Mohamed Asif Abdul Hameed
Fraternity Members
-
Joined
-
Last visited
Everything posted by Mohamed Asif Abdul Hameed
-
Mohamed Asif Abdul Hameed replied to Vishwadeep Khatri's topic in We ask and you answer! The best answer wins!Weighted Shortest Job First (WSJF) is a prevailing model for ranking and prioritization. This is utilized in job sequencing based on features, capabilities and epics. Scaled agile framework (SAFe) customs WSJF to prioritize backlogs. WSJF is equally referred as CD3 (Cost of Delay Divided by Duration). Calculation: WSJF = CoD/Job Size CoD – Cost of Delay – Economic impact of delay in project delivery Job Size is the Job duration. Typical WSJF calculation that is used during PI Cycle is given below CoD consideration includes user business value, time criticality and risk reduction. Below are some of the drilldowns of the respective considerations. User business value: Relative value of the opportunity Opportunity rank in comparison to other Revenue generation or cost avoidance Time Criticality: Opportunity value decline by time Target/fixed deadline Impact Risk Reduction Opportunity reduces risk Create new opportunities Cost of Delay is a critical and key metric, while prioritizing and it has become essential to ask this fundamental question, “What will cost us the Most? Doing it Now or Delaying it Later?” Specific to cost of delay, we can compare WSJF with other prioritization models like Short Job First and Most Valuable First. Below table summarized the comparison. However, possible comparison from a broader prioritization lookout, we can compare WSJF with MoSCoW, Kano, RICE, Eisenhower, Value vs Effort, Walking skeleton models. Each model has its own Pros and Cons. WSJF is a great tool for prioritization, it gives clear picture when to go for Low hanging Fruit Vs Projects with higher value. However, we don't have to rely upon WSJF each and every time as few features and deliverables are supposed to be delivered at the right time without brainstorming.




-
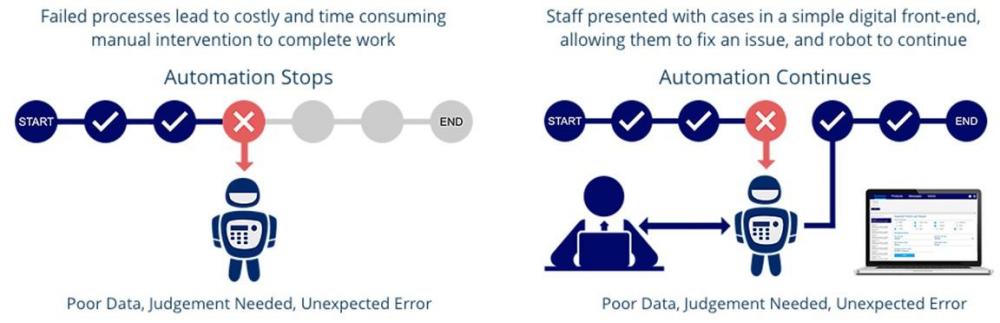
Mohamed Asif Abdul Hameed replied to Vishwadeep Khatri's topic in We ask and you answer! The best answer wins!Outline: Attended Bots are used explicitly when we cannot automate the entire end to end process. These Bots are commonly referred as “Human-In-the-Loop” Automations (HitL). Typically, the transaction is carried by both Human and Digital worker together, were the exchange/interaction and handover of data happens based on the defined logics. On the contrary, unattended bots complete the transactions by interacting with various applications, independently, without human intervention. Comparisons: Unattended RPA Attended RPA (RDA / HitL) Virtual digital employee working in background Assistant to human / Human-bot collaboration Focus on improving process efficiency Focus on improving employee productivity Ideal for process based automation Ideal for task based automation Bot executes complete transaction (Start to finish, end to end) Bot executes partial transaction and manually completed by human intervention Used for repetitive, more frequent and simple process Used for complex processes which requires human decision making Rule based execution Human/system triggered and involves manual inputs to execute the task Typically performs Batch Operation Mostly in attended RPA, it is transaction/Interaction wise and not batch based Works on preset schedule Real time or waits in queue for human processing Can run on work station, servers and on cloud Usually runs on work station / single employee's desktop Can complete end to end transaction and can work 24/7 Have to wait for human actions to complete the transaction. Running 24/7 can create bottleneck, in the waiting queue to close the task Apt for back office support More suitable for Front Office Support / Service desk / Help desk / Customer Contact Center, typically Customer facing roles Server to bot communication is automated process version deployment only Server to bot communication can be automated process version deployment, start or can reset processes Frees employees from routine mundane work, reduces cost and accelerates processes Increases productivity and customer service in service environments Can be scheduled from centralized server, remotely Mostly human trigger, real time and done on work station In the Human in the Loop Automation environment, there could be single or multiple human interventions, either in the start, mid or in the end of the event depending about the coded logics. Process Examples: Unattended Automation · Apt for back-office processes at scale · Invoice management system · Email management / Mass customer email (BFSI, Telecom, Healthcare) · Manual data entry / Data migration · Sales orders · KYC (Know your customer) · Payroll automation · Absence management · Expense management · Storing Customer details / Customer onboarding / Update CRM · Processing Express Refunds · Bank statement reconciliation · Letter Generation · Extract data from different formats/applications (from PDF, scanned documents, etc.) · Periodic report preparation · Update user preference (Opt-out communication) · Data updates and validation · Credit card application (seamless based on CIBIL scores) · Proof of delivery (POD) · Patient appointment scheduling (Healthcare) · Transferring b-cards to sales force Attended Automation · Apt for contact center operations / front office support · Extract customer data from CRM automatically during employee-customer interaction · Profit and Loss updates · Address change approval triggered by employee based on correctness and completeness · Compliance management (Human approval, BISO involvement) · Loan processing (Final approval from the Loan officer) · High value claim processing (Human authentication) · Quote-to-cash (document-based data extraction) · Procure-to-pay (document-based data extraction) · Source-to-pay (document-based data extraction) Below are some of the advantages for Attended Automation over unattended automation: · It is Agile · Comparatively user friendly · It removes real time data entry work · Improves team efficiency · Progresses team productivity · Improves C-SAT, NPS scores · It requires minimal setup · Deployment is Rapid · Achieves ROI swiftly To conclude, in an attended automation environment, automation does not stops, as it collaborates with human to complete the automation process. Take away: Organization can choose any of the RPA bot types and deploy as per the necessity and business needs. Nevertheless, having a unified platform (ideally Hybrid platform) to handle both attended and unattended bots would be a superlative choice. Both RPA and RDA are integral part of Intelligent Automation Suite. However, the primary objective of going for an Automation, is to have minimal human involvement in the business process flow, hence RPA has an upper hand compared to RDA.

