

Sourabh Nandi
Members
-
Joined
-
Last visited
-
DISCRETE-EVENT SIMULATION (DES) Business processes are commonly modeled as computer-based, dynamic, stochastic, and discrete simulation models. The most popular way to represent these models within the computer is using Discrete-Event Simulation (DES). In simplistic terms, DES defines how a system with discrete flow units or jobs evolves. Technically, this implies that the computer tracks how and when state variables such as queue lengths and resource availabilities improve over time—the state-variables change due to an event (or discrete event) occurring in the system. A characteristic is that discrete-event models focus only on the time cases when these discrete events occur. This feature allows for vital time compression because it makes it possible to skip through all time segments within events when the system's state remains unchanged. Therefore, the computer can simulate many situations epistolizing to a long real-time span in a short period. To demonstrate the mechanics of a DES model, consider an information desk within an individual server. Suppose that the objective of the simulation is to evaluate the typical delay of a customer. This simulation then must have the following state variables. The status of the server (active or idle). The number of shoppers in the queue. Time of arrival of each shopper in the queue. While the simulation runs, two events can change these state variables' value: the arrival of a customer or service completion. A customer's approach either changes the server's status from idle to busy or increases the number of customers in the queue. On the other hand, the completion of service either changes the server's status from active to idle or minimizes the number of customers in the line. However, the state variables evolve when an event occurs. A discrete-event simulation model analyzes the system's dynamics from one event to the next. The simulation prompts the "simulation clock" from one event to the next and considers that the system does not improve in any way between two consecutive events. For example, suppose a single customer is waiting in line at a grocery store. The subsequent event is the completion of service of the consumer who is currently paying for his groceries. In that case, the discrete-event simulation does not keep track of how the consumer in the line spends the waiting time. Hence, the simulation keeps track of when each event occurs but assumes that nothing occurs during the elapsed time between two consecutive events. The below figure reviews the steps associated with a discrete-event simulation. The simulation begins with initializing the current state of the system and an event list. The primary state of the system, for example, might include some jobs in multiple queues as specified by the analyst. It also could determine the availability of some resources in the process. The most apparent initial state is to consider that no jobs are in the process and that all supplies are currently available. The event list shows the time when the next event will occur. For instance, the event list initially might incorporate the time of the first arrival to the process. Other events might be scheduled originally, as defined by the analyst. Once the initialization move is completed, the clock is advanced to the next phase in the event list. The next event is then performed. The execution of an event triggers three activities. First, the current state of the system is changed. For instance, the executed event might be a job landing in the process. If all the servers are occupied, then the state change consists of adding the arriving job to a queue. Other state changes might expect deleting a job from a queue or making a server occupied. FIGURE: Discrete-Event Simulation [Source: Business Process Modeling, Simulation, and Design by Manuel Laguna] The execution of an event might induce the cancellation of other events. For instance, if the completed event consists of a machine breakdown, this event forces removing the processing of jobs waiting for the machine. Ultimately, the execution of an event may prompt the scheduling of future events. For instance, if a job arrives and is added to a queue, a future event is also added to the event list, indicating that the job will commence processing. During an event is executed, the event is eliminated from the event list. Then the termination rule is checked. If the rule indicates that the end of the simulation has been reached, then raw data & summary statistics are available to the analyst. However, if the termination rule indicates that the simulation has not finished (for instance, because more events remain in the event list), the clock is moved ahead to the next event.

-
Fault Injection: Overview In Fault Injection experiments, various faults are injected into a simulation model of the target system or a hardware-and-software prototype of the system. The behavior of the system in the proximity of each fault is then observed and classified. Parameters that can be considered based on such experiments include the probability that a fault will create an error and the probability that the system will successfully perform the actions required to recover from that error. These actions consist of recognizing the fault, identifying the system component influenced by the fault, and taking appropriate recovery action, involving system reconfiguration. Each of these actions necessitates time that is not continuous but may change from one fault to another and depend on the overall workload. Thus, fault injection experiments and presenting estimates for the coverage factor can also estimate the individual delay's distribution associated with each of the above actions. Also, fault injection experiments can be used to evaluate and validate the system dependability. For instance, errors in the implementation of fault tolerance mechanisms can be identified. System components whose negligence is further likely to result in a total system crash can be identified. Also, the effect of the system's workload on the dependability can be witnessed. Fault Injection: Application Fault injection must be applied to measure the coverage and latency parameters, study error propagation, and analyze the relationship between the system's workload and its fault handling capabilities. Another exciting utilization of fault injection systems is to evaluate the effect of transient faults on the availability of highly reliable systems. These systems were capable of improving from the transient faults but still had misused time doing that, thus diminishing the availability. Various fault injectors have been acquired and are currently in use. Studies comparing several fault injectors have been administered, concluding that two fault injectors may either endorse or complement each other. The latter occurs if they satisfy different faults. The different strategies to fault injection result in quite other characteristics of the corresponding tools. Some of these differences are reviewed in the below table which compares the properties of four approaches to fault injection. [Image Source: Fault-Tolerant Systems By Israel Koren and C. Mani Krishna] All fault injection schemes expect a well-defined fault prototype, which should describe as closely as possible the faults that one requires to see during the endurance of the target system. A fault model must describe the types of defects, their location & duration, and, possibly, the statistical correlations of these properties. The fault models used in currently available fault injection tools deviate considerably, from very detailed device-level faults (for example, a delay fault on a distinct wire) to simplified functional level faults (such as an erroneous adder output).

