learned the hard way: never delete a working version. I keep the last stable prompt ready so if my experiment tanks, I can roll back in minutes. In claims processing world , the cost of a bad AI update is delayed payments, or regulatory fines or angry providers - un term seriously impact customer satisfaction By treating flows and prompts like living assets with a documented history, I never lose track of why something changed, and I can always prove whether the change actually helped. It’s not just version control — it’s trust control.2 points
-
AI Management System is a structured framework used to govern the development, deployment, operation, monitoring, and continual improvement of artificial intelligence systems in an ethical, safe, and efficient manner. It ensure alignment on organization’s goal, regulatory requirements, and social values. Similar with other management systems, one of its key elements is Policies & Standards. This element pertains to documentation of existing AI workflow, prompt improvement, and version control for any changes made. It is strongly recommended that any organization engaged in AI solutions be certified in AI Management System.2 points
-
At the bank we have a clearly defined handing over process when a solution is deployed. From the development to the User testing and approval to deploy in Production. The Application team together with the Project Manager ensure that a proper handling over milestone as part of the project closure is done when the Application is handed over to business. In the project framework, when the project closure is done proper documentations are provided and most of the time, the application owner is the key stakeholder owning the application post-deployment. For example, we have recently deployed a self-onboarding application using AI. This allows the customer to initiate the process without having to go to a branch and wait in the queue to get served. Below process map depicts the different stages where AI facilitates the interaction with customer without the bank having to allocate additional resources to assist the customer. The following key components are documented as part of the hand over which happen when the solution is stabilised and working fine. 1. Technical Documentation 2. Operational Documentation 3. User Manual 4. Train the Trainer ( Champion ) 5. Performance and Monitoring 6. Governance and ownership 7. Change Request 8. Compliance and data protection policy 1. Technical Documentation The Technical team will prepare the release documents which will includes the rational behind the design and architecture of the application. Data sourcing , regular updates and what third party tools used to transform raw data will be included as part of the documentation Setting up of the different environments like the Production /Disaster Recovery/ User acceptance testing , all these environment will be needed to maintain a long term stability of the application. All these information will be useful for Audit review purpose. 2. Operational Documentation Deployment plan and rollout plan will give and overview of how it was deployed and how it can be roll back in case of malfunction of the system . Configuration set up and access rights given to which roles are important facts to allow for future references in the event of troubleshooting . 3. User Manual Both Technical and Functional documentations are required as part of the handover. This helps for a better understanding of the functionality of the system and limitations. The input required from business side in terms of mandatory fields and what should be the output are mapped in these manuals . Well defined guidelines are published in order to maximise on the usage and its potentials and just the solution can keep its effectiveness in the process. 4. Train the trainer ( Champion concept) With the deployment of the solution, it is important to have workshops and training done with both , the technical and functional users. This is done to showcast the capabilities of the system.Identifying champions in each key departments allow to form users as subject matter experts, these people will be the L1 support for assistance to queries from users and customers. Building up FAQs and feed the AI solution allow the customer to interact with a chatbot for basic level of request and queries 5. Performance Tracking and Monitoring Clearly defined Performance Metrics and Key performance indicators (KPIs) meticulously agreed upon during the development phase set as a baseline metrics for future performance evaluations. We do have Monitoring Dashboards which provide valuable insights into the system performance and complemented by Red Flag alert mechanisms in the event of significant performance degradation, data drift, or service interruptions. . 6. Governance and Ownership As part of the handling over of the solution , the different roles and responsibilities need to be properly defined which ensure continuity and scalability. The following key stakeholders need to fulfil their part of the process. • Product Owner that ensure overall business alignment and budget management with organizational goals. • Technical Owner that ensure regular ongoing maintenance of the infrastructure and implementation of critical updates. • Data Owner that ensure the accuracy, integrity, and availability of data necessary for the AI system's operations. • Support Team which is a dedicated group tasked with addressing user inquiries and providing solutions to minor issues, fostering a smooth user experience. • Escalation matrix which is important and clearly mapped out procedure for escalating issues, ranging from operational glitches to critical model performance challenges, along with designated contacts for first-line, second-line, and third-line support. 7. Change Management Every changes requested by business need to go for proper approval process in order to maintain a consistency in the modus operandi of the solution . The changes should go through the Change Management process which follows ITIL framework. 8. Compliance and Ethical Considerations Data Privacy Detailed documentation outlining the methods used to handle personal or sensitive data, including robust practices for anonymization or encryption to protect user privacy is critical to the success of the deployment . All the above checkpoints are done in order to maintain clarity and completeness of the solution deployed,
 2 points
2 points -
It is crucial to provide ongoing feedback to AI agents so that they can learn from the to keep providing updated information. Let us assume that we have an AI agent that converts legacy code to a cloud-native language during system migration. We would need a feedback loop to be as structured and domain-aware as the migration process itself. Below are some techniques to collect, interpret and act on real-world feedback (from users, supervisors, or performance data) to continuously improve the agent : - 1. Feedback Collection – a) Developers reviewing AI converted code can flag code blocks with recurring issues like syntax errors, performance issues or deviation from architectural guidelines. b) AI generated report that shows the confidence score for each converted code. c) Track time required for manual remediation of AI-converted code and post deployment deployment metrics like execution time, resource consumption of running migrated code in cloud environment. d) Testers and Migration leads can keep track of the recurring issues and statistics around it. 2. Feedback Interpretation – a. classify feedback into types — syntax/compilation, semantic mismatch, security compliance gap etc. b. Consolidate issues to identify patterns in migration c. Compare AI generated report ion confidence score vs the reviews conducted by developers, testers and migration leads 3. Act on the Feedback – a. Fine tune model based on frequently occurring error patterns b. Update prompt templates and transformation rules with explicit project-specific coding standards (naming, architecture patterns, security requirements While it is important to optimize the performance and outcome of the AI agent, we can prevent overloading by manual resolution of minor formatting issues , or instead of reviewing every conversion, we can prioritize low-confidence or high-complexity conversions. Thus the agent will not only convert code but also learn from every migration cycle with feedback loop designed to catch errors, preserve best practices to evolving cloud practices.2 points
-