-
Mohamed Asif Abdul Hameed replied to Vishwadeep Khatri's topic in We ask and you answer! The best answer wins!Both Tableau and Power BI are great applications for creating Dashboards and visualizing data. It is difficult to recommend one over the other as both the tools have unique features to offer. Selecting the right applications totally depends on specific needs of the workgroup. Such as, if the intension is Visualization (Visual Analytics), Tableau would be great pick and If the group is more interested in Predictive modelling and Reporting, Power BI offers great capabilities. Both tools are integrated with R & Python languages. As per 2021 Gartner Peer Insights (based on ~5881 individual reviews from Analytics and Business Intelligence market space), Tableau takes upper hand on the below capabilities: Interactive Visual Exploration Analytics Dashboards Publishing Analytic Content Embedding Analytic Content Quality of End-User Training Timeliness of Vendor Response Power BI edges over tableau in: Collaboration & Social BI Mobile Exploration and Authoring Self-Contained Extraction, Transformation & Loading (ETL) & Data Storage Self-Service Data Preparation Governance and Metadata Management Security and Use Administration Cloud BI Pricing Flexibility Ease of Deployment Ease of Integration using Standard APIs and Tools In my opinion, I have seen POWER BI to be comparatively easier, especially for new users who are not data analysts. Data scientist prefer Tableau over power BI, due to its advanced functionality in creating visuals

-
Mohamed Asif Abdul Hameed replied to Vishwadeep Khatri's topic in We ask and you answer! The best answer wins!Refactoring makes the code Nimble and Workable as continuous iteration is done. Note: It is not troubleshooting / debugging It is done by changing internal modules/structures in the software application to keep it simple, legible, understandable, efficient and change friendly without affecting the output. Code Examples: Before: Working Code extension Collection { func episodes() -> [Episode] { return Episode.all.filter { $0.collections.contains(id) } } } After: Refactored Code extension Collection { func episodes(for user: UserData?) -> [Episode] { return Episode.scoped(for: user).filter { $0.collections.contains(id) } } } When should team consider doing it? It is Rule of Thumb: 1. When developing the code for first time, JDI (Just Do it) 2. When repeating similar module for second time, do it anyway 3. When doing it for the third time, Refactor it Few general considerations for refactoring could be: When code is cumbersome When fixing a bug Code smells During code review Ongoing maintenance project (spring cleaning) Before adding a new feature to the original code TDD (Test driven development) After delivery on a tight deadline (Business pressure) Mismanagement Shortcuts taken during development Speeding up without writing tests for new feature Speeding due to wrong job size estimation (T-shirt Sizing) Can we avoid Refactoring? Refactoring is UNAVOIDABLE and it is Vital and Essential; however, if one is looking to avoid this can Develop a clean perfect code (Most Optimal State) Dump the Old code and start with New code, when developing features (Volatile environment)
-
Mohamed Asif Abdul Hameed replied to Vishwadeep Khatri's topic in We ask and you answer! The best answer wins!Japanese term "Mieruka" literally means making visible. Visual Management is a type of communication that facilitates group to track / monitor / follow up on key metrics and lets the organisation to manage the key performance indicators better. Objective of Visual Control is to convey process and production status in a visual form that is easy to interpret and the focus is more into Lean view point (5S, TIMWOOD) Various forms of visual control could be: Color Coding Andon Standard Work Floor Signage Kamishbai Board & Tee Cards These forms gives prominence to 3I 1P Identification Informative Instructional Planning Following 3 clear rules: Making it Easy to understand Big an visible Interactive and changeable Some of the direct benefits of visual control includes > Easy to have cross-functional collaboration > Goals are visible and aligned > Communication is straight forwards and streamlined > Improved morale and team health > Improves process transparency > High Team engagement Visual Control promotes team work by, Seeing as a Team Knowing as a Team Acting as a Team and it helps team to see the big picture. Visual control makes the flow transparent allowing to improve both efficiency and effectiveness of the system.