-
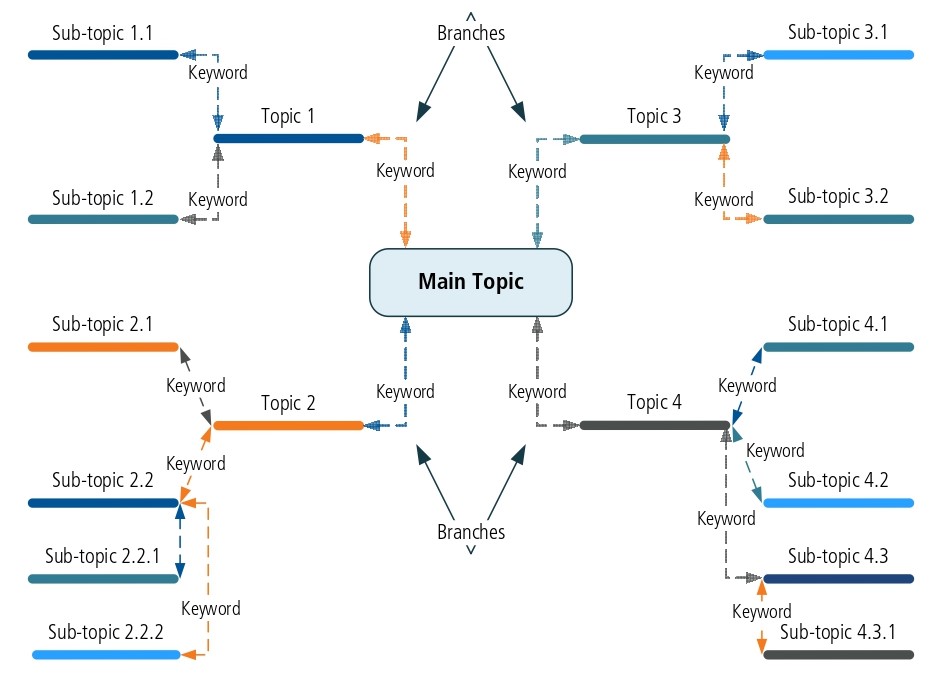
Mind Mapping: The Swiss Army Knife for the Brain Mind Mapping is a technique used to capture and articulate ideas and thoughts in a fashion that resembles how our minds process information. It is a handy collaboration tool that summarizes ideas and thoughts generated on complex concepts or problems in a simplified and consolidated structure, thereby facilitating creative problem solving and decision making. It helps explore relationships between the various aspects of a problem and inspires creative and critical thinking. Mind mapping involves capturing thoughts and ideas in a non-linear diagram that has no standardized format. It uses images, words, colors, and relationships to give a structure to thoughts and ideas. A mind map comprises a central idea (main topic), secondary ideas (subjects), multiple layers of ideas (sub-topics), connection between ideas (branches) with an associated keyword that explains the relationship. Together, these elements capture and articulate the concept. Figure: The Taxonomy of a Mind Map [Image Source: BABOK v3] Strengths Summarizes and provides structure to complex thoughts, ideas, and information. Facilitates decision-making and creative problem-solving. Assists in translating a large amount of information and hence helps in preparing and delivering presentations. Limitations It may be misused as a brainstorming tool and constrain idea generation. It may not be easy to communicate a shared understanding. Examples: Frequent applications of Mind Mapping are: Manuscripts and ‘cribs’ for lectures and presentations Notes from texts and books Notes from talks, presentations, and discussions Project management Knowledge management Exam preparation Arranging a shopping list Taking notes on a longish magazine article Taking notes on a TV documentary or while watching the news Creating a Mind Map of your ‘to do’ list (of course in the form of a Mind Map and not a list!) Minuting your next meeting with a colleague Setting up a packing list for your next holiday or business trip. You can see the personal packing list for business trips below figure; [Image Source: Mind Mapping For Dummies]

-
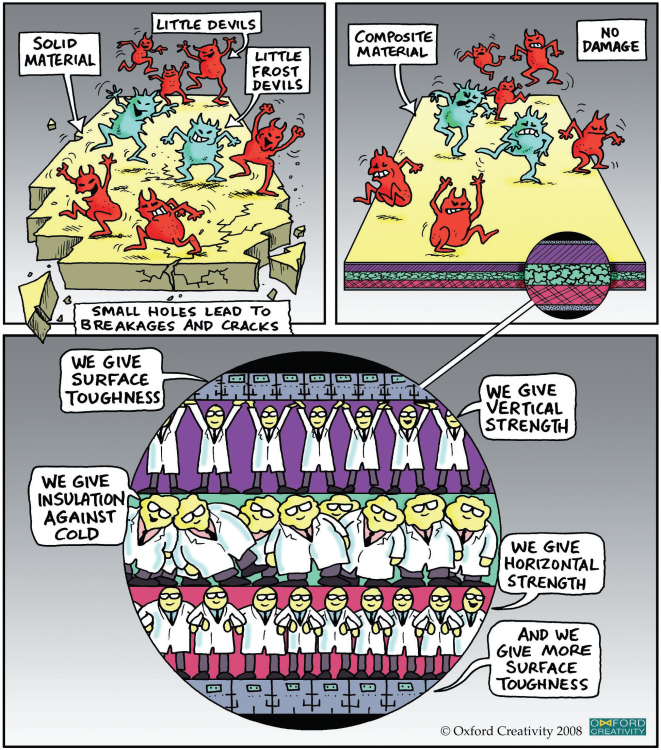
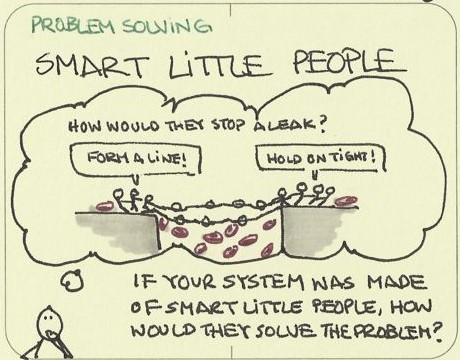
Smart Little People ( SLP ) Smart Little People is a simple TRIZ Creativity tool developed from the observation of innovative and creative people at work. This powerful tool is often mastered in a short period. Smart Little People are tiny imaginary beings who represent the various elements of the matter we try to understand and solve. It works as a mental trick because it’s supported empathy or creating some personal analogy with the case. Compassion means becoming the object/problem and looking out to determine what will be done from its position and viewpoint. If we imagine ourselves becoming so tiny that we are within the problem area and seeing the matter in great detail, this may be useful and harmful. This is often useful for problem understanding but harmful because may we resist solving a controversy if the answer means ourself, as a little being, goes to be destroyed, dissolved, mashed up, dissected, etc. this is often overcome by employing a crowd/multitude of disposable Smart Little People, for which we feel no responsibility. Smart Little People works by modeling the various aspects of the matter (causes and solutions) with different rival or complementary Smart Little People groups. They’re Smart because they need the flexibility and insight to create/solve problems and be anywhere, doing anything. Little means they’re as tiny as necessary – molecular level if required. Rival teams of smart little people are often created, and a few can cause the matter and solve it; they are doing whatever is necessary whether or not this implies they get destroyed. The below figure uses SLP to illustrate a composite element. Altshuller’ s Famous Use of Smart Little People; In much of the TRIZ literature is the original famous Altshuller example of how he designed an ideal marine cable to forestall tethered mines within the sea from being detected and removed. Figure 1.2 shows that minesweepers are accustomed to destroying mines stumped by dragging a cable loop, which traps the mine retaining cable. The mine then detonates or floats to the surface. Altshuller’s challenge was to style a cable that might tether the mine to the seabed and allow the minesweeper cable to tolerate it. Altshuller drew the zone of conflict as if with populated the smart little people, and by imagining a little person holding the feet of the small person above, he saw the solution. (Figure 1.3 ). The device which was developed is widely used works sort of a rotating door. It’s supported the smart little person’s principle of letting associate with one hand to allow the cable to withstand while still hanging on with the opposite hand. Then rejoining the primary hand and letting go with the use. Therefore, the line passes through, but the vertical link is always maintained. Conclusion; Smart Little People is an excellent tool for modeling any real-world problem. When we use Smart Little People, we zoom and enter the problem zone. As we model our situation, we identify exactly what’s going on the location. We become responsive to the fine details so we can specialize in the place where our problem is going on – but in a very conceptual way. Our Smart Little People then facilitate us to find solutions.