It's hard and sensitive for a financial services organization to deal with customer complaints, hence an AI agent is quite crucial. This is a very serious situation that needs to be dealt with in a careful, polite, and lawful way. This is a planned way to help an AI agent perform the appropriate thing in these kinds of situations: Chosen Process: How to Handle Customer Complaints in the Financial Services Sector Why it's hard and important: Customers have a lot of varied feelings. The SEC, FINRA, and GDPR are all laws and rules. Needs to know what's going on, such how the client has talked in the past. You need to do a couple things: find out what the problem is, talk about it, and then fix it. How to Keep AI Working and Running 1. Getting the prompt ready: How to Keep the Agent in Place Using the Role and Intent Method: At the start of the meeting, let the agent know what the tone and goal are. "You are an AI that helps people with their problems." Your main goals are to be clear, understand, be right, and, if you need to, move higher. Don't make any assumptions. Every time, read crucial items twice. Effect: This way of looking at things makes the agent immediately ready to be careful and pay attention to the user. 2. Flow Limits: How to Keep the Agent on the Right Path Divide the procedure into smaller steps, each with its own rules: Acknowledge: Be sure you understand what the issue is. Clarify: Use fixed dimensions like date, transaction ID, and client effect to get information. Putting things into groups, such urgent, legal, and technical, is called triage. Route: Either fix the problem or move it up. You can do this by utilizing logic flags and modifying the state between modules. Don't go forward until all of the important inputs are locked. For example, if the complaint isn't clear, stop what you're doing right now. 3. Checkpoints: Things to Do to Make Sure the Built-In Method Is Right: Add checkpoints before doing something important to make sure it's right. "To be clear, you're talking about a $1,200 charge that was questioned on June 3, 2025." Is that actually true? Effect: It makes it less likely that there will be a misunderstanding and makes sure that the AI and the user agree on the facts. 4. Questions to help you understand: Questions that are proactive and take the situation into account Instead of asking, "What went wrong?" try saying: "Please tell me what happened right before the problem." "Have you tried to fix it yet?" Use templates that match the type of complaint for follow-ups that are specific to the location. 5. Dealing with red flags: things that make you feel awful and make things worse. How to do it: Teach AI how to look for signs that things are becoming worse, like A lot of thoughts like "I'm so mad" and "This isn't right." There are words like "lawsuit" and "compliance" in the law. What to say: "I know this is really annoying," therefore you should know how people feel. The human escalation workflow should start on its own when certain conditions are met. 6. Things you can't know: How to Stop Giving Out Too Much Information: Use short response templates and seek for help if you need it. "I wrote this down for the people on our team who make sure we follow the rules." They will get back to you in a day. "This happened because it was hard to compare data from different countries..." Control: Based on how serious the complaint is, choose how many tokens and how much information to supply. 7. Things that help you recall and go over short sessions Check the facts every now and again to stay on track: "Here's what I've come up with so far: 1) They charged too much on June 3; 2) They haven't answered my support request since then; 3) I'm asking for a refund and an apology. Pro: It keeps both sides on the same page and makes it easier for conversations with more than one turn to go well. What happens in real life Checkpoints and modular flow make sure that things don't happen again or go in loops, which helps things run more smoothly. Boundaries help you stay on the right side of the law and make it easier to go forward. Using prompts and summaries that take tone into account indicates that you care about your users and know what you're doing. Conclusion AI agents can deal with tough situations rather effectively, but only if the interface is good. Usage of prompt-framing based on role-based, progressive flow control and empathy related checkpoints all together results in organized process but yet focused on customer/person. This enables the business to run smoothly with people on track with low risk and trust.2 points
-
This response is a summary that fits the requirements: The ESG Risk Assessment of the Investment Analysis Process and Decision Making indicates that more and more organizations in the financial services industry are utilizing AI models to help them with challenges that have to do with the environment, society, and governance. They gather and organize a lot of unstructured data from other people, like news stories, company reports, and ESG evaluations. These AI-generated summaries could assist analysts figure out how to score companies on crucial ESG parameters and what risks they might face. They can also explain their clients where the data came from, how it wasBN was collected, and what it was used for. People often write down the ESG problems that a company has had to deal with in the past year. Next, consider about how these kinds of worries could make investing more dangerous. The way a prompt was made affects its reliability, tone, and accuracy. If you don't make a prompt appropriately, it could lead to: You are making a general statement when you say "Company X has environmental problems" without stating what or when. People say that a model is hallucinating when it thinks there are problems that aren't in the data. For instance, if the analyst hears too many accusations, it might influence how they think. You can't tell Company X to "write down all the ESG problems they've had to deal with lately." Things that are wrong: The term "all" makes it sound like everything is there, which the model needs to know. What do you mean when you say "problems"? Are you talking about threats to your reputation, claims, or problems that have been fixed? "From August 2024 to July 2025, write a summary of verifiable ESG controversies about Company X that were reported in credible news sources or regulatory filings." This could be a better suggestion. Please tell us what the claims are, what happened, and how the company responded. Use language that isn't biased to figure out what could go wrong. Why It's Better: If you write down what sort of source it is and when it happened, it will be easier to grasp. It asks for proof at different levels, which makes it more reliable. Shows how to change the tone of a summary to make it sound less terrifying or unfair. Being useful and imaginative This modification is in line with what people in the real world need since people who work in finance need to be able to make fair decisions based on facts. People won't have to guess or deceive if they know what the risks are. You can also use the same prompt templates for more than one ESG concern, such ignoring labor standards or scandals in governance, or for multiple types of inquiry, like looking at ESG ratings. This suggests that it can grow and compare information. You can also use the same prompt templates for more than one ESG issue, such scandals in governance or labor breaches, or for different sorts of research, like putting ESG ratings next to each other. This indicates it can get bigger.2 points
-
Using myself as a practical example pre my knowledge of prompt engineering and my use of ChatGPT, I have used AI to write content scripts, respond to emails, draft the flow of strategy sessions for a business leader's workshop, design SOPs, training modules, and presentation scripts in a global manufacturing context. I can tell for a fact that the results I have gotten post my knowledge of prompt engineering and design shows how prompt design can elevate or limit the outcome. My initial prompts was something like "Create an SOP for the Logistics team" or "What caused Line 2's downtime yesterday" but has now evolved into "on yesterday’s downtime on Line 2, using available sensor logs, operator notes, and maintenance history, identify the most probable root causes and suggest low-cost, high-impact fixes relevant to skincare batch making process" or "Create a logistics SOP for a skincare manufacturing plant in Nigeria, including job grade responsibilities, escalation paths, tool access levels, and cross-functional dependencies.” I think the prompts given to an AI model is critical because it determines whether the output is surface-level or genuinely actionable and within the context of the problem you are trying to solve. The improvement didn’t just help me get better results; it helped the AI model understand my context more deeply. In other words, better prompts led to smarter AI support which in turn leads to better decision making.2 points
-
The Bank has a Complaint Desk, comprising of a Complaint Officer and a Coordinator, working under Retail unit and reporting to Head of Retail. This is a unit that has lots of manual steps in its process and involvement of multiple staff within the bank whereby the collaboration of Human and AI is a must. The process starts from the different channels that the bank has , where it can register complaints or a request from the customer via 1. Face to face by customer 2. Through phone 3. Through email 4. Website 5. Letters / Suggestion Box The nature of the request can come in the form of a query or a complaint and this is where there is a filtering done by the person acknowledging the request in order to decide on its nature : 1. Inquire on type of complaint. 2. If query; 2.1 liaise with staff /department concerned. 2.2 To respond to client immediately and resolve issue. 3. If it is a complaint, 3.1 To ask client to sign a complaint form 3.2 Inquire on the issue, root cause, details from branch staff concerned or relevant department. 3.3 Escalate to Complaint desk by email under copy to Head of Retail. 4. Issue letter to client upon advice from Complaint desk 5. Log on LDC in case any operational loss 6. Prepare paper for approving authority in case of any refund to client. 7. Send letter to HOR for 2nd signature. Each department or unit has its own way of handling the request or complaint in the following way: 1.1 SME Level 1. If it is a complaint, 3.1 Received by RM, he/she shall handle the client & resolve the issue 3.2 If issue not resolved, log on to complaint ticketing system IN most of the cases, complaints are received through mails or website. Based on the fact it is an administrative activity, IT operator channels these request to Complaint desk, who in turn sends mail to SME unit for inquiry. 