-
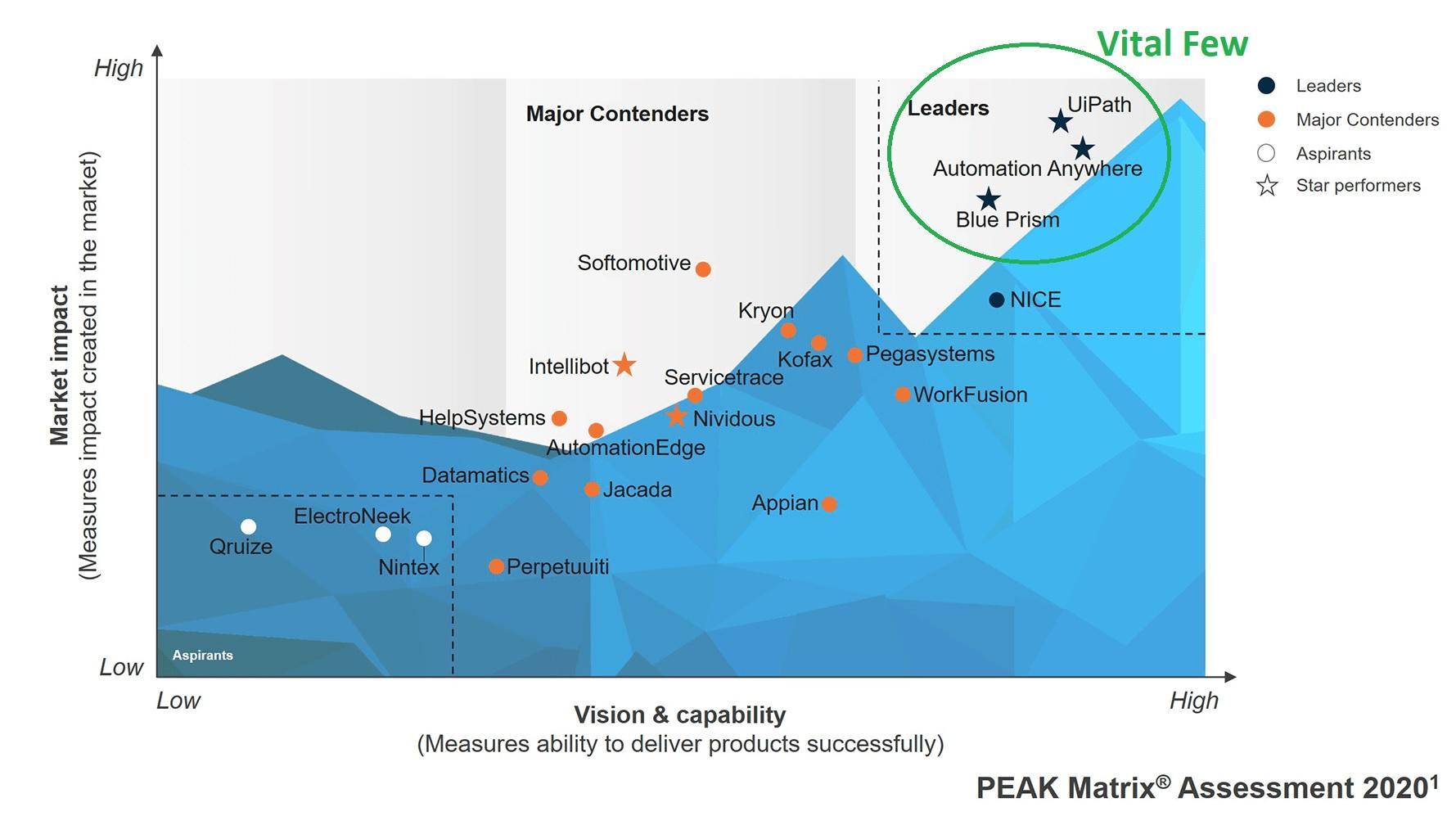
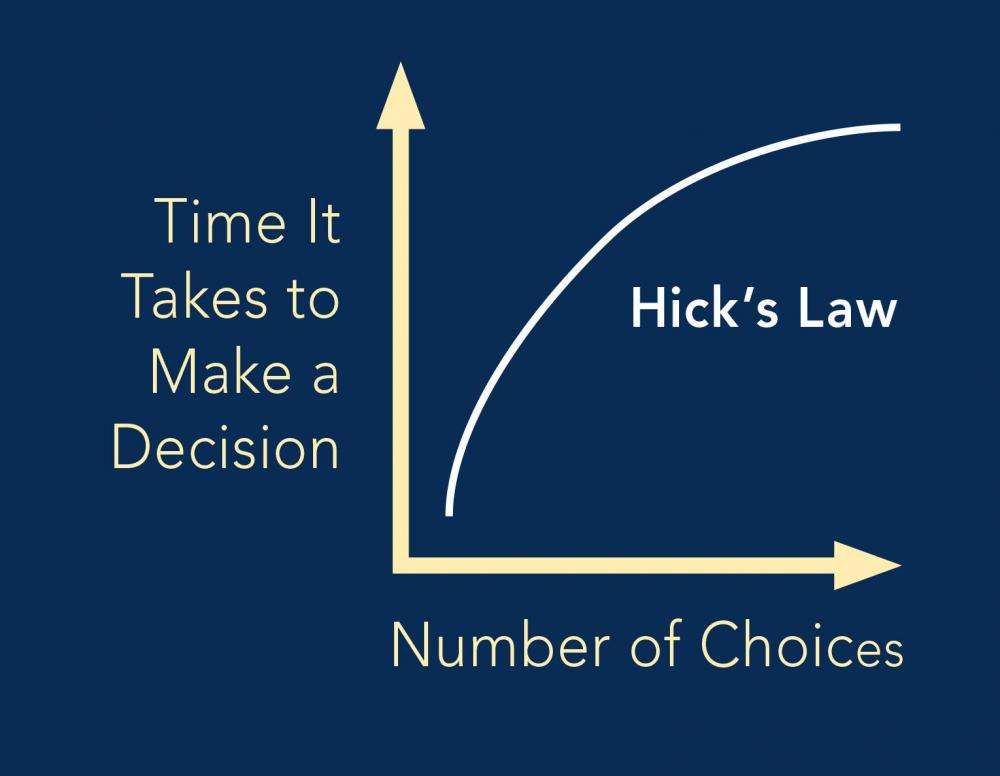
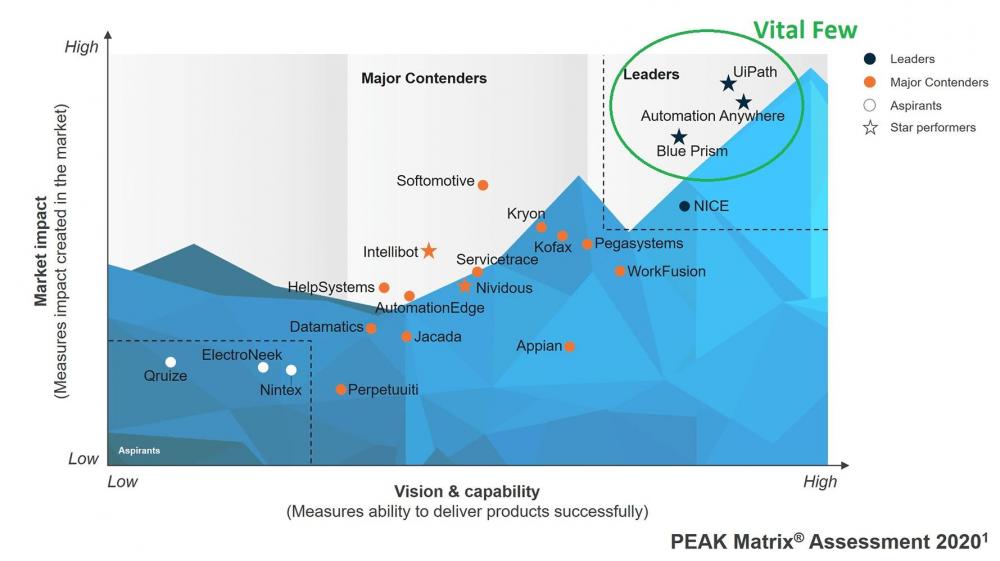
Mohamed Asif Abdul Hameed replied to Vishwadeep Khatri's topic in We ask and you answer! The best answer wins!Simply to put forward, Hick’s law states that, it takes more time to make decision, when there are multiple options to choose from. Key metrics associated with this law is time, choices, and complexity Let me start with a classical example of Zomato As the hunger strikes, we get into the app to order food. nevertheless, more time is spent on exploring the options available by scrolling top down, rather than ordering quickly. This can be very well referred to the expression, “Spoilt for Choices” Besides, as there are multiple platforms and multiple options available within those platforms. It takes considerable amount of time to finalize a close a deal. Especially, in food industry, multiple choices are essential in order to keep the consumers engaged. Below is the reference from Amazon for buying a mask However, on time critical projects, situation can make us “frozen” and make us unable to select one option in the heat of the moment. To overcome this situation, when the options are limited, the response time to make decision can be quicker. Critics often discuss on the effectiveness of this approach as limiting the option, still this could be a lifesaver, when we will have to make wise and rapid decision. Example from IT service industry, in case of tool evaluation, when there are multiple options, it could be more challenging in arriving at the best tool with regards to cost, ROI, robustness, scalability, flexibility to change and adapt. As the assessment could sometime be misleading and can run through months. Rather Categorizing Choice can help out, selecting the category out of star performers, aspirants, contenders and leaders. We can quickly get into the target group and make quicker decision. Picking the Vital Few and Selecting the best option. From a B2C scenario, to have better connect and engagement with the consumers, wide choices are obligatory to influence and keep them involved. Lesson learned from hick’s law: Despite the fact, there is no double, consumers love to make choices, but then again, having too many options can confuse in arriving at a conclusion. “More is not better! Except sometimes” So, for time critical project, please KISS (Keep It Simple and Straightforward)
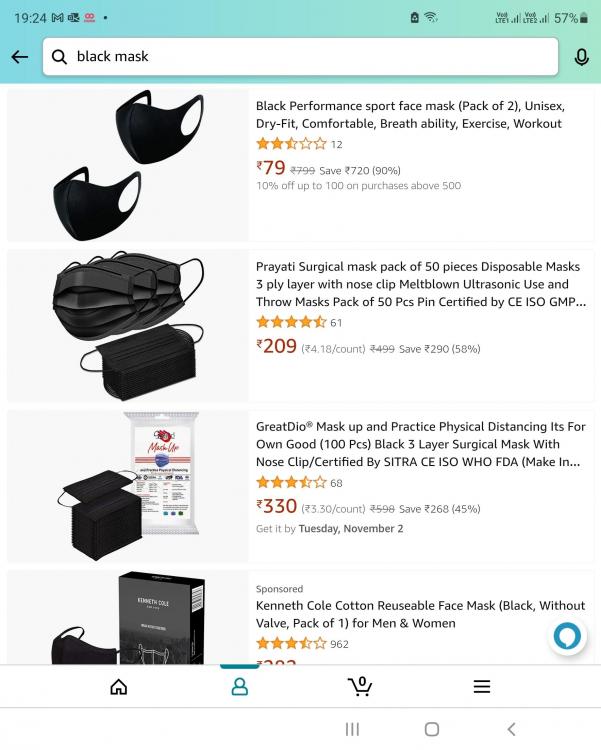

-
Mohamed Asif Abdul Hameed replied to Vishwadeep Khatri's topic in We ask and you answer! The best answer wins!Both Lean and Agile methodologies are flexible and focuses on continuous improvement and share common goals and principles, however the workflow is more iterative in agile Key differences with regards to both the methodology is that, Lean focuses on maximizing the efficiencies whereas, agile is more of maximizing the effectiveness Another paramount difference is flexibility. Lean is not that flexible when is comes to dynamic deliverable changes. However, dynamic requirement changes are effortless in Agile Few difference in various toolkits used is listed below. Lean Management - Daily Huddle meeting, VSM, RCPS, 5S, Visual Management Agile - Daily Stand up, Backlog, Sprints Lean methodology delivers Value; Agile delivers Working Product (wherein, small batch size is preferred to deliver rapidly) Even though there are considerable difference between Lean and Agile, both methodologies complements each other in most of the working situations and some of the commonalities including Improving Quality, Amplifying learning, Continuously improving and empowering people makes both approach collaborative. Choosing one over other is not pivotal as exploring what principles better suits the working model in the organization and incorporating them in the software development process matters.