2.thumb.jpg.fb46c69ae9896d1ef8bc48c4b00b81bc.jpg)
-
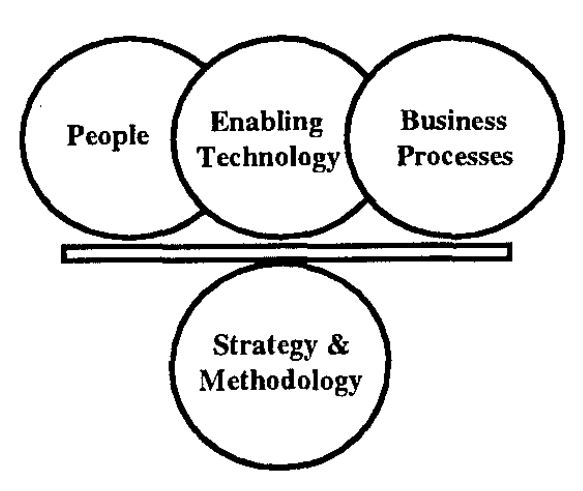
What is Business Process Re-engineering (BPR)? The complexity associated with any new business model is often staggering. Many organizations tend to miscast tactics or speculate meanings. Hammer and Champy provide the most extensively used definition for Business Process Reengineering (BPR) in their best-selling book "Re-engineering the Corporation" which reads as follows; "The fundamental re-thinking and radical re-design of business processes to achieve dramatic improvements in contemporary critical measures of performance, such as cost, quality, service, and speed." How to select a process that is suitable for BPR? An adequate BPR integrates people, technology, and business processes under the guidance of strategy and methodology. Those who take a critical aspect of these building blocks should recognize that people, technology, and business processes are existing elements within the business enterprise. BPR is accurately the mechanism by which strategy and methodology can effectively utilize and restructure these resources, adding value to both process & product. Therefore, strategy and methodology have the most significant overall influence on BPR implementation and balance how the other business elements (people, enabling technology, and business processes) are integrated. a) PEOPLE; Even with an increased emphasis on technology and automation, people still represent BPR's most robust contributing resource. The bulk of process and business process knowledge resides with individuals who can collectively support or derail a BPR effort. How people interact with business processes through information technology and process technology solutions significantly impacts business processes' operational efficiency. BPR reserves not to remove people from the business (i.e., staff reductions), yet as a consequence of BPR application, the abundance of people required to implement a process may decrease. Performing processes more efficiently often means using fewer resources (including people) to finish required activities. BPR aims to drastically improve process performance over time by combining people and technology as enablers. b) BUSINESS PROCESSES; All businesses have functioning business processes. Business processes represent the engine by which a business operates, with information, people, and materials being the fuels/resources necessary to stay the engine running. Hammer and Champy would argue that BPR's goal is not to repair existing business processes but to revamp (change) a business process completely. In short, they recommend a whole engine overhaul or replacement. Irrespective of whether fixing or redesigning a business process is required, rethinking business processes is critical. Information is acknowledged as a part of the business process building block since information is created, maintained within, and output from processes. As explained, information plays a significant role in modifying a business process during re-engineering. c) TECHNOLOGY; To remain competitive, an organization must continuously appraise its machinery, control systems, information systems, communication resources, and methods. Each portion of the overall system must be regularly upgraded to incorporate efficient new technologies and methods. Most of today's technology is obsolete long before it crumbles. Besides, many market developments will lead to systems that are obsolete before they are completed. An inadequate solution is also proposed for an enormous problem, or inordinate amounts of personnel, time, and money could also be squandered on a grandiose development scheme. As a consequence, complete systems and associated processes often neglect to satisfy customer needs and expectations. There is no such entity as a perfectly designed system or process that will meet all possible customer needs over an extended period without change. Ideally, a newly upgraded computerized system is configured to adapt to fulfill changing requirements without complete replacement. Planning and diligent up-front attention to applying appropriate technologies will help ensure that automation is appropriately aligned with the business process workflow. Frequently, automation is becoming the cornerstone of any process improvement effort. d) STRATEGY & METHODOLOGY; However, without any strategy and methodology, business process improvement would essentially be guesswork. BUSINESS PROCESS RE-ENGINEERING CRITICAL FACTORS Top management must be supportive of and involved in re-engineering attempts to eliminate barriers and drive success. An organization's culture must be responsive to re-engineering goals and principles. Significant improvements and savings are realized by specializing in the business from a process perspective instead of a functional perspective. Processes should be chosen for re-engineering supported by a transparent opinion of customer needs, anticipated benefits, and potential fulfillment. Process owners should manage re-engineering projects with cross-functional teams, maintain a correct scope, specialize in customer metrics, and enforce implementation timeliness. Is the DMADV roadmap practical for BPR projects? A Six Sigma DMADV project focuses on reducing variation and streamlining the processes to realize customer satisfaction. It is going not necessarily to change the whole process flow. Prefer it takes place in BPR. The critical difference between Six Sigma and BPR. However, Six Sigma DMADV uses an "align and develop" five-step method to spot the basis causes and does not entirely redesign the BPR method. By using Six Sigma in BPR projects, we will get: Statistically essential tools and methods to develop quality processes and knock out variation The process improvements are data-driven, using baselines, scorecards, dashboards, and metrics A typical process improvement language Stage-gating, ensuring that every one deliverable undergo DMADV (Define, Measure, Analyze, Design and Verify) phases The exclusion of process defects, scrap, and rework so costs decrease The sigma quality level that compares processes and describes the internal customer voice Using Six Sigma in BPR projects enables the "customer inward" approach, an end-to-end strategy mainly driven by the customer's voice. It should enable collaboration by all business segments, even external partners, and be well-managed to define success.