1.2 Corporate Level 1. Once a Query/complaint is received at the unit, same is sent to HOD. 2. HOD sends to the respective RM looking after the portfolio of clients for whom the query/complaint was received. 3. Matter is tackled at RM level after consultation either within the department or with any other department concerned with the case and HOD is copied/informed of all steps/progress. 4. Copies of the correspondences pertaining to the complaint are kept in file. 1.3 SAM Level 1. Most of the time Complaints desk channels complaints to SAM 2. HOD SAM refer the complaint to the RM in SAM handling the file. 3. RM calls client & tries to resolve the issue. 4. If unresolved, escalate to HOD 5. HOD tries to resolve the issue, talk to client 6. Letter is sent to client 7. Update Complaint desk Ultimately all request or complaints are channeled to the complaints unit and the internal process requires lots of follow up to ensure prompt response to the customer 1. Upon receipt of complaint, the details of the complaint is log on an excel format. 2. Then Identify whether it is a query or complaint. 3. Inquire & follow up with respective business unit 4. If matter resolved, update the excel 5. If unresolved, escalate to senior management 6. Prepare letter to customer 7. Prepare reports for Complaint forum (Compliance) 8. In case of any compensation, give assistance to Business unit to prepare paper for approval. 9. Prepare reply letters to regulator for cases reported by them 10. And report submission on a monthly or quarterly basis. In all the above units , either the RM/HOD/Complaints officer and Complaints coordinator are involved in handling the request of the customer. If AI has to be introduced to this process , then the following changes will happen in the process and certain activities within the roles of the front liners will be changed or eliminated. Nowadays the use of mobile and website are more adapted to the trend of live of people. And more and more people make use of these means to send their request With the introduction of AI, The activities at the initial stage which determine whether this is a complaint or a query can be handle by AI just by feeding in some parameters for the system to be able to channel the request to the appropriate stakeholder Also the frontliners like the branch staff will not have to attend to this tasks of sending this to the department or stakeholder concerned and do a follow up By providing some filters at time of input by the customer can already save the bank time and resources to complete this task. On top of it also , due to regulatory requirement, the bank has to acknowledge the request or complaint from the customer within a minimum delay. Which at time if done by human , this can be omitted or done outside the SLA The recording and tracking of the request or complaint will be done by the AI without anyone having to log the record on the system . This also reduced the tasks of both the officer and supervisor who are involved in the creation , verification and allocation of the ticket. On the reporting part , whereby the bank has to send a report to the regulator on a monthly or quarterly basis, this can be handle by the system through AI. In a nutshell the collaboration of Human and AI works smoothly in this scenario, since some optimization of the existing process was done to eliminate manual intervention as far as possible through AI , thus allowing the different players in the process to have more time to spend with the customers. For this process, the roles of the different stakeholders might not change drastically, it might be that some training to the OLD school ageing staff is needed, since they will have to adapt to the new process in collaboration with some of the steps being done by AI instead of Human.2 points
-
As a part of the Business and process Excellence team’s across different organizations I have been involved in numerous projects involving process optimization and implementation of RPA’s. Having managed omni-channel contact centers, I have closely worked on implementations of ACD’s (automatic call distribution) and Autonomous IVR's for telephony set-ups. And have been fortunate to be a part of Live Chat implementation projects involving Chatbots in recent years. With the expansive capabilities of AI, what we had set out to implement was an interactive, self-learning, autonomous “Dynamic Packaging Module-DPM” for an OTA’s Holidays business. The idea was to integrate the DPM and Chatbot on the site, which would be able to handle Customer Inquiries related to the packages involving mostly customizations and any related questions to T&C’s, payments, offers, amendments and cancellations, upgrades, visa, insurance etc. immediately. Given, the fact that 60% of the inquiries were for “Customized Packages” it was important for our teams to be able to handle such customers by offering complete details “tailored” to their requirement in the First Interaction itself thereby improving conversions and customer experience, hence the decision to go ahead with the project. So, in addition, to building a Backend Product loading and managing tool involving the integrations of supplier API’s, Direct / Extranet contracts, GDS and Airline feeds, offline packages, ground transportation and ancillary services. We needed a Front end, which allowed both our teams and the End customers to be able to “Customize packages” as per their needs on real-time basis, while making use of the AI assistant. And finally, all interactions, requests, quotations to flow into the CRM and ERP tool for overall booking management, human agent and AI model training and retraining, Quality Audits using AI for all interaction summaries. The Front-end or the “DPM” was built using AI/ML algorithms, using on-premises LLM’s, which were trained on some 100,000+ itineraries for countries across the world. The AI QA tool had been trained on Sales scripts, product knowledge, soft skills and Quality monitoring sheets to score conversations. Both these tools had their respective KB’s. Let’s look at the project implementation in terms of restructuring of processes, new roles and responsibilities both for Human agents and the AI, handoff protocols laid down, Human-AI Collaboration framework and efforts, Phase-wise implementation plan, Training requirements for the team and Revised KPI’s. AI-Integrated Sales Process for Holiday Package OTA Revised Process Flow - Initial Customer Contact • The AI chatbot initiates the first interaction within 15 seconds of a customer visiting a Landing or Package page, offering assistance to “Customize a package” or offer the “off-the-shelf products”. • The AI qualifies the lead by gathering destination preference, departure city, travel dates, trip duration, no. of persons traveling, travel intent – couple, family, honeymoon etc. and budget, if any. • By using set parameters, the AI assesses the complexity of the inquiry. • Basis the complexity scores the system directs the next steps for the handling of the query. - Queries Handled by AI (70% of initial contacts) • Inquiries regarding package availability and pricing • Standard booking changes (dates, passenger details) • FAQ’s bout policies (cancellation, baggage, visa requirements) • Basic information on destinations and weather • Payment and confirmation support details • Post booking status updates and reminders - Human Agent Involvement (30% of initial contacts) • Multi-city itineraries that require customizations • Group bookings for 10 or more people • Special requests incl. accessibility, special medical needs, meals etc • Managing refunds that involve exceptional circumstances or exceed standard refund policies • Catering to High-value bookings above $X,XXX per person • Handling customer escalations or requests where customers explicitly ask for human assistance Evolution of Human Agents: From being Order Takers to Travel Consultants The agents are now responsible for offering strategic travel advice, instead of just processing standard transactions. While focusing on customer motivations, recommending upgrades, and creating WOW experiences, the agents now act as Travel Curators. - New Core Responsibilities of Human Agents • Curating complex itineraries involving multi-city routings • Developing long-lasting relationships with HNI and repeat customers • Promoting and upselling premium experiences and services • Handling sensitive customer service-related issues • Ensuring the quality of AI recommendations by regularly Auditing conversations • Training the AI system through feedback and updating information in AI KB for retraining AI – Human Handoff Protocols • Full conversation history and customer profile to be provided by AI to the agent with a ‘Warm transfer process’ to be followed. • The system marks the ‘Priority’ to define the urgency of the inquiry and provides the previous interaction sentiment. • AI provides recommendation to the agent on the suggested action items based on customer type. • AI to ensure customers don’t have to repeat themselves through smooth context transfer to the human agent. • Handoff scenarios include – Complex itinerary requests, emotional or sensitive situations, HNI customers, technical issues or complications. Collaboration Framework b/w AI-Human AI support by Human