-
Mohamed Asif Abdul Hameed replied to Vishwadeep Khatri's topic in We ask and you answer! The best answer wins!Time Boxing or Time Blocking is a time management tool/technique conceptualized by James Martin in his book “Rapid Application Development”, as a part of agile software development. Elon Musk further mastered and used this time management technique as a secret weapon for his success. This method is practiced by setting fixed amount of time for the required task and fitting the resulting time blocks into the schedule. In simple words, while planning, you try to estimate the time required to complete the task and place it in your schedule. Like that of Planning poker agile estimation technique. I use clockify desktop and mobile application, which has outlook integration feature, helps in planning my day better with improved productivity. Typical Reference: We allocate time for a planned task and work on the activity during the fixed time and end the activity once the time is up, post which assessing and reviewing the progress of the task on the completeness. As this is time bound, it helps in effective planning and completing the activity within the planned time. Thus ensuring, not over utilize time which is not required for the activity. Vital point over here is that, we will be able to protect our schedule against unnecessary intruders. However, at the same time we can review and modify the time plan on the go. Steps in Time boxing Technique: 1. Finding the task/activity 2. Defining Goal – DoD (Definition of Done) 3. Estimate and set the time 4. Work on the activity 5. Assess results and outcome 6. Claim your reward Time bound makes us more disciplined, by setting a firm deadline for the activities, we are essentially limiting the time, that we spend on it right from initiation of the activity. Benefits of Timeboxing: We are forced to work on unpleasant tasks We will spend less/fixed time on tasks We will work on tasks that are “too short” We will work on tasks that are “too long” We will stop being a perfectionist It boosts our motivation It creates a balance in our life Tips for Timeboxing: Determine the maximum timebox time Better Focus – No multitask at focused time Take breaks as an when necessary. Back to Back to Back meetings – Drains creativity Differentiate hard and soft timeboxes. Hard timeboxes are one-time activity, which doesn’t require follow up time Soft timeboxes involve larger tasks, getting broken down to smaller sub tasks and that would require follow ups Make time visual, to keep track of minutes Closing with Harvey’s Quote on using time wisely:

-
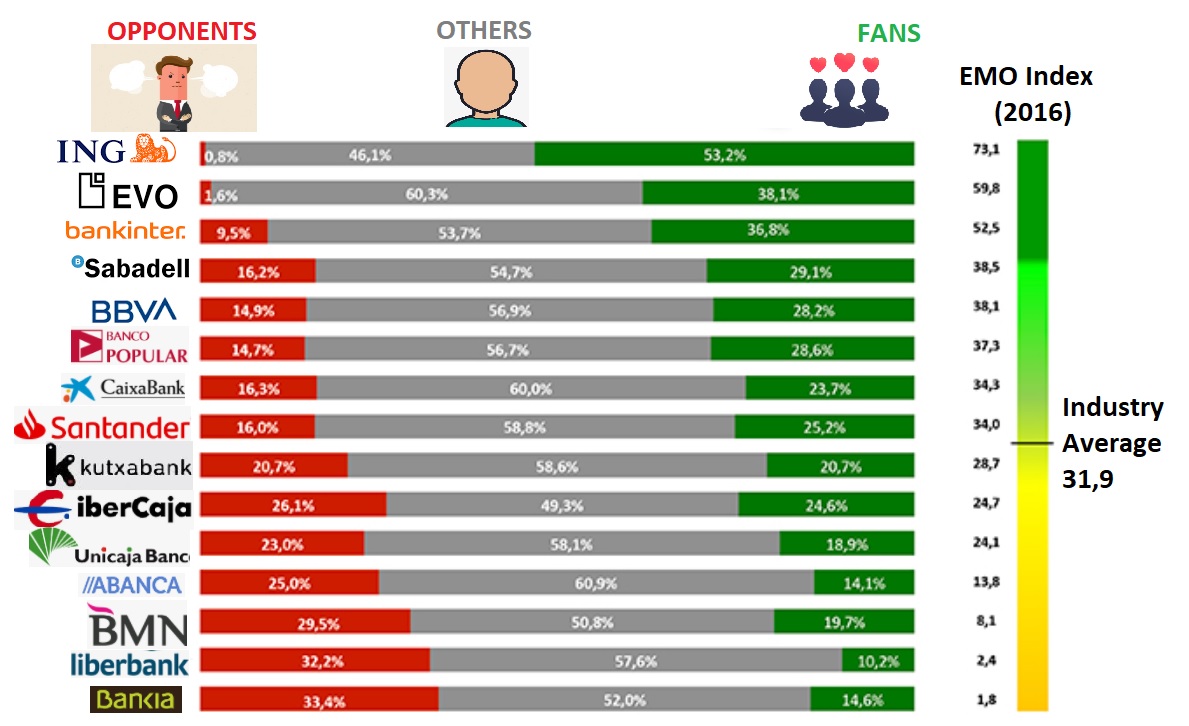
Mohamed Asif Abdul Hameed replied to Vishwadeep Khatri's topic in We ask and you answer! The best answer wins!EMO Index outlines the Emotional State (Emotional Footprint) of the consumer or group of customer towards a Company based on Positive(+) and Negative(-) emotions and their magnitude. This is examined on a scale of -100 to +100 based on their previous experience towards the Company. EMO Index can be closely compared with NPS (Net Promoter Score), which measures Customer Loyalty and Satisfaction measurement taken from customers, asking, how likely they are to recommend Companies product or service to others on a scale of 0-10. NPS is a measure of the percentage of customers who are promoters of a brand name or company, minus the percentage of detractors. At times, it is debated that NPS is a poor indicator to predict the growth of a company. On the contrary, EMO Index adds significant value in comparison with more traditional and simplistic classification approaches. Here in EMO Index, customer classification is done based on the emotional print associated with the Company based on the experience as Fans, Believers, Followers, Stand by, Lost Souls, Burned-out and Opponents. Modus operandi: To calculate EMO Index, primarily comprehensive analysis is performed to determine which emotions are relevant for the Studied Domain/Industry/Sector. Id ést, emotions such as Surprise, Happiness, Love, Irritation, disappointments, Anger, et cetera. Then representative sample of customers are identified and asked if they have experienced each of these emotions at any particular time in dealing with the Company. Emotional Levels are also measured parallelly with the possible reasons that may have caused them (Triggers). Customer are then classified as Fans, Believers, Followers, Stand by, Lost Souls, Burned-out and Opponents. Finally, emotional segmentation is introduced based on above said classification. This ties in with the power of emotions on the future behavior of the Customer. EMO Index is widely used in Retail Banking, Healthcare, Telecommunication and Advertising sectors majorly adopted in Spain and Latin America. Below is the example of a comprehensive study conducted by EMO Insights on popular banks in Spain. Ranking based on more fans than opponents. Integration of emotions in the models of decision-making improve their explanatory power tremendously. Any emotion, even those that are not directly related to decision-making, may have a significant impact on the opinion or final decisions. Measuring loyalty, satisfaction and emotions are much needed to keep the customer tied to the company in a long run.


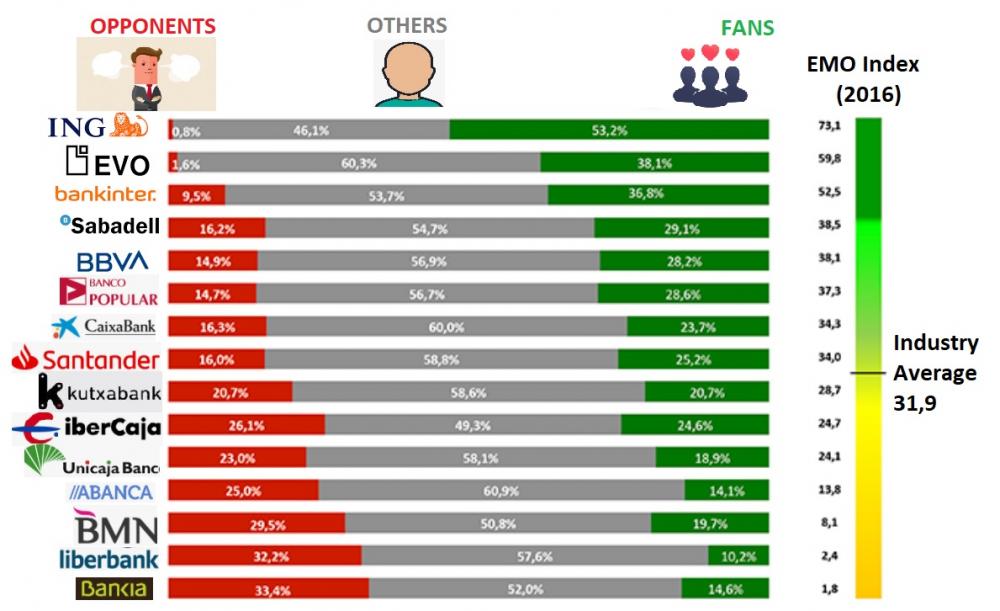
-
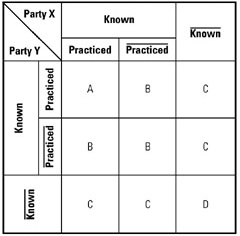
Mohamed Asif Abdul Hameed replied to Vishwadeep Khatri's topic in We ask and you answer! The best answer wins!CEDAC is Cause and Effect Diagram with the Addition of Cards - A Tool for Continuous Systematic Improvement introduced by Ryuji Fukuda. Dr. Fukuda effectively integrated various “Japanese techniques” like JIT, Hoshin Kanri, Kaizen with the “Traditional Knowledge” of Industrial Engineering, Statistical Process Control & Reliability and developed powerful tools such as, SEDAC - Structure for Enhancing Daily Activities through Creativity P/O matrix - Tool for Policy Deployment and On Error Training, Window Analysis & Stockless Production. CEDAC is a visual, team-oriented problem-solving tool which is a substantial improvement to the Ishikawa diagram. It outlines a structured method to work together, collect facts and define causes of a problem, then generate, document and systematically test out associated improvement ideas. CEDAC can be used on any problem that needs improvement, not only to those related to Quality Control. Idea generation and brainstorming is done during the meet, as well as outside of the meeting rooms, these ideas are collected on small cards. Cards are also used to gather inputs from employees who are not in the group and typically can be used/distributed with anyone who is involved in the Process. Here, the Improvement activity is promoted by Three Driving