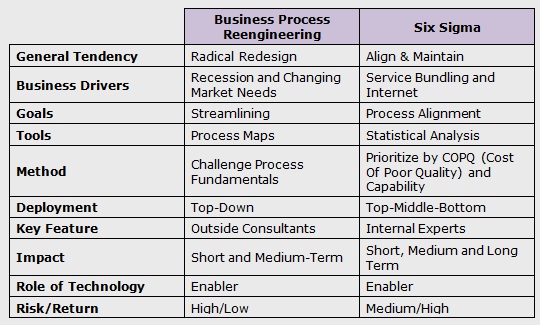

-
What is Just in Time? Just-in-time (JIT) manufacturing, also known as the Toyota Production System (TPS) or Just-in-time production, is a management philosophy that primarily reduces times within the production system and response times from suppliers' customers. The advantages of a Just-in-time (JIT) system The following are some of the advantages that gain through the implementation of Just-in-Time: Reduction in order to payment timeline Reduction in Inventory costs Reduction in space required. Reduction in handling equipment and other costs Lead time reductions Reduced planning complexity Improved Quality Productivity increases Problems are highlighted quicker. Employee empowerment The Pre-Requisites for implementing Just-in-Time Just in Time is simply one of all the pillars of a lean manufacturing system, and in and of itself, it can not be implemented in isolation and without a firm foundation on which to make. Trying to scale back batch sizes without tackling setup times as an example cannot be done. The subsequent are a number of the items that have to be implemented for JIT to be ready to work: Reliable Equipment and Machines; if the machinery is usually breaking down or giving quality problems, it will frequently manifest minor issues with any Just-in-Time flow. The implementation of TPM (Total Productive Maintenance) is required to ensure that that can depend on the equipment and attenuate any failure processes' impact. Well designed work cells; A poor layout, some unclear process flow, and various other issues can all be cleared up by implementing 5S within a production unit. This straightforward and easy to implement lean tool will make a significant improvement in the efficiencies-all by itself. Quality Improvements; an empowered workforce tasked with tackling their quality problems with all of the support they have is another vital part of any lean and JIT implementation. Fitting kaizen or quality improvement teams and using quality tools to spot and solve problems is significant. Standardized Operations; only if someone recognizes how each operation goes to be performed can make sure what the reliable outcome will be. The standard ways of working for all operations will help ensure that the processes are reliable and predictable. Pull Production; Just-in-time does not push raw materials in at the forepart to form inventory (push production); it seeks to tug production through the method in step with customer demand. It achieves this by fixing “supermarkets” between different processes from which products are taken or by the employment of Kanbans, which are signals (flags) to inform the previous process of what must be made. Single-piece Flow; the perfect situation is when we produce one product as ordered by the customer. It is not immediately possible but should always be the end goal. To appreciate this, we will significantly reduce batch sizes by using the Single Minute Exchange of Die (SMED), which seeks to reduce the time taken for any setup significantly. It will also often need smaller dedicated machines and processes rather than complex machines. The flow of the customer; the demand of the customer he usually mentioned as the Takt time. We wish to confirm that the cells and processes are organized, balanced, and planned to realize the customer's pull. This is often achieved through Heijunker and Yamazumi charts.