Agents - AI training and feedback • Agents flagging incorrect AI responses through live monitoring and post-chat audits. • Updating new product knowledge directly into AI KB. • Creating templates for recurring complex scenarios. - Quality Assurance and Risk management • Reviewing AI conversation transcripts on regular basis for accuracy. • Providing feedback for adjusting AI tone and persona. • Identifying and recommending cultural nuances for regional and international customers, which AI might miss. • Ensuring AI responses comply with industry regulations, company policies and meets customer privacy standards. - Data enhancement • Tagging successful booking and upselling conversations for AI learning. • Provide inputs on travel seasons (peak, off-season, shoulder) and booking patterns for AI to incorporate. • Highlighting objection handling patterns to assist with AI’s response improvement. • Providing SWOT analysis against competitors for improving AI pricing algorithms. • Regularly calibrating to improve AI response accuracy. Real-Time AI Support for Agents - Dynamic Sales Assistance • Recommending agents with relevant packages during live conversations. • Alerting agents of any ongoing flash sales or inventory updates mid-conversation. • Offering real-time access to competitor pricing during conversations. • Identifying and recommending potential upsell opportunities based on customer profile and sentiment analysis. • Offering alternatives in case the customer rejects the initial recommendation. • Providing real-time destination specific expertise when agents handle requests for unfamiliar destinations. - Quality and Administrative Task Automation • 100% QA of customer conversations. • Monitoring conversation sentiments and raising flags when necessary. • Identifying knowledge gaps and recommending relevant training’s. • Summarizing of customer conversations and updating CRM records. • Scheduling follow-up emails, callback reminders based on the conversation and commitments made by the agents. - Booking flow optimization • Automating mailers to customers with booking and document checklist. • Pre-filling of booking forms with customer data received during query and quotation stage. • Validating Customer’s travel documents for their visa, immigration and validity requirements, ticketing and booking confirmations etc. and alerting agents for any identified issues. • Generating the payment and cancellation schedules basis booking and travel dates • Populating instalment and discount offers recommendations. - Performance Optimization • Tracking conversion rates by agents and recommending relevant trainings for improvement. • Sharing insights into best practices and successful sales patterns. • Recommending staffing for aligning Work force according to peak intervals. • Tracking C-SAT Scores depending on the type of interaction and customer feedback. Gradual Phase-Wise Implementation Strategy • Phase 1: AI manages only basic FAQs and availability checks. • Phase 2: Introducing booking processing and payment handling. • Phase 3: Adding multi-city, complex package bundling and recommendation algorithms. • Phase 4: Achieving the complete integration with personalization features. Training Requirements for Agents • Tech skills for navigating through the AI systems. • Advanced consultative selling techniques training. • Training on cultural sensitivity for regional and international markets – New markets. • Advanced CX training for crisis management and de-escalation techniques. Introducing a Dual layer of KPI’s - AI KPI’s • Response time – Less than 5 seconds for 95%. • Deflection rate – 75% or more of routine inquiries handled by AI. • Accuracy rate – 95% correct information provided for each interaction. • Conversion% - Glide path targets for the first 06 months starting from 05% to 10%. • Availability – 99% uptime during business hours. • Handoff efficiency – 95% of AI to human transfers happen without customer repeating themselves or getting frustrated. • C-SAT scores - Above 4.25 out of 5. • Average order value – Increase in AOV’s by 15% MoM. - Agents KPI’s • Complex booking conversions% - Glide path targets for the first 06 months starting from 15% to 30%. • Up sales % - 30% of the bookings converted accept upgrades. • Customer Lifetime Value / Repeat customers - 30% increase in customer retention for agent handled customers. • Handoff efficiency – 90% of the AI transferred interactions to be resolved within first agent interaction. • Escalation resolution – 95% of the complaints to be resolved within 48-72 hours • AI training and feedback contribution – Achieving weekly and monthly contributions targets towards AI improvement and training. • C-SAT scores - Above 4.5 out of 5 Following an integrated approach, we were able to transition from a transactional to a consultative sales process. While AI handled the maximum volume and routine tasks, this allowed the human agents to focus on building relationships and solving complex problems. As a result, we were able to see faster response times, improved CX, and increased revenue per booking.2 points
-
2 pointsThe Swiss Cheese model is a risk analysis and management model developed by James Reason. The model illustrates how accidents or failures can occur due to a combination of various factors. Think of a stack of Swiss cheese slices with the slices representing layers of defence, such as safety procedures, training or system design within a process or an organisation, and the holes representing the potential weaknesses or failure points in those defences such as human errors, system malfunction or a procedural flaw. In isolation, the holes may not create an issue; however, when they line up, they create a clear path for failure. Used in various industries such as healthcare, aviation, engineering, etc., the model helps 1. Analyse past accidents and identify areas for improvement. 2. Spot individual failures as well as systemic vulnerabilities 3. Understand that a single safeguard is never enough 4. Focus not only on adding additional layers, but also improving the quality of the existing ones (i.e. shrinking the holes) In my organizational processes, the cheese slices or the layers of defense are, 1. Process Documentation - Standard Operating Procedures for clarity on what needs to be done and how. 2. Technology and Tools - CRM, project trackers, automated reporting. 3. People Structures – Skilled team members and role clarity. 4. Audits & Reviews -Regular Check-ins, internal audits and client feedback loops 5. Training & Capability Building - Internal or external training programs, onboarding procedures, or process trainings. 6. Governance Frameworks - Approval systems, decision rights or escalation ladders And the holes i.e. the weak spots are, 1. Process Documentation: Outdated or poorly communicated procedures 2. Technology & Tools: Incorrectly implemented or data not updated 3. People: Poor Delegation, lack of ownership or unclear roles 4. Training: Theoretical but no practical implementation, old training systems or irrelevant modules 5. Governance - Micromanagement, or too much red tape, or unclear escalation If the holes line up, there can be client delivery issues, missed deadlines, and miscommunication, leading to business losses. However, by using Business Excellence principles, pitfalls can be avoided, as below, 1. Map your defences – Document all the defence mechanisms in the workflows by assessing where you rely on people, where on technology and where the decision-making is slow. 2. Identify and Prioritize risks – Run a FMEA analysis to spot where the holes might align, which layers are the weakest and which ones overlap. 3. Close the gaps – Use the PDCA, DMAIC to tighten each layer (shrinking the holes) such as, · Improve SOPs - standardise, train, test understanding, periodic reviews · Review CRM or reporting dashboards for data accuracy · Audit the impact of training, not just attendance 4. Design for resilience – Set up redundancy where needed by implementing backup approvers, escalation triggers, or multiple checkpoints so that even if one layer fails, another catches it. 5. Imbibe a culture of prevention – Encouraging teams to look beyond firefighting and ask what hole in our process allowed this to happen, and how can we patch the holes? For Eg: During any transition, · One layer is the communication plan. · Another is the handover process · Third is the data access and permissions · And fourth is internal task tracking If the comms aren’t clear or the handover isn’t fully documented or someone forgets to update access – that’s a failure chain. Final thoughts The Swiss Cheese model helps us see failure as a whole system and not just someone’s screw up. When combined with Business Excellence tools, you not only patch holes but build stronger and smarter slices.2 points
-