Forces, viz., Developing Reliable System Creating a Favorable Environment Practicing Together Proactively asking the below questions during the start of the project can ensure effectiveness of the plan. Questions such as, Do we have a Reliable System? Is the Environment favorable? Have the team members practiced the System enough? Below diagram is the summary view of CEDAC System Conventional quality tools assemble and integrates disorganized data into meaningful data points and to ease improvements Implementing countermeasures, confirming the results, standardizing and adhering to standards are essential. CEDAC system consists of three processes: Window Analysis (1st Stage) CEDAC Diagram (2nd Stage) Window Development (3rd Stage) Window Analysis - (1st Stage): This is used to determine potential root cause(s) of a problem. An extension to Johari’s Window Model. Selecting combination of Party X and Party Y is critical, depending upon the complexity of the problem it is decided. This technique questions any 2 parties, if a practice, process, or a set of work instructions is known and practiced in order to avert or minimize performance problems. This window enables to discover how functions are interacting, communicating and exposing gaps in understanding and process knowledge, from general to specific. Based on the scenario used, typical inference from the model could be as listed below, Company directives are followed. Company directives are not always followed. Company directives were not communicated to some parties. Company directives need to be communicated to make information available to all parties. These 4 categories can be summarized as below Category Description of the event Nature of the situation A Established – Known – Practiced Ideal situation B Established – Known – Unpracticed Problem with practice C Established – Unknown – Unpracticed Problem with communication D Not established – Unknown – Unpracticed Problem with standardization CEDAC Diagram - (2nd Stage): Fishbone diagram is used examine the cause of the problem Improvement Cards are used to figure out different ways of improving the process. Cards are of two types, fact cards and solution cards (placed next to the fact cards). Fact cards list the facts. Solutions cards list the generated ideas. Visual quantification is done by using charts to fix the target and monitor the progress. Based on analysis, solution cards are shortlisted and evaluated. Test results are studied carefully. “Dot System” is used in each possible solution to bucketize the solutions. Single dot (•) – the idea is of interest Two dots (••) – the idea is under the preparation Three dots (•••) – the idea is under the test Based on Dot system, ideas are implemented in the process. Window Development - (3rd Stage): This inspects the actions of CEDAC diagram and emphases on new standard compliance. So that each employee must understand the new standards clearly without ambiguity. Here numerical methods are used to appraise the effectiveness of the new standard. CEDAC is extensively used to improve and engage employee involvement in the organization. Typical applications include that of, For Production & Services • Lead Time Reduction in production & services • Inventory Reduction • Reducing Rework / Scrap / Errors • Increasing Yield • Reducing Time and Cost Overruns in projects • Cost Reduction For Administration / Sales Offices • Reduce Late coming / Absenteeism • Speedy recovery of receivables • Increase Orders to Enquiries ratio To summarize, CEDAC, Orients all the members of the organization, directs their actions by graphically presenting the project, and allows them to successfully contribute to the improvement process. Allows sharing of essential information with all associates, thus promoting autonomous actions. Encourages all individuals in the organization to use their strengths. Elevates chances to generate ideas that enable progress even by at least half a step, as it makes the members keep thinking. Integrates external knowledge and the member’s knowledge to create new ideas and technology. Standardizes thoughts and ideas with favorable test results and accumulates them as intrinsic and management technology.


-
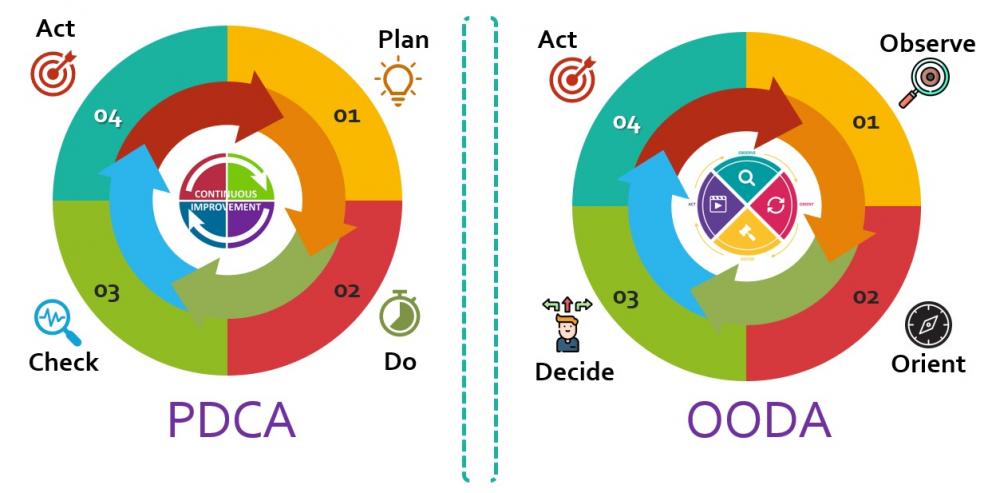
Mohamed Asif Abdul Hameed replied to Vishwadeep Khatri's topic in We ask and you answer! The best answer wins!PDCA - Plan, Do, Check, Act (Starts with Planning phase) OODA - Observe, Orient, Decide, Act (Starts with Observation) PDCA OODA Feedback is received after completion of cycle Feedback is received almost at all phases ( Orient, Decide, Act ) Focuses on the operational / tactical requirements Focuses on strategic requirements Pioneered by William Deming in 1950s Developed in the mid-20th century by military strategist PDCA Cycle is more of an analytical approach OODA is concerned with synthesizing an action out of an incomplete data set. PDCA is more moving from a reactive problem fixing model to a proactive one More Reactive - Implies on how to react to changes in circumstances and take new actions as quickly as possible. Used to take Preemptive measures Used widely for Incident response Usually longer cycles, iterative approach Usually short cycle and done in real-time PDCA is used extensively in Software development lifecycle, healthcare Industry, manufacturing and Service industries for new product development, for Project Management, and for Change Management. OODA is commonly adopted in business, game theory, information security, law enforcement, litigation, marketing and military strategy. OODA is essentially the same as the “Plan, Do, Check, Act” principle that is fundamental to all ongoing process improvement initiatives. Extended version of PDCA is OPDCA, "O" stands for Observation, it starts with Observing the current conditional and proceeds with planning, which is quite similar to that of OODA approach. PDCA (Benefits) OODA (Benefits) The iterative approach allows control and analysis Enables quicker, more streamlined decision processes. Powerful and Straightforward Tool and provides greater efficiency and effectiveness Brings more organizational transparency and situational awareness. PDCA (Disadvantages) OODA (Disadvantages) The unspecific definition can lead to incorrect use It can be difficult to understand or interpreted in various ways. Paralysis By Analysis, Changes must be planned over longer periods of time Can make it harder to “undo” a mistake. When we use both concepts together, PDCA and OODA, we would have higher quality level while making critical decisions. From a lean perspective OODA is similar to that of PDCA, but from CAPD order (Check, Act, Plan and Do)
-