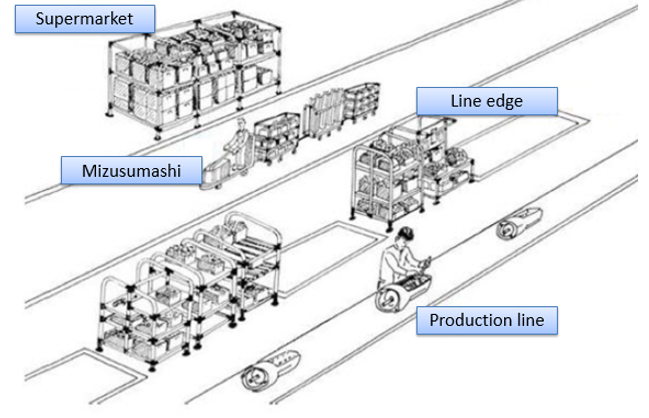
.thumb.jpg.3bd5b80a59a52a34d9e47b9205808ec1.jpg) What is a Water spider (or Mizusumashi) The Water Spider (“Mizusumashi”) System is one of the improvement specialties in internal logistics flow. This Japanese word indicates “water beetle,” and this internal logistics worker is often called a “water spider” in English. This term probably was chosen for this concept because of the water beetle’s agility as it swims across the water. Here a mizusumashi is a logistics worker who does the internal transportation of goods using a standard fixed cycle route. The Water Spider is a critical element of the creation of internal logistics flow. A worker moves all the information related to production orders (kanban) along with all containers. However, a water spider moves the flow containers between supermarkets and the border of lines by repeating the same movements in a fixed cycle (which usually runs for 20 or 60 minutes). During this cycle, the water spider will stop in a certain number of stations along the route and check whether they need materials. The water spider uses a small train with a suitable load capacity to serve all the stations on its fixed route, delivering information to several points along the way. The mizusumashi fixed cycle time is also called the pitch time. This pitch time is a multiple of the takt time. If the mizusumashi is moving one piece at a time, the pitch time would equal the cycle time. Because the mizusumashi is moving small containers, the pitch time is designed to carry several small boxes to many points of use at the border of several lines. The customers are the production operators on the lines. They have a reliable logistics provider who comes every 20 or 60 minutes, looks to see if more material is needed, and removes the empty containers and any garbage generated during the process (also known as reverse logistics). Production is assured of a reliable and frequent supply. How Waterspider help in building successful lean factories? The mizusumashi system is one of the most important means of creating internal logistics flow to build successful lean factories. The water spider operates like a shuttle service at an airport. The shuttle service has a fixed route (e.g., Arrivals 1, Arrivals 2, Hotel 1, Hotel 2, and Hotel 3) that it keeps on the following cycle after cycle. The cycle timing can be calculated—if we allow 4 minutes for each shuttle stop and 20 minutes for the driving time between visits, we have a cycle of 40 minutes. There will be a schedule at every shuttle stop that shows the estimated time of arrival. The users know that every 40 minutes, the shuttle will arrive. Once they are on board, they know what time they will arrive at their destination. The mizusumashi system operates the same way. It has the following characteristics: The mizusumashi “shuttle” stops are at supermarkets (i.e., picking supermarkets, border-of-line supermarkets, kitting supermarkets, or finished- goods delivery supermarkets). The cycle is calculated in the same way, by measuring the work to be done at several stops and adding the travel time. At this level of organization, the containers to be moved onboard the shuttle service are the equivalent of customers or passengers. The water spider’s definitive work means a fixed route (i.e., a plan that shows the travel route and the stopping points) and a constant cycle time determined by the sum of the times involved. Because we are using supermarkets and flow containers, we can improve the productivity of the mizusumashi by enhancing the operator’s standard work, just as we improved routine work to achieve production flow. As well as moving materials and empty containers and doing other driving tasks, the mizusumashi also moves the information associated with replenishment and different synchronization needs. Figure: The advantages of using Mizusumashi over Forklifts
What is a Water spider (or Mizusumashi) The Water Spider (“Mizusumashi”) System is one of the improvement specialties in internal logistics flow. This Japanese word indicates “water beetle,” and this internal logistics worker is often called a “water spider” in English. This term probably was chosen for this concept because of the water beetle’s agility as it swims across the water. Here a mizusumashi is a logistics worker who does the internal transportation of goods using a standard fixed cycle route. The Water Spider is a critical element of the creation of internal logistics flow. A worker moves all the information related to production orders (kanban) along with all containers. However, a water spider moves the flow containers between supermarkets and the border of lines by repeating the same movements in a fixed cycle (which usually runs for 20 or 60 minutes). During this cycle, the water spider will stop in a certain number of stations along the route and check whether they need materials. The water spider uses a small train with a suitable load capacity to serve all the stations on its fixed route, delivering information to several points along the way. The mizusumashi fixed cycle time is also called the pitch time. This pitch time is a multiple of the takt time. If the mizusumashi is moving one piece at a time, the pitch time would equal the cycle time. Because the mizusumashi is moving small containers, the pitch time is designed to carry several small boxes to many points of use at the border of several lines. The customers are the production operators on the lines. They have a reliable logistics provider who comes every 20 or 60 minutes, looks to see if more material is needed, and removes the empty containers and any garbage generated during the process (also known as reverse logistics). Production is assured of a reliable and frequent supply. How Waterspider help in building successful lean factories? The mizusumashi system is one of the most important means of creating internal logistics flow to build successful lean factories. The water spider operates like a shuttle service at an airport. The shuttle service has a fixed route (e.g., Arrivals 1, Arrivals 2, Hotel 1, Hotel 2, and Hotel 3) that it keeps on the following cycle after cycle. The cycle timing can be calculated—if we allow 4 minutes for each shuttle stop and 20 minutes for the driving time between visits, we have a cycle of 40 minutes. There will be a schedule at every shuttle stop that shows the estimated time of arrival. The users know that every 40 minutes, the shuttle will arrive. Once they are on board, they know what time they will arrive at their destination. The mizusumashi system operates the same way. It has the following characteristics: The mizusumashi “shuttle” stops are at supermarkets (i.e., picking supermarkets, border-of-line supermarkets, kitting supermarkets, or finished- goods delivery supermarkets). The cycle is calculated in the same way, by measuring the work to be done at several stops and adding the travel time. At this level of organization, the containers to be moved onboard the shuttle service are the equivalent of customers or passengers. The water spider’s definitive work means a fixed route (i.e., a plan that shows the travel route and the stopping points) and a constant cycle time determined by the sum of the times involved. Because we are using supermarkets and flow containers, we can improve the productivity of the mizusumashi by enhancing the operator’s standard work, just as we improved routine work to achieve production flow. As well as moving materials and empty containers and doing other driving tasks, the mizusumashi also moves the information associated with replenishment and different synchronization needs. Figure: The advantages of using Mizusumashi over Forklifts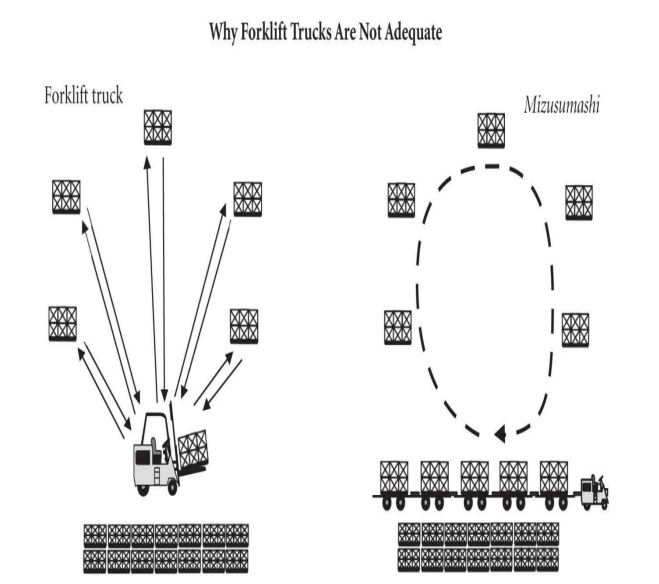