Process Context In our fleet size of more than 50 plants, we use SAP IBP as an AI-enabled planning engine for forward spare parts demand planning, replenishment strategies and inventory strategy for all operations and maintenance. We manage roughly 200 Million Euro, 78000 SKUs in inventory. Let me explain what IBP does, It autonomously calculates, recommends replenishment strategies (VB, PD, ND), and planning paraments such as safety stock, Reorder point, and Max stock, using consumption history, PM demand, variability and lead times. Currently, for us, the process already runs with minimal manual interventions. So the real challenge for us is not making AI work, it is ensuring it continues to work as intended over time. How We Prevent Drift While Keeping the Process Autonomous We follow the simple principle, Automation with explicit guardrails. Any IBP recommendation that changes planning parameters for items by more than +/- 30% from the current setting automatically triggers a workflow approval in SAP. Our workflow goes to Planning manager, inventory controller, Final approval from PGM & Myself. We have build a clear summary in approval process, along with raw numbers, it shows number of SKUs impacted, Net Inventory Impact on Max stock (Positive/Negative), Risks. This gives completely details to reviewers, to approve, reject, fine tune recommendations based on the actual business context, In our process AI proposes, humans decide only when risk crosses a defined threshold. What We Monitor To Ensure The Process Stays Healthy We simply monitor the business behaviour & outcomes. If I say very specifically, we look at frequency of parameter changes exceeding the 30% threshold, Repeated SKUs entering the workflow approval, Manual override trend, Inventory vs Service levels, Gap between IBP recommendation & executed parameters. How We Respond When Performance Starts To Slip When we see the drift, we don’t fix the AI engine, we review the decision logic, PFEP. Typically we revalidate the demand classification, Lead time assumptions, ABC calculations. We do the corrections at the policy & logic level, not through the repeated manual intervention. Evidence That This Approach Works Our this structure helped us to optimize around 12000 SKUs, delivering 3 M Euro Inventory reduction, 10 Million Euro Cost Avoidance in a year. Review cycle time has been reduced by 80%. Now process auto approves 70% of recommendations. Bottom Line In my view, AI enabled process stays effective over time not because it is constantly supervised, but because decision rights, thresholds, and escalation rules are designed upfront. We let SAP IBP run high volume, repeatable decisions, while we intervene only when changes signal the real business risk, and then we judge system health by outcomes, not by how often people touch it, this shows the clear example of how autonomy & control coexist with AI delivering the value not drifting the process.1 point
-
Domain: Aerospace, MRO (Maintenance, Repair & Overhaul) - Engine shop for narrow body turbofan engines (€220M turnover facility, covering CFM56, V2500, and LEAP Shop Visits of various airlines and lessors) Specific Improvement Initiative: Reducing engine module Turn Around Time (TAT) from 45 – 60 days to <35 days during performance restoration visits in a span of 6 Months (This effectively represents another high-value chokepoint because releasing underlying store engines into service reduces costly leases and makes airline dispatch more dependable. We recently initiated an AI-driven project in late 2025 that seeks to incorporate predictions of module status using borescope, oil analysis and test cell data, then auto generates work scopes and part forecasts.) How we adapted DMAIC with AI — stage by stage Define This will still remain 100% human owned with no shortcuts. Simply, Artificial Intelligence cannot describe what "good" means for airworthiness parts. For few weeks we worked with airline customers, lessors and regulatory representatives to map CTQ’s: TAT < 35 days, zero escape on critical elements (HPT, HPC), > 12% cost reduction, and full traceability for EASA/FAA. AI also helped in the visualization of the current vs. target Pareto of delays. Boundaries (no compromise in Safety and/or Compliance) remained the responsibility of the MBB and the project sponsor. Measure "AI becomes super strong here — it accelerates data collection and baseline accuracy massively." Rather than manually sampling 200 historic Shop Visits, AI ingested 1800+ data points, including borescope images, oil debris, vibration trend, test cell parameters, etc., and created a clean baseline in a few days: · Avg breakdown TAT: TAT breakdown – disassembly 8d, Inspection 12d, Repair 28d, Assembly/test 12d. · Variation drivers (HPT blade rework 42% of variance) The judgment of humans is still predominant, i.e., validating data quality, excluding outliers resulting from non-standard visits, and checking if there is no survivorship bias present in the data set itself. Analyze This stage roles flip: AI takes the lead on root-cause discovery, humans will challenge and refine it. AI ran pattern recognition across thousands of features · "Predicted that 68% of HPT delays are caused by unexpected coating wear (not visible with a standard borescope). " · Simulated ‘what if’ scenarios (add ultrasonic inspection on blades → TAT -4 days, cost + €8k) etc. MBB owns: · Forcing AI to explain (SHAP values & counterfactuals). · Rejecting Correlations which Violate Physics/Engineering Judgment. · Prioritizing causes with the team (fishbone + AI insights). Improve AI excels in solution generation and testing, whereas piloting decisions fall under human expertise. AI produced 12 different workscope variants, ranked according to their TAT/cost/risk. We tested top 3 on 8 engines: · Added Predictive coating inspection → Reduced Surprise Rework · Auto parts pre-kitting based on AI prediction → Assemble wait time Human judgment prevails: deciding which approved variant will go ‘live’, managing change with technicians and getting sign-off from regulators. Control Human + AI Hybrid With Human ownership of Sustainability. AI Monitors and tracks real-time adherence (daily TAT tracker for deviances). MBB owns: · Control plan update (with new SOPs on the use of AI). · Monitoring adoptions: Technicians' override of AI predictions (<15%). · Monthly review: review of escapes/misses to retrain the model. · Celebrating success with the shop floor (sharing savings made visible) Which of the phases will be made stronger with the use of AI · Measure: 10× faster, more granular baseline · Analyze: reveals patterns not yet perceived by humans · Improve: generates/test thousands of scenarios in hours Where human judgment still needs to dominate? 1. Define: framing value and non-negotiables such as safety, 2. Analyze: rejecting physically impossible correlations. 3. Improve: Piloting real engines, i.e., one can’t simulate customers trust. 4. Control: Sustaining Culture & Accountability Practical result after 7 months · TAT average 33.8 days · Cost per visit down by 14% · No Escapes · Technician satisfaction up (less firefighting, more predictable work) Bottom line from the engine shop DMAIC may not be replaced, but it’s turbocharged! The AI takes care of the hard work on data and simulation, but MBB makes sure the method remains disciplined . right problem definition, right boundaries and right decision. Without humans "owning" Define and "challenging" Analyze, AI is a matter of "optimizing the wrong things faster, With humans owning, you get sustainable, compliant, high value improvement that regulators and customers actually trust.1 point
-
For leaders to trust AI, we need to consider the following concerns : * Can we build an AI agent with not enough data about the case to make tough and timely critical decisions by AI? We expect with limited data to make biased and inappropriate decisions; however, we might be able to build an AI model that mitigates the data shortage issue, but this will be risky. Therefore, it is rather advised to build a selective automated system by keeping the critical decision to the leader, considering the output of the AI agent * What are the possibilities when data is incomplete, or options are conflicting to overlapping, to get a trusted critical decision by an AI agent? There is an opportunity to build an AI agent that works on different techniques to eliminate data shortage and conflicting data, probabilistic reasoning, uncertainty quantification, or contextual analysis. Bases on the nature of the business and criticality of decision; leaders can work on segmenting the decision making approach into three different categories, level one we trust to AI agent to take decision where options are limited and the risk of which is controlled and supervised, level 2 where leaders can delegate the final decision making based on AI agents to reporting managers, and level 3 which is concerned with the real costly decision where tolerance toward errors is almost zero; in this category leader should avoid trust AI agent decisions but still they can consult it * What are the working environment constraints that might limit the correct decision by the AI agent? The level of working environments' complexity plays a critical role in AI agents’ rational decisions, and it is important to consider that there are deterministic and dynamic environments where transparency, social context, and ethical context need to be addressed when we deploy AI agents * How far can the decision taken by AI be in favour of the business goals? Any decision taken by an AI agent should be for sure in favour of the business goals, as this is part of the context and data set the AI agent is using to make decisions; however, “How far" is based on the robustness of the system setup in the business, the Business AI strategy, and proper ethical governance * How long does AI need to be part of the working environment to get the correct sentiment for any required decision? Sentiment is probably the next of AI machine learning, as it requires a bit of complex AI setup, the competencies of data AI is learning from, therefore, in our case, where the data dataset is incomplete and there are conflicting parameters, the sentiment will be biased even if we tried to enhance the dataset's integrity level * Can we build a tailored AI agent to be able to detect the leader's tone in decisions? Technically, it is possible, and this turns out to be an AI digital assistant. This would require sentiment analysis, NLP dedicated to the leader's personal data set. Now, how far will this agent be trusted for a critical decision? It all depends on a healthy relationship between the leader and the agent itself, in which, over time, the leader will be able to decide when to delegate the decision to the agent and when to keep it for himself Conclusion: An AI agent can be considered as an advisor in the case of a critical decision for a leader; however, we need to consider the problems and effects of having incomplete data or conflicting data, and based on that, we shall fine-tune our own ability to trust the AI Agent to make critical decisions1 point