Mohamed Asif Abdul Hameed replied to Vishwadeep Khatri's topic in We ask and you answer! The best answer wins!PDPC – Process Decision Program Chart PDPC spreads the tree diagram to successive levels to identify risks and countermeasures for the low-level tasks. PDPC is like that of FMEA in identifying risks, effects of failure and contingency actions. It throws light on what might go wrong (Risks/Failures), highlight the Consequence of failure (Effect), and come with Potential countermeasures (Risk Mitigation). PDPC helps prepare the contingency plans. It systematically identifies what might go wrong in a plan under development. Countermeasures are developed to prevent or offset those problems. By using this technique, we can either revise the plan to avoid the problems or be ready with the best response when a problem occurs. When PDPC is used: Before implementing a large or complex plan. When the plan must be completed on schedule/target. When the price of failure (Cost of Poor Quality) is high. Example: Improve Service Delivery How it is used: Build Tree Diagram for the proposed plan (high level View) 3 Levels – Objective, Main Activities For each of the main activities, brainstorming is done to see what could go wrong List the problems associated in the next level For the listed potential problem, brainstorm and come with countermeasures Highlight feasible actions/countermeasures as O and impractical measures with X (use criteria such as cost, time, ease and effectiveness to arrive at conclusion) Example: Below PDPC is build to execute Sales Pitch to the Client



-
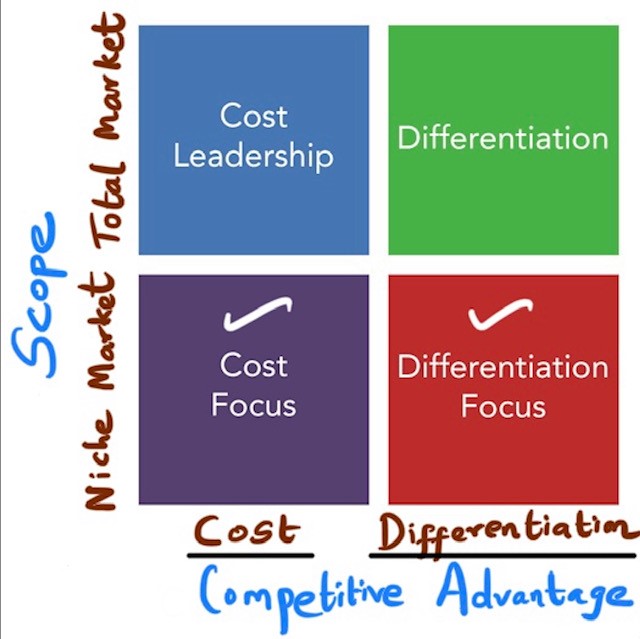
Mohamed Asif Abdul Hameed replied to Vishwadeep Khatri's topic in We ask and you answer! The best answer wins!Competitive advantage referred by Michael Porter is that for any Industry can have the competitive edge by pursuing in any of two unique ways, either → through Low Cost (Cost Leadership), or → through Differentiation and the third generic strategy is through Focus. He also points, failure to follow this strategy could end up stuck on the middle scenario and subsequently the organization might not be able to retain long-term competitive advantage over rivals. Below is Porter’s generic strategies model: Objective Cost Leadership Differentiation Focus Lowering selling/servicing price, by cutting cost of production/purchasing/service Offer Finest/First Class Quality product that can't be matched by rivals and charge a premium for this "Difference" Positioning the business in one specific niche in the market Examples Redmi, OnePlus Macbook, iMac Samsung: Fold (Differentiation), A/M Series (cost-focus) Cost Leadership can be achieved by: Setting facilities/resources to obtain economies of scale Improving productivity Keeping overhead cost minimal Low cost source supply Relocate to cheaper location. To Differentiate: Building brand Image Special features that stand out Providing exceptional service and user experience Below is an example in car industry: Hyundai’s cost leadership strategy depends on attracting a large customer base and keeping prices low. Mercedes-Benz builds its differentiation strategy around offering extravagance features and providing exceptional service. In a focused Cost Leadership, Morris Garage does not offer a full array of car lineup, but those that it does offer (SUV/MUV) are priced to cruise. Ferrari follows a focused differentiation strategy by assembling with exclusive materials and with finest craftsmanship for Niche market segments. Although there is a risk/disadvantages with any of referred strategies, Porter argues that a firm must pursue one of them to have competitive edge. Which one to select depends on market conditions and unique set of core competencies of the firm and thus closing this with his quotes.

-
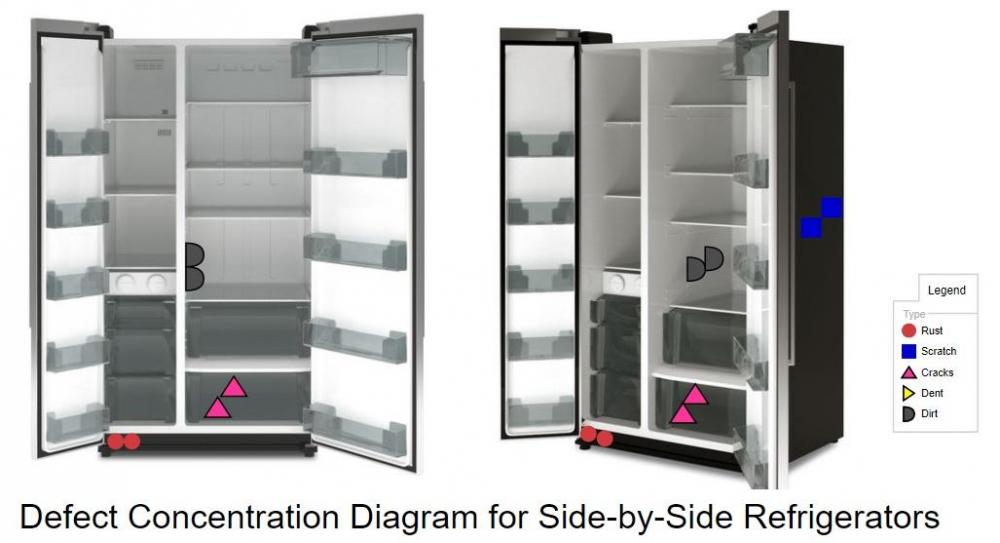
Mohamed Asif Abdul Hameed replied to Vishwadeep Khatri's topic in We ask and you answer! The best answer wins!Defect Concentration Diagram / Problem Concentration Diagram is one of the "Magnificent Seven" SPC tools. It is also referred as Location Plot or Defect Location Check Sheet. Defect Concentration Diagram is a graphical tool that is used in analyzing the causes of the unit defects. It can be used and applied to any process, it shows the picture of the unit/product (or item of interest) and associated defects in the unit, in all relevant views. Location and frequencies of various defects are clearly given in visuals. Defect data segregated based on location. The diagram is further analyzed to determine if the defect location of the unit provides any useful information about the potential causes of the defects. This is repeated with enough sampling of units, to study patterns of defect and to set the focus area of improvement. It is widely used during, Problem identification (data collection phase) When analyzing a part for potential defects When a part has multiple defects when problems arise after purchase of parts Defects to a large outspread affects shipping decisions and Defect classification is a vital step associated with Inspection. Based on the severity of the defect, it is usually classified as Minor, Major and Critical. Minor Defects - Don’t affect the function/form of the item Major defects - Affect the function, performance or appearance of a product Critical defects - Unusable and/or could cause harm to the user Analysis Actionable: Based on the study, it would help the product manufacture to make decisions like Asking supplier to correct quality issues – Ask for replacement of the supplied item Re-inspect – ensuring to correct the defects Callback products – Keeps customer safe Chargeback suppliers - Re-inspection and Re-work cost Destroy unusable goods - prevent defective goods getting into grey market It help to a great extend in product improvement for example, A smartphone manufacturer can analyze defect concentration diagram of unusable/defective smartphone which the customer returned during warranty to study the type, frequency, severity and also the pattern of the defects to strengthen and improve the smartphone in the subsequent release. Recent Advancement: Usually inspection is performed manually by human and it could be sometimes unstable and insufficient. Surface defects, such as scratches, cracks and dents are common during manufacturing process. Defect identification methods have improved a lot in recent times. One such improvement is Automatic Surface Defect Inspection System for Automobiles Using 3D Machine Vision Methods with integrated software’s which gives Defect Concentration Diagram in multi dimension. To reduce the number of Rejects, it is necessary to know not only the percentage but also the location and the types of defects. Defect Concentration Diagram is a great tool to locate the type, frequency, location and the pattern of the occurring defect.