 What is Class imbalance? Data are assumed to suffer the Class Imbalance Problem when the class distributions are incredibly imbalanced. In this connection, many classification learning algorithms have moderate predictive accuracy for the uncommon class. Cost-sensitive learning is a general approach to solve this problem. Class imbalanced data-sets occur in much real-world applicability where the class distributions of data are highly imbalanced. However, in the two-class case, we can assume that the minority or rare class is a positive class without losing generality. The majority class falls under the negative type. Often the minority class is very uncommon, such as 1% of the data-set. If someone applies various traditional (cost insensitive) classifiers on the data-set, they will likely predict everything negative (the majority class). This was often perceived as a problem in learning from highly imbalanced data-sets. However, there are two fundamental assumptions made by traditional cost insensitive classifiers. The first is that the classifiers’ goal is to maximize the accuracy (or minimize the error rate); the second is that the training and test data-sets’data-sets’ class distribution is identical. Following these 2 assumptions, predicting everything as negative for a highly imbalanced data-set is frequently the right thing to do. Thus, the imbalanced class problem becomes significant provided that one or both of the 2 assumptions above aren’t true; i.e., if the value of various kinds of error (false positive and false negative within the binary classification) isn’t identical, or if the category distribution within the test data is unusual from that of the training data. The primary case is often managed effectively, applying methods in cost-sensitive meta-learning. In the case when the misclassification cost isn’t equal, it’s usually costlier to misclassify a minority (positive) example into the bulk (negative) class than a majority example into the minority class (otherwise, it’s more plausible to predict everything as unfavorable). i.e., FNcost > FPcost. Thus, given the values of FNcost and FPcost, a range of cost-sensitive meta-learning methods will be and are accustomed to solving the category imbalance problem. If the prices of FNcost and FPcost don’t seem to be unknown explicitly, FNcost and FPcost will be assigned to be proportional to the quantity of positive and negative training cases. If the category distributions of coaching and test data-sets are different (e.g., if the training data is very imbalanced but the test data is more balanced), a transparent approach is to sample the training data specified its class distribution is that the same because the test data.This can be accomplished by oversampling (creating multiple copies of examples of) the minority class and/or undersampling (selecting a subset of) the bulk type. Note that sometimes the number of minority class instances is too small for classifiers to be told adequately. This can be insufficient (small) training data and different from that of imbalanced data-sets. Methods for addressing Class Imbalance? Methods for addressing class imbalance can be divided into two main categories. The first category is data-level methods that operate on the training set. The other type covers classifier (algorithmic) level methods, which keeps the training data-set unchanged and adjust training or inference algorithms. 1.Data level methods a. Oversampling b. Undersampling 2. Classifier level methods a. Thresholding b. Cost-sensitive learning c. One-class classification d. Hybrid of methods How does Class imbalance affect the outcome of a predictive classification model? Class imbalance poses a hurdle for predictive classification modeling. Most of these machine learning algorithms used for classification were designed to assume an equal number of examples for every class, leading to models with poor predictive performance, specifically for the minority class. This can be an issue because, typically, the minority class is more important. So the matter is more sensitive to classification errors for the minority class than the bulk class. There are perhaps two leading causes for the imbalance; they are data sampling and the domain properties. It is also possible that the imbalance in the examples beyond the classes was caused by the way the specimens were collected or sampled from the problem domain, which might include biases acquainted during data collection and errors made during data collection. Examples where class imbalance exists? This problem is widespread in practice and can be observed in various disciplines, including Fraud Detection. Medical diagnosis Spam Detection Claim Prediction Default Prediction. Oil spillage detection. Facial recognition Churn Prediction. Spam Detection. Anomaly Detection. Outlier Detection. Intrusion Detection Conversion Prediction. Binary Classification Software Defect Prediction Building Decision Trees for the Multi-class Imbalance Problem Non-Linear Gradient Boosting for Class-Imbalance Learning Hybrid Sampling with Bagging for Class Imbalance Learning
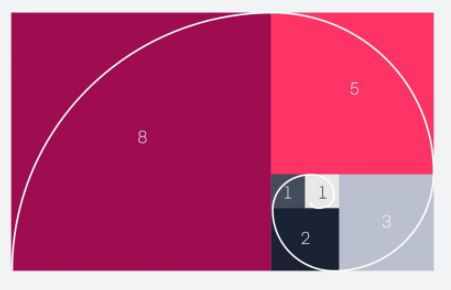
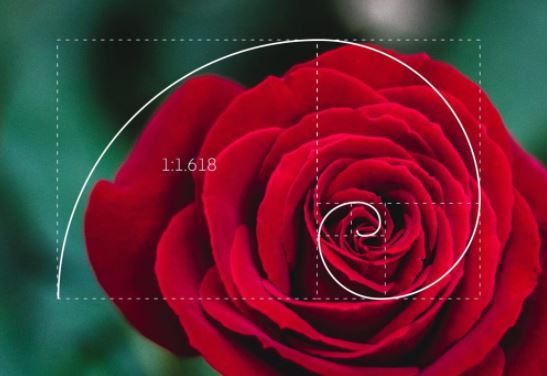
What is Class imbalance? Data are assumed to suffer the Class Imbalance Problem when the class distributions are incredibly imbalanced. In this connection, many classification learning algorithms have moderate predictive accuracy for the uncommon class. Cost-sensitive learning is a general approach to solve this problem. Class imbalanced data-sets occur in much real-world applicability where the class distributions of data are highly imbalanced. However, in the two-class case, we can assume that the minority or rare class is a positive class without losing generality. The majority class falls under the negative type. Often the minority class is very uncommon, such as 1% of the data-set. If someone applies various traditional (cost insensitive) classifiers on the data-set, they will likely predict everything negative (the majority class). This was often perceived as a problem in learning from highly imbalanced data-sets. However, there are two fundamental assumptions made by traditional cost insensitive classifiers. The first is that the classifiers’ goal is to maximize the accuracy (or minimize the error rate); the second is that the training and test data-sets’data-sets’ class distribution is identical. Following these 2 assumptions, predicting everything as negative for