-
In today’s fast paced world where data is in abundance, AI can help scan through the data and provide insights to leaders for effective decision making. However, this approach can be flawed and the recommendations provided by AI agents can be questionable if the underlying data is incomplete or biased or if the recommendations are conflicting. In such cases the AI recommendations must be compared against the prevalent domain context and based on experience decisions need to be taken. Below are a few examples from the software services industry where AI can support decision-making:– 1. Employee Upskilling - AI can analyze employee skill data and project demands to identify gaps and provide recommendations to design learning and development programs. 2. Contracting – AI agents can help to draft contracts and later reviewed by experts, thus reducing the turnaround time 3. Program Implementation – For greenfield projects, AI can help to design the data model, create source to target mappings (STTM), generate code according to the STTM document , generate test data etc. For migration projects as well, AI can help to convert legacy code to cloud native codes, help to assess the legacy landscape, scan through code lineage and help determine a migration plan etc. 4. Data Management – AI can assess source data quality, help in master data management and data governance. 5. Performance Management – AI can help to provide insights about an employee performance by analyzing inputs from status updates in Jira, certificates completed , learning programs attended by the employee , tracking the allocation % in a year and also seeking insights from client feedback. Though AI can provide good insights, but final decisions should be reviewed and approved by Delivery/Account leadership to ensure alignment with organization goals.1 point
-
In Banking service, AI might be used to reply to customer cases based on urgency, value, or predicted outcomes. There is a possibility that the training data is based on historical biases (e.g., favouring certain ethnicity, creed, age or regions). Following are the suggested Steps to Minimize Bias in Design, Testing & Monitoring 1. Design Phase Define fairness criteria: one should define “fairness criteria” Source Diverse data : one should Ensure training data includes a wide range of date that includes representation of all types of variation that exist in real world / population of that universe. 2. Testing Phase Testing for bias: Introduce Use fairness metrics for example disparate impact analysis to test the model Observe scenarios: one should run test cases with all kinds of customer profiles. Human-in-the-loop: Include manual review for flagged decisions. 3. Monitoring Phase Metrics for dashboards: Track prioritization patterns by different customer segment. Continuous Feedback loops: Build a culture where employees and customers can report unfairness. Continuous train the Model: There is still a possibility that some biases infiltrate despite all checks and balance hence it is suggested that one should Periodically retrain models to identify noise and biases.1 point
-
1 pointHi , Hey, There are some cool new AI tools making waves. Here are a few that caught my eye: Pictory – Turns long articles or blogs into short, snappy videos. Super easy to use. Runway – A bit more advanced, but awesome for video editing and creative control with AI features. LunaBloom AI – Creates cinematic videos from text. You can add voiceovers, avatars, and music. Great for quick, professional-looking content. Synthesia – Helps create AI-powered avatar videos. Ideal for business or training content. Anyone else tried any of these or have other cool tools to share?1 point
-
Now with the advent of AI technology and its usages there has to be changes in the business processes. We will have to compare how any new implementation used to happen without the AI features. In most of the cases the end users used to know of the business processes and in some of the cases the digitization of the business process used to happen or automation the Business end users used to be aware of the process and then after implementation steps i.e. hyper care, whom to report the bugs to, UAT loops, also getting the know how of the low code and no code tools, implementation to take care of minor developments. Now, with the altogether new technology which has bene introduced and is being used in the all the Business processes is AI and this is a challenging upskilling for all the Business processes end users as this has lot of new technology and in order for the team member to keep on training the model, checking on whether the biasness has crept in the model or not, Data ownership policies, steps to identify the drift in the model, Compliance check by the team to ensure that the standards adherence is in place, frequent data model checks and fixing the model (in case it is required) for maintaining the accuracy of the models. There can be multiple approaches to the problem statement of maintaining of the AI related process handover from the development team to Business/Operations team. First option is to hire someone in the team having the know how of the AI world and should be able to handle the post development, system maintenance works. Second option is to have the revisit of the job description as a lot of traditional business processes gets changed because of the AI features being introduced and the current team members who are doing their business process end to end are being trained as part of upskilling and being introduced to AI related skills so that the same team member can take up the post deployment work of AI maintenance and upgradation. The benefit of the second option is that in house team member can be the pioneer as AI champion driving other AI projects and helping other business processes too.1 point
-
Akkul Dhand has provided the winning answer to this question. Answer fro Sumukha is also a must read.1 point
-
There is no doubt to the fact that AI Agents live and breathe on data fed to it which means garbage in garbage out. Data integrity is key to ensuring that AI agents are able to right solutions to problems. The first loop is therefore to ensure that data been fed to these agents are being cleaned before they are fed in. Now to the next phase after the data has been fed to these agents, they get better over time which is based on the training using available data over time. In cases where agents go off track, it is the responsibility of the builder to give accurate feedback to the agents where it must have gone off track or given wrong information so as to document that mistake as a data point and ensure it is stored in its repository to prevent reoccurrence. Most often than not people ignore the errors in AI Agent's responses due to several reason and just copy the outcomes without reviewing for mistakes and errors. If these errors are accepted, it builds the confidence level of the AI Agents into believing that responses provided are 100% correct and stores them as data points as well which would be used to answer and proffer solutions to future problems and then the loop continues. In other to prevent this from happening, first is for AI Agent builders to infuse the feedback look asking if the solution provided meets the users need ot there are specific areas where some changes need to be made. Some can be built in such a way that the AI Agent asks more clarifying questions to allow the user give proper context to help the AI Agent proffer the best solution through contextual framing. Also, feedback rating in my opinion isn't the best way to help the Agent improve on responses or solution but proper feedback on areas where the agent hasn't provided right answers, provided longer responses than needed, the use of words that doesn't make things sound real and a host of other are super important if we aim to help the AI Agents improve based on real feedback. In other words, as much as we want AI Agents to move from very generic responses when proffering solutions to out problems, we should equally be ready to shift away from giving generic feedback to AI Agents as these serves as data points for them to reference is they are to improve and give better outputs.1 point
-