-
Mohamed Asif Abdul Hameed replied to Vishwadeep Khatri's topic in We ask and you answer! The best answer wins!In this context, HiPPO refers to Highest Paid Person’s Opinion. HiPPO Effect in simple terms is when a group of people trying to make tough decisions and relying more on opinion rather than on data analysis. Executives at the top of the organizational pyramid, typically who are paid more, expresses what they think. It would be difficult to disregard Highest Paid Person’s Opinion and it would be risky in organizational environment. Below are some of the effects of HiPPO: Effect could be very subtle It could lead to Reverse Engineering, approaching from outcome and viewing at the data, resulting in losing/ignoring vital data sets It could be much riskier, when it is more like an order and less an opinion Possibility of declining idea trend Org wide, as the ideas and data analysis are not considered, conceived and materialized Loss of customer and goodwill due to unrealistic commitments (considering Ballpark estimates over realistic estimation techniques) Digital-native companies, including e-commerce, high-tech, telecommunication, consumer electronics, computer software and online service organizations rely more on data trends and have strong digital culture and vital information’s and decisions are informed by data and analytics. Administrators and Executives act on analytically derived insights and specifics, rather than intuition/experience or opinion. On the contrary many traditional companies are struggling with HiPPO’s and adopting big data and AI/ML initiatives still remains a major challenge. Few organizations have adopted data-driven practices and approach that would enable them in digital transformation. Most organizations have a long way to go in developing the data driven practices that enable them to realize the competitive edge. Below survey conducted by McKinsey shows the data and digital adaptability by various organizations and industries. Source: McKinsey, Nov 2018 Handling HiPPO: HiPPO Effect is the major barrier to data-driven decision-making. However, it can be handled and managed by using below steps: Having numerous engagement activities at various levels Creating digital culture Transforming core parts of business through digitization Having clear strategy in place driven by analytics Adopting to industry wide best practices Involving cross functional experts and consultants while making decisions Using decision making tools – Decision Matrix, Pugh Matrix, DACI Model, FMEA, Multi-Voting, Force Field Analysis, etc., Turning Assumptions to Hypothesis, running “Safe to fail” experiments to validate assumptions Certainty, HiPPO is one of the biggest deterrents to the use of data-driven decision making. However, it can be managed. Opinions aren’t Facts! It is just the medium between knowledge and ignorance


-
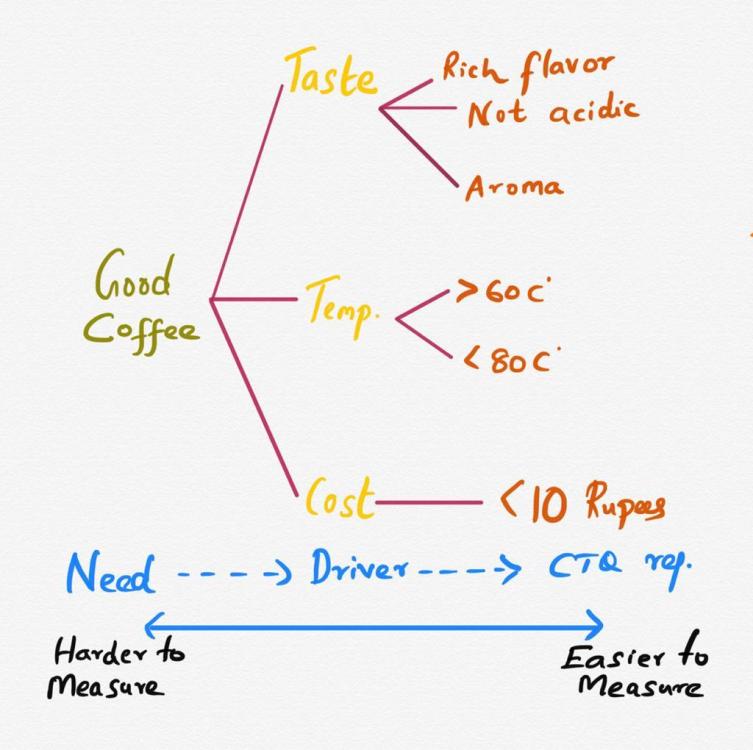
Mohamed Asif Abdul Hameed replied to Vishwadeep Khatri's topic in We ask and you answer! The best answer wins!CTQ (Critical to Quality) Tree is used to drill down to a more concrete project goal. It starts with wider project goal and works downwards to identify “Critical” factors that is required in achieving the goal. In simple words drill down generic goal, identify specific and measurable necessities to improve performance. It translates customer needs to Meaningful, Measurable, and Actionable metrics. Approach: Step 1: Identify Critical Needs "What is critical for this product or service?" Brainstorm needs with key stakeholders Step 2: Identify Quality Requirements Identify the specific quality drivers Identify all the requirements that are important Step 3: Identify Performance Requirements Identify the measurable performance requirements Points to remember before getting in CTQ tree. Identify customers Collect Voice of Customer data Analyze VoC data Prepare a list of CTQs Choose one CTQ and prepare a CTQ tree only for that CTQ. Components of CTQ Tree: Need it is the origin of CTQ tree, and it highlights the customer requirements Driver Drivers are the parameters on which a customer judges the quality of product. Requirements These are the measurable performance specifications that have to be met by drivers to satisfy customers. In order to make an effective and efficient CTQ tree, it is necessary to identify all the above components perfectly. Below is an example of CTQ drill down for a Good Coffee Benefits of CTQ: It highlights any weak areas in an organization where performance is below standard and helps in root cause analysis. It helps to identify private needs of the individual customer and recognize measurable performance requirements needed for specific customer’s satisfaction. Helps in the quality improvement of a product or service. Do’s while doing CTQ drilldown: Have Specific and measurable CTQs. Reflect input from primary and secondary customers (direct and indirect or stakeholders). Discuss business value of capturing and reporting a specific metric vs. cost (time and effort) of capturing that data. Delineate between metrics that exist currently vs. recommendations. For recommended metrics, discuss how they will be measured and reported. If a CTQ has no clear quantitative metric, discuss alternative ways of measurement (qualitative, other indicators). Common CTQ Errors: Missing elements of Speed, Quality, Cost, or Risk Metrics do not reflect measurement of the process product or outcome Metrics do not have solid Operational Definitions Metrics do not demonstrate how it is calculated Metrics are not at the appropriate level of detail Information in artifacts is not consistent Artifact created individually without consultation Artifact was created but no analysis was conducted CTQ helps to understand the customer’s general requirements in more specific terms.

-
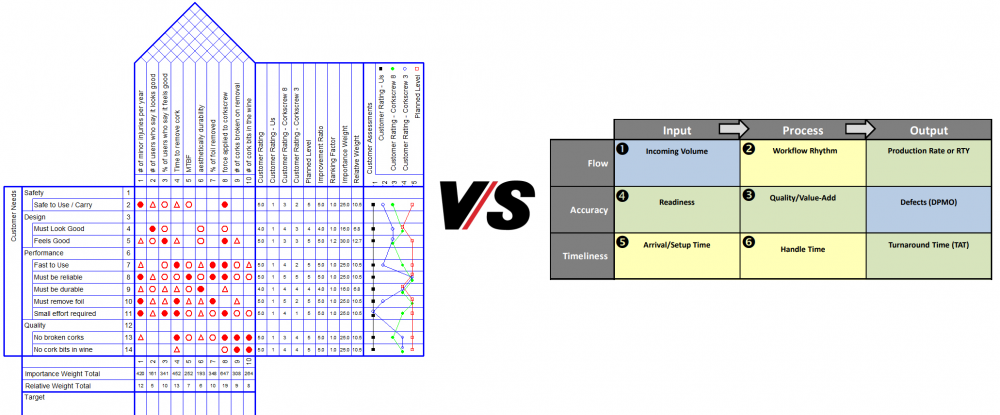
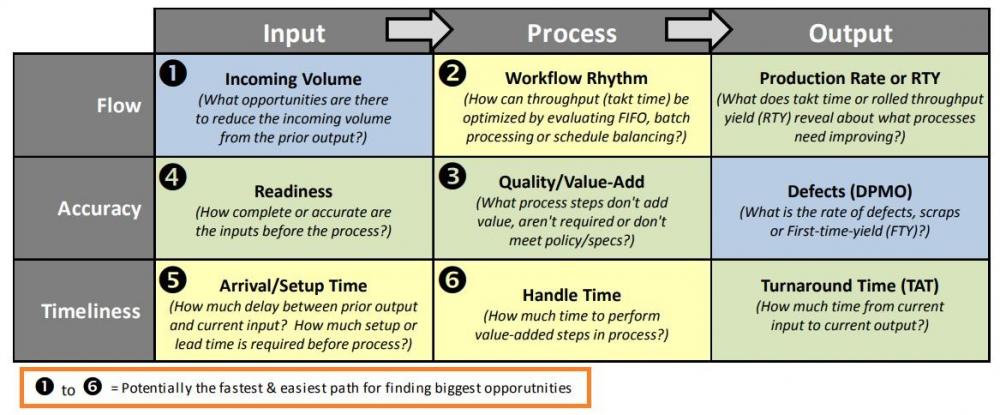
Mohamed Asif Abdul Hameed replied to Vishwadeep Khatri's topic in We ask and you answer! The best answer wins!IPO (Input-Process-Output) FAT (Flow, Accuracy, Timeliness) IPO-FAT is one of the effective techniques to evaluate and identify potential improvement opportunities in the service area. It is used to Identify and explore opportunities Brainstorm Pilot and device improvements Build control to measure and sustain improvements. As divergent to QFD which prioritizes existing and known opportunities, the IPO-FAT method can help a team to identify new and different opportunities which is not considered previously It is effectively used under listed scenarios: Issues/problems associated with critical and interrelated causes When we are not able to prioritize the problems When it is hard to identify focus area or start point It is also a very effective method of building and communicating project strategy. This tool priorities opportunity while using Lean/Six Sigma methodology for improvements. The color of each box helps us to identify which is the work methodology and improvement that best suits each element. Using IPO-FAT effectively can help in generating ideas through brainstorming and can subsequently help in identifying opportunity for improvements during the activity.