a highly imbalanced data-set is frequently the right thing to do. Thus, the imbalanced class problem becomes significant provided that one or both of the 2 assumptions above aren’t true; i.e., if the value of various kinds of error (false positive and false negative within the binary classification) isn’t identical, or if the category distribution within the test data is unusual from that of the training data. The primary case is often managed effectively, applying methods in cost-sensitive meta-learning. In the case when the misclassification cost isn’t equal, it’s usually costlier to misclassify a minority (positive) example into the bulk (negative) class than a majority example into the minority class (otherwise, it’s more plausible to predict everything as unfavorable). i.e., FNcost > FPcost. Thus, given the values of FNcost and FPcost, a range of cost-sensitive meta-learning methods will be and are accustomed to solving the category imbalance problem. If the prices of FNcost and FPcost don’t seem to be unknown explicitly, FNcost and FPcost will be assigned to be proportional to the quantity of positive and negative training cases. If the category distributions of coaching and test data-sets are different (e.g., if the training data is very imbalanced but the test data is more balanced), a transparent approach is to sample the training data specified its class distribution is that the same because the test data.This can be accomplished by oversampling (creating multiple copies of examples of) the minority class and/or undersampling (selecting a subset of) the bulk type. Note that sometimes the number of minority class instances is too small for classifiers to be told adequately. This can be insufficient (small) training data and different from that of imbalanced data-sets. Methods for addressing Class Imbalance? Methods for addressing class imbalance can be divided into two main categories. The first category is data-level methods that operate on the training set. The other type covers classifier (algorithmic) level methods, which keeps the training data-set unchanged and adjust training or inference algorithms. 1.Data level methods a. Oversampling b. Undersampling 2. Classifier level methods a. Thresholding b. Cost-sensitive learning c. One-class classification d. Hybrid of methods How does Class imbalance affect the outcome of a predictive classification model? Class imbalance poses a hurdle for predictive classification modeling. Most of these machine learning algorithms used for classification were designed to assume an equal number of examples for every class, leading to models with poor predictive performance, specifically for the minority class. This can be an issue because, typically, the minority class is more important. So the matter is more sensitive to classification errors for the minority class than the bulk class. There are perhaps two leading causes for the imbalance; they are data sampling and the domain properties. It is also possible that the imbalance in the examples beyond the classes was caused by the way the specimens were collected or sampled from the problem domain, which might include biases acquainted during data collection and errors made during data collection. Examples where class imbalance exists? This problem is widespread in practice and can be observed in various disciplines, including Fraud Detection. Medical diagnosis Spam Detection Claim Prediction Default Prediction. Oil spillage detection. Facial recognition Churn Prediction. Spam Detection. Anomaly Detection. Outlier Detection. Intrusion Detection Conversion Prediction. Binary Classification Software Defect Prediction Building Decision Trees for the Multi-class Imbalance Problem Non-Linear Gradient Boosting for Class-Imbalance Learning Hybrid Sampling with Bagging for Class Imbalance Learning The Golden Ratio is a mathematical ratio found almost anywhere, like nature, architecture, painting, photography, and music. When applied to design specifically, it creates an organic, balanced, and aesthetically-pleasing composition. The Golden Ratio is derived when we divide a line into two parts and the longer part (a) separated by, the smaller section (b) is equal to the sum of (a) + (b) divided by (a), which both equal to 1.618. This formula helps us to create shapes, logos, layouts, and more. Using the same idea, we can create a golden rectangle. The below diagram shows a rectangle with harmonious proportions using a square and multiple sides by 1.618 to get a new shape of a rectangle with balanced proportions. While applying the Golden Ratio formula to the new rectangle, we end up with an image made up of increasingly smaller squares. Therefore, spiral over each square, starting in one corner and ending in the opposite one, we get the Fibonacci sequence (also known as the Golden Spiral). Example1: Used for a Logo Design Example2: Cropping and resizing images Example3: Typography and defining hierarchy The Golden Ratio helps us find font size used for headers and body copy on a website, landing page, blog post, or even print drive.
The Golden Ratio is a mathematical ratio found almost anywhere, like nature, architecture, painting, photography, and music. When applied to design specifically, it creates an organic, balanced, and aesthetically-pleasing composition. The Golden Ratio is derived when we divide a line into two parts and the longer part (a) separated by, the smaller section (b) is equal to the sum of (a) + (b) divided by (a), which both equal to 1.618. This formula helps us to create shapes, logos, layouts, and more. Using the same idea, we can create a golden rectangle. The below diagram shows a rectangle with harmonious proportions using a square and multiple sides by 1.618 to get a new shape of a rectangle with balanced proportions. While applying the Golden Ratio formula to the new rectangle, we end up with an image made up of increasingly smaller squares. Therefore, spiral over each square, starting in one corner and ending in the opposite one, we get the Fibonacci sequence (also known as the Golden Spiral). Example1: Used for a Logo Design Example2: Cropping and resizing images Example3: Typography and defining hierarchy The Golden Ratio helps us find font size used for headers and body copy on a website, landing page, blog post, or even print drive.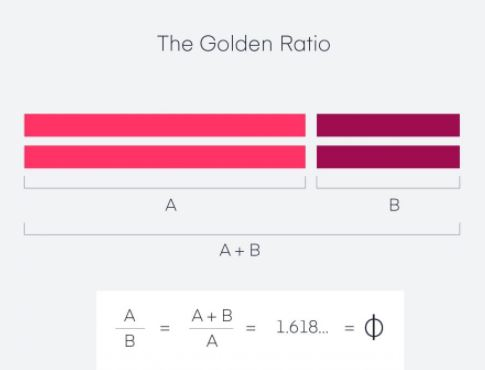