AI agents have been able to revolutionize the business with helping the business team with the usages of AI and bringing in a lot of efficiency. While building the AI agents, there are several methods to train the AI agents through the historical datasets, supervised learning through Natural language processing (NLP) and unsupervised learning by the AI agents on their own trying to find a pattern and gaining knowledge from the information available from the datasets. AI agents needing the continuous learning feedback is specific to the Business case or processes where it is being intended to work in i.e. whether there is a API based agents linking the multiple ERPs, CRM tools together in data analytics tool, or AI agent deployed for interacting with customer agents and working as chatbot etc. In our case, we had worked on deploying the AI agents for the advanced planning and scheduling which before introducing the AI agents were being worked out manually through the excel based working where the data dimensions like the manpower availability, machine availability, machine breakdown reports, customer requirement date (i.e. Sales order date) were all maintained manually and fetched by planner from all the individually maintained datasets and then the scenario and constraint based planning was being done. Now the previous historical datasets related to the constraints based planning and scheduling was being provided to perform the supervised learning and then the unsupervised learning aspects were also checked. After multiple testing cycle, the AI agents were deployed and we were able to achieve good accuracy but the AI agents in this case needed to perform the continuous learning feedback to to improve as there are multiple new constraints arising because of the change in the business scenario were coming up like the introduction of new product required the planning to be kept in mind that there will be a changeover time for the setting up of the jigs and fixtures and machines. Also, the AI agents needed to learn the continuous unsupervised learning through the cues like if the planner is not completing the advanced planning and scheduling even after running multiple simulations that might mean there are certain requirement which the planner is looking to achieve and not being able to get from the planning and scheduling. In this case the AI agents needs to learn through natural language processing and considering these as feedback for further improvement. Also, while planning and learning from continuous feedback, the AI agents needs to mimic the human behavior through the NLP. AI agents needs to use the machine learning to work on incorporating the inputs received through the NLP and customer/users feedback and next action by the AI agents is to interpret the feedback and self improve the response (in this case to improve the planning and scheduling of the machine usages). AI gents needs to find the pattern in the information provided by the usages of NLP and process it further. There can be instances like addition of new ERP system and AI agents requiring the access connect with the new ERP system introduced to being in the Client feedback on the order delivery date and Advanced planning and scheduling requiring to re run the simulations to achieve the optimal planning to integrate real time Client feedback. While we have introduced the AI agent based Advanced planning and scheduling in our machining operation process flow diagram and have replaced the manual planning with the AI agents based Planning. Still, we are looking ahead to provide the supervised learning and monitor the plans prepared through its own learning and usages of the NLP, Machine learning to improve upon the planning capabilities. We are hopeful to achieve the maximum performance through the AI usages of AI agents in the day to day operations.1 point
-
If Ai agent is launched there will have to be ways for people to tell when it works well or makes mistakes. Thumbs up thumbs down would be ideal option, surveys too .. For example if users rate that AI suggestions are outdated we need to refresh database within a defined timeframe also we will review feedback to keep improving.1 point
-
To keep AI agents effective in complex or sensitive user journeys specially during complaints or escalations it is important to apply a structured conversational flow. Clear prompt creation followed by clarifying statements guiding through emotion aware language and paths. The result is helpful and trust building interactions reduce errors, help in reducing customer complaints and improve overall user experience. AI listens, learns, adapts and deliver with continuously improving1 point
-
In the Business Process outsourcing domain, our Continuous Improvement team will play a vital role in driving improved service delivery by improving efficiency & waste reduction. If AI has been introduced, the core activities of analyzing data, automate redundant or routine manual activities & identifying the logics or patterns from the data will be very simple. However the Continuous Improvement function will still play certain roles. Without AI, Continuous improvement team focus on: Process mapping through SIPOC, VSM Identify process gaps through audits or collaboration with Stakeholders Do root cause analysis to understand all possible causes Lead Improvement initiatives through Six Sigma or Lean methodologies Track data and compare pre & post implementation impacts. If AI could be introduced, then AI Roles: Monitor performance metrics & highlights areas on concerns in real time Analyse the feedbacks or responses through LLMs Automation of all reports & dashboards Predict trends / issues by continuously analyzing performance Introduce better models based on emerging needs Responsibilities of Human roles: CI Analysts will focus on evaluating AI-driven observations for strategic fixes. Process Consultants will explore new design collaboration models Trainers will concentrate on enhancing the workforce with emerging technologies. Data analysts will shift focus on creating more predictive / prescriptive models. With AI merger, the Continuous improvement team might go for upgrading new skills such as AI Literacy, Digital Tooling, Strategic thinking, etc to understand how the models work or how to interpret the AI insights. Also learn to work with fine tuning the automated dashboards aligning Ops requirements. To ensure a smooth collaboration between the Humans & AI, certain process redesign might require. AI act as first monitoring layer to watch metrics & suggest improvement areas in real time CI team will review the suggestions, validate & prioritize aligning strategic directions CI team will review the logics or prompt regularly to ensure the model accuracy & avoid false alarms. Collaborate AI suggestions with realtime feedbacks to derive strategic solutions. Define clear roles of AI & CI teams. This way Continuous improvement team will upgrade from traditional problem solvers to proactive change agents.1 point
-
Periodic updates and maintenance strategy becomes the integral part of implementation and control strategy while implementing any AI solution. Without monitoring strategy accuracy and compliance can suffer. Lets consider below failure scenario from Accounts Payable Process: An AI solution is used to extract and validate invoice data like vendor name, amount, date, etc. from email and pdf copies and save those copies on OneDrive designated folder. Over the period of time performance may degrade due to various factor like: Prompt updates not considered for new invoice templates, formats changes in business requirements. Input scenarios not updated periodically. Changes I workflow like changes in approval flow and vendor policies Early Warning Signs: Increase in manual correction by the AP staff Payment delays Vendor complaints Mismatch between PO and invoice data Drop rate / error rate in processing Monitoring: Set alert if drop or error rate drops by 10% and review scenarios Trak manual corrections using tracker Monitor trends Monitor complaints from vendor and AP staff1 point
-
For a AI infused processes there is a need to shift from traditional audit approach to a more dynamic audit approach which can models, prompts, flows. Since AI uses these approach for its BAU working so audits should be more focused on data integrity, accountability, ethical compliance. Below mentioned are the approaches that can be used while building AI audit framework: 1. Prompts and Flow Designs Questions to ask - Are they documented and have a version control mechanism in place? How is the ambiguity handled? Check Items - Prompt repository, Flow Diagrams for execution. 2. Model Governance & Lifecycle Monitoring Questions to ask - What type of AI model is used? Who trained the model and what type of data is used? Is there any documents and updation policy? Check Items - Model validation, Testing, Drift detection, data revision mechanism, Schedules. 3. Data Integrity & Bias Questions to ask - Is data input clean? Are there any detection system for detecting Bias? Check Items - Bias Audits, Data steps to be followed, data lineages. 4. Compliance & Ethical Alignment Questions to ask - Does AI comply with regulatory guidelines set up a board? Are guidelines embedded in the design and the system Check Items - Regulatory mapping, gap analysis,. 5. Human In Loop Questions to ask - Are there any human decision points integrated? is there any recovery mechanism if AI fails? Check Items - HITL workflows and paths to be checked. Feedback Loops. Below mentioned are the best practices for ensuring fairness and transparency: 1. Documentation of AI processes should be mandate. 2. Continuous monitoring for drift, bias, performance for the AI model. 3. Proper aligned communication strategy with stakeholders and business objectives. 4. AI audits at a set frequency.1 point
-