 What is a Block Diagram? A block diagram is a specific, high-level flowchart utilized in engineering, hardware design, electronic design, software design, and process flow diagrams. It is used to design innovative systems or to describe and enhance existing ones. The block diagram represents, at a sketch level, how a process flows from function to function or from unit to unit within an establishment. The diagram uses blocks to reflect the essential activities and links them together by connecting lines representing elements or communication flows. Essential Components of a Block Diagram Block: it describes the logical and physical elements of the system. Part: it includes all aspects modeled using association and aggregation. Reference: it has all the components which were developed utilizing association and aggregation. Standard Port: is the point of interaction between a system block and the identical environment. Flow Port: is the point of interaction wherever a block can emerge from or to. The Ideal Applications of Block Diagram To provide a high-level representation of a process flow. To promote harmony of process function and sequence. To distinguish cross-functional unit interfacing. Problem-solving phase Select & define problem or opportunity Recognize and analyze causes or potential change Develop and propose possible solutions or change Execute and evaluate solution or change Measure and report solution or change results Acknowledge and reward team efforts Block Diagram is typically used by Statistician / Quality Analyst Creativity & Innovation practitioner Engineers Project Managers Manufacturing Sales and Marketing professionals Administration/documentation Servicing/support Customer/quality metrics Change management Benefits of the Block Diagram Block Diagram improves understanding of the process by showing all involved parts and how they are interconnected in a straightforward format. A block diagram is a beneficial tool both in designing unique processes and in improving existing processes. In both cases, the diagram provides a fast, visually clear view of the work and should rapidly result in process points of interest. Block Diagrams used "before" Process Analysis Problem Analysis Workflow Analysis (WFA) Systems Analysis Diagram Work breakdown structure (WBS) Block Diagrams used after Process Mapping Activity analysis Potential Problem Analysis (PPA) Organization Chart Functional Map Symbols Used in Block Diagram Block diagrams use fundamental geometric shapes: Boxes, Triangles, and Circles. The essential parts and functions are represented by blocks attached by straight lines representing relationships. Step-by-step procedure STEP 1 - The team distinguishes all functions or activities inside a process and checks where the start and stop functions are defined by team agreement. STEP 2 - The functions are then sequenced and dramatize on a whiteboard or flip charts in a block diagram arrangement. STEP 3 - The team verifies that all functions (blocks) are considered for and represented in the proper sequence to correctly reflect the current process. STEP 4 - Subsequently, additional supporting information is added, and the diagram is recorded. Example of Block Diagram application The most beneficial way to understand block diagrams is to look at the below example.
What is a Block Diagram? A block diagram is a specific, high-level flowchart utilized in engineering, hardware design, electronic design, software design, and process flow diagrams. It is used to design innovative systems or to describe and enhance existing ones. The block diagram represents, at a sketch level, how a process flows from function to function or from unit to unit within an establishment. The diagram uses blocks to reflect the essential activities and links them together by connecting lines representing elements or communication flows. Essential Components of a Block Diagram Block: it describes the logical and physical elements of the system. Part: it includes all aspects modeled using association and aggregation. Reference: it has all the components which were developed utilizing association and aggregation. Standard Port: is the point of interaction between a system block and the identical environment. Flow Port: is the point of interaction wherever a block can emerge from or to. The Ideal Applications of Block Diagram To provide a high-level representation of a process flow. To promote harmony of process function and sequence. To distinguish cross-functional unit interfacing. Problem-solving phase Select & define problem or opportunity Recognize and analyze causes or potential change Develop and propose possible solutions or change Execute and evaluate solution or change Measure and report solution or change results Acknowledge and reward team efforts Block Diagram is typically used by Statistician / Quality Analyst Creativity & Innovation practitioner Engineers Project Managers Manufacturing Sales and Marketing professionals Administration/documentation Servicing/support Customer/quality metrics Change management Benefits of the Block Diagram Block Diagram improves understanding of the process by showing all involved parts and how they are interconnected in a straightforward format. A block diagram is a beneficial tool both in designing unique processes and in improving existing processes. In both cases, the diagram provides a fast, visually clear view of the work and should rapidly result in process points of interest. Block Diagrams used "before" Process Analysis Problem Analysis Workflow Analysis (WFA) Systems Analysis Diagram Work breakdown structure (WBS) Block Diagrams used after Process Mapping Activity analysis Potential Problem Analysis (PPA) Organization Chart Functional Map Symbols Used in Block Diagram Block diagrams use fundamental geometric shapes: Boxes, Triangles, and Circles. The essential parts and functions are represented by blocks attached by straight lines representing relationships. Step-by-step procedure STEP 1 - The team distinguishes all functions or activities inside a process and checks where the start and stop functions are defined by team agreement. STEP 2 - The functions are then sequenced and dramatize on a whiteboard or flip charts in a block diagram arrangement. STEP 3 - The team verifies that all functions (blocks) are considered for and represented in the proper sequence to correctly reflect the current process. STEP 4 - Subsequently, additional supporting information is added, and the diagram is recorded. Example of Block Diagram application The most beneficial way to understand block diagrams is to look at the below example.

2.jpg.c5f1ce006f6693b8ece7fe61ec5302fe.jpg)


.jpg.5d046f091396340a5ce3f9ad1e47feeb.jpg)






Account
Navigation
Search
Configure browser push notifications
Chrome (Android)
- Tap the lock icon next to the address bar.
- Tap Permissions → Notifications.
- Adjust your preference.
Chrome (Desktop)
- Click the padlock icon in the address bar.
- Select Site settings.
- Find Notifications and adjust your preference.
Safari (iOS 16.4+)
- Ensure the site is installed via Add to Home Screen.
- Open Settings App → Notifications.
- Find your app name and adjust your preference.
Safari (macOS)
- Go to Safari → Preferences.
- Click the Websites tab.
- Select Notifications in the sidebar.
- Find this website and adjust your preference.
Edge (Android)
- Tap the lock icon next to the address bar.
- Tap Permissions.
- Find Notifications and adjust your preference.
Edge (Desktop)
- Click the padlock icon in the address bar.
- Click Permissions for this site.
- Find Notifications and adjust your preference.
Firefox (Android)
- Go to Settings → Site permissions.
- Tap Notifications.
- Find this site in the list and adjust your preference.
Firefox (Desktop)
- Open Firefox Settings.
- Search for Notifications.
- Find this site in the list and adjust your preference.