When auditing AI-integrated systems, transparency on how the model works, the security of the data, and whether the prompt logic system is working properly all need to be evaluated. AI systems should be evaluated on whether their decisions are traceable, if there are risks of bias, and if the system meets ethical standards. Examining the sources of the training data, monitoring model drift, and examining output consistency with given prompts constitute critical tasks. Employing accountability-enhancing tools such as explainability mechanisms, inline controls, and collaborative processes bolsters overall accountability. We will ensure proper and responsible use of the systems through regular alignment checks with the overarching business goals.1 point
-
Audit of AI infused process is important to ensure compliance and accountability, since it verify that AI systems function or operate as per the regulatory requirement, and uphold transparency and public trust. Followings are the key points that should considered during the audit: Ø Goal & Scope: It is important that goal and scope should be clearly defined. AI audit is very important to ensure effective examination of the system’s performance, compliance, and standards of ethics. Ø In-depth data and algorithm evaluations: It is important to confirm the accuracy and integrity of data and to rigorously evaluate algorithms in order to ensure the accurate functionality and uphold principles of fairness. Ø Implementation of continuous improvement: Action to be taken on audit findings and implement regular monitoring are critical step to maintain compliance and consistently improve the perfoirmance and reliability of AI System. Followings are the main area’s for an AI Audit: Ø Define the audit scope by determining which AI system will be evaluated and identifying the specific component or process to be examined. Establishment of clear objectives, evaluation criteria, and success metrics to ensure alignment with organizational goals and regulatory requirements. Ø Collection of relevant data related with the AI system i.e. input datasets, documentation related to algorithm, and output results. Make sure that the data is cleaned and validated to facilitate accurate and effective analysis. Ø In order to check whether the AI model function correctly and same are free from errors algorithms review play crucial role. Ø It is important to verify the AI systems in order to ensure that model comply with relevant regulations and standards, such as GDPR and CCPA. Below outlined checkpoints should considered while auditing AI component: Category Checklist Item Governance & Accountability Is there a designated owner for the AI system? Have the role and responsibilities been clearly defined and communicated ? Data Quality & Management Has the source of the training data been properly documented ? Has the data undergone through evaluation to ensure that it is free from biasness? Is the data thoroughly tracked from its original source or point of origin? Are data privacy and consent requirements are met with the policy? Has the model been validated using the data set that are both diverse and representative of use case study Explainability & Transparency Can non-technical stakeholders can understand the decision of AI model’s ? Are prompts and flows (for LLMs) are accurate? Security & Robustness Have appropriate controls been implemented to protect AI System from adversarial attacks? Compliance & Ethics Is there a formalized process in place to conduct for ethical review of AI use cases? Are audit logs and documentation retained for compliance? Business Alignment Are the goals of AI initiatives aligned with the objectives of business Are Key Performance Indicators (KPIs) clearly defined and actively monitored to assess the performance of AI system? In order to maintain transparency, fairness, and alignment with business goals, following approaches should considered: 1) Transparency: · Maintain audit trails for data, models, and decisions. · Use model documentation tools (e.g., Model Card). · Provide user-facing explanations for AI decisions. 2) Fairness: · Ensure that AI systems consistently uphold principles of fairness by avoiding discriminatory outcomes. · Conduct bias periodic audits regularly. · Engage diverse group of stakeholders throughout the model design and testing phase to ensure inclusivity, fairness, and broader perspective in decision-making · Implement feedback loops to catch and correct unfair outcomes. 3) Alignment with Business: · Define clear KPIs for AI performance that align with business goals. · Ensure CFT collaboration · Use AI governance frameworks1 point
-
Traditional audits will be more suitable for regular processes, however to audit an AI Infused process it would be challenging due to static check points. To audit a process which includes AI components, we would require a modernized & robust mechanism which includes dynamic decision making with evolving logics. The Expanded audit criteria for a process with AI components aligning with Business excellence include: Integrity of Prompt/Flow – Verify whether the prompts, logical decisions are properly version-controlled. Track Decisions – Is it possible to validate the model, logic or prompts that how the decisions are made by the model. Regulatory compliance – Verify that the AI models comply with all the required regulatory norms Bias – Does the models take the datasets & logic removing all implicit biases Strategic Alignment – Does the models are mapped & aligned with all Business metrics & KPIs Fragile or outdated model – Verify that the model still providing required outputs with current data or need to be updated. Escalations – Check the frequency of the errors or any repeated exceptions in the flow of the model Interpretation – Can all Business stakeholders understand the decisions taken by the model or any need for explanation Considerable risk factors: · Accuracy of the model goes down and lost its effectiveness · Logical flows not matching / aligned with change in business · Inappropriate mechanism to report issues / improvement suggestions · Outdated knowledge base feed into AI models To ensure Transparency, Fairness and alignment with Business Goals: · Frequent review of modes along with owners, data teams & the users · Maintain a clear version history of all the changes · Create surveys, dashboards and track all override logs to align with KPIs · Validate the models to understand the value it creates against the mapped metrics through different tools. Implementing the same in real-time scenario requires: · Templates with weighted scores across different criteria’s · Dashboard / scorecard to have a better tracking & alignment with Business goals · Train resources to include additional criterias for autiding1 point
-
1 pointWhen I look at how things can go wrong in our process, the Swiss Cheese Model actually paints a clear picture. Even when you have got all the right checks in place, mistakes still manage to happen. That’s because it is not just one thing failing, it is usually several small gaps that all line up. Layers of Defense: For us, the layers of defense are things like SOPs, training programs, tool validations, QA checks, and so on. They are solid on paper, but in real-time operations, none of them are perfect. And they don’t always catch everything. SOP: It can go outdated if no one is keeping them up to date. Training: Training is given, but sometimes people don't get enough hands-on time with the tools, like the decision tree. QA Review: QA reviews are there, but if the sampling isn't representative, the biggest risks can be missed. I have also seen cases where a payers update came in, but our system or team didn’t catch up fast enough. It creates a real gap. Holes: So the “holes” are these small flaws, and if they happen to align, that is when an issue gets through. What helped me is shifting focus from individual errors to looking at the process as a whole, it makes me to ask, where did the system allow this? Business Excellence point of view: This model fits well with the tools we already use. For example, FMEA helps flag the areas where a failure is likely. SIPOC diagrams help me map where each control sits. And when something does go wrong I usually dig into it using the 5 Whys or fishbone just to see which layer didn’t do its job. When I am using DMAIC, this model naturally blends in. I first look at where the most vulnerable is. Then I check how often issues are slipping through. In the Analyze phase, I focus more on connections between gaps than on a single root cause. During Improve, it is usually about tightening up the controls; maybe refreshing training, rewriting an SOP, or adding a validation. Control, to me, is more about ongoing monitoring to make sure things dont drift back. What I like about this model is that it reminds me that it is not about blaming people. It is about designing a system that is strong enough to catch mistakes before they become problems.1 point
-
1 pointEnhance automation to flag DPI violations more accurately Train designers to validate DPI independently of software flags Introduce an additional pre‑print verification layer Refine procedures and learn from customer feedback looping back into the system Together, these actions embody the core of excellence layering defenses smartly, reducing system failures, learning from every incident, and elevating robustness at every stage. This ensures that even when one layer has a problem, others remain intact—and organizational failures become preventive rather than fragile.1 point
























This leaderboard is set to Kolkata/GMT+05:30