-
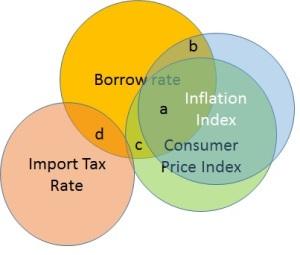
Mohamed Asif Abdul Hameed replied to Vishwadeep Khatri's topic in We ask and you answer! The best answer wins!Multicollinearity is a statistical phenomenon. It happens when several independent variables are highly correlated, However not perfectly correlated and In this situation we get regression results to be unreliable. In the above example, we could see how and to what extend does Consumer Price Index and Inflation Index can predict the rates. There is a considerable overlap between Consumer Price Index and Borrow Rate and Substantial overlap between Inflation Index and Borrow rate. Now, because there is a significant overlap between Consumer Price Index and Inflation Index themselves. It would be possible to predict with the unique non-overlapping contribution. Unique non-overlapping contribution of Consumer Price Index is Area c and Unique non-overlapping contribution of Inflation Index is Area b and Area a will be lost to standard error. Why Multicollinearity is considered as a problem? We would not be able to discriminate the individual effects of the independent variables on the dependent variable Further Correlated independent variables make it hard to make inference about individual regression coefficients and their effects on dependent variable. As a result, it is difficult to disprove Null Hypothesis, wherein actually the same should be rejected. Multicollinearity might not affect the accuracy of the model by a lot. But we might lose reliability in determining the effects of individual features of the model and that can be a problem when it comes to interpretability. How do we detect Multicollinearity? By using scatter plot or by using correlation matrix it would be possible to detect multicollinearity with regards to bivariate relationship between variables It can be detected based on Variance Inflation Factor or as popularly referred as VIF. VIF score of independent variable represents how well the variable is explained by other independent variables. When R2 value is close to 1, higher the value of VIF and higher the multicollinearity with the independent variable. VIF = 1 implies No correlation between independent variables and other variables VIF > 5, indicates high multicollinearity Diagnosis and Fix: Dropping one of the correlated features can bring down multicollinearity significantly Priority of dropping variable is based on the high VIF value Combining correlated variables into one and drop the others Points to remember before fixing: Removing multicollinearity will be a good option when more preference is given to individual features relatively to the group features that impact the focus variable Efficient corrective action to remove multicollinearity requires selectivity and selectivity in turn requires specifics about the nature of the problem.
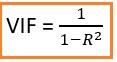
-
Mohamed Asif Abdul Hameed replied to Vishwadeep Khatri's topic in We ask and you answer! The best answer wins!自働化 - Jidoka - Autonomation Simply means process automatically halts when there are non conformities/irregularities/abnormalities in the system and it can also act as early warning device in manufacturing unit Andon light system is one of the Vital component in Autonomation. In the below reference pic, Andon is used as Visual Management tool to know the status of the production. Legend reference: Green - All Good, Normal Operation > Proceed further Yellow - Warning - Issue Identified, require attention > CAPA required Red - Production halted > Issue not identified; Immediate Supervisor inspection and RCA required Andon systems are commonly used in the below industries: Automotive manufacturing Packaging and shipping Retail Textile Inventory management Medical and Healthcare Example in healthcare: Visual Andon which include lights on Code Blue carts to indicate that they need to be checked for the day and intrusive computer screen alerts for pharmacists that indicate a patient allergy or contraindicated medication. Auditory Andon which beeps alarm on infusion pumps which gives signal stating medication is nearly gone or indicate there is defect with tubing and the audible alarm indicates acute medical emergencies Andon System has wide range of applications and below listed are few: It can Reduce downtime to enhance OEE It could significantly contribute to quality improvements due to shortened downtime Improved communication between operators and engineers Evaluating Incidents and instances from Andon events can lead to Poka Yoke applications Advanced system (@Next-gen Andon systems) can display KPI metrics and data with real-time embedded data Productions systems can be remotely managed by data flowing into tablets and smartphones Improved Productivity Reduced Lead-time Reduction in equipment failure rate Improved customer service Lower Costs However, there are few challenges as well, such as below which needs to be taken care High cost implementation Misunderstanding of automation leads to misapplication Difficulty of small enterprises hiring qualified staff

-
Mohamed Asif Abdul Hameed replied to Vishwadeep Khatri's topic in We ask and you answer! The best answer wins!Kubler-Ross Change Curve is a version for crossing the transition between - Change initiation to reaching overall goal. It describes the emotional journey that people undergo when coming across with change and transition. Below are the typical emotional change over’s Shock Denial Anger / Frustration Depression Experiment Decision Integration / Acceptance This can be viewed in 4 broad stages: Stage State Reaction Stage 1 Status Quo Shock, Denial Stage 2 Disruption Anger, Fear, Blame, Confusion Stage 3 Exploration Searching, Acceptance Stage 4 Rebuilding Commitment, Problem-solving People's reaction to pandemic is no different and resembles the below curve Critical learnings and take away from this transition that organization should adopt and look into would be to: Involve and engage people Put people first Move faster Reimaging value creation Communicate with transparency Working at the speed of customer Build augmented workforce strategy Reskill resources – Promote and facilitate digital learning Make processes and services mobile and flexible Adopting ecosystem mindset Embrace new technologies and data-rich technology platforms Empower leaders with judgement Turbocharge decision making Treat talents as scarcest resource Learn how to learn Change, adapt and innovate Not only adopting these at crisis situation, nevertheless it should be considered on-going basis to evolve, grow and achieve organizational success and it could possibly shrink the change transition timeline.
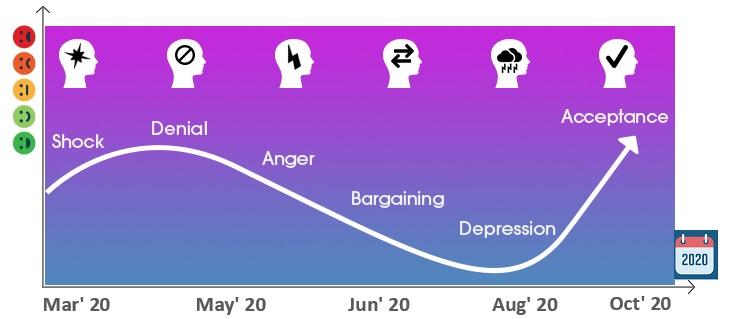
-
Mohamed Asif Abdul Hameed replied to Vishwadeep Khatri's topic in We ask and you answer! The best answer wins!In six sigma - DMAIC methodology goals should be SMART – Specific, Measurable, Attainable, Relevant and Time-bound and the goal of the project should be aligned to the issue/problem that we are trying to solve. A in SMART, Referring to - Attainable, Agreed upon, Achievable, Acceptable, Action-oriented Attainable is the important element and needs to be considered thoughtfully. Attaining defect % of less than 1% from 50% might not be possible in the due course of the project with out knowing the causes and the solution path. Below are few questions that can be asked while framing the goal.. Is 50% allowed? Accepted defect%? Cost of Poor Quality? FTR% Control measures in place Frequency of defects? Defect Detection methods? What is the financial Impact? What is the GAP? Actual Versus Desired How to ensure Quality at source (Quality by design, monitoring and control, self check and verification) Based on the response, aggressive but reasonable goals are drafted. One should have clear understanding of the current state (current performance – baseline) and the future state (desirable performance – target), do gap analysis to verify whether it is reasonable/possible while starting the six-sigma project and framing the goal statement. It is not hard and fast rule when it comes to the Goal statement. Entire project charter is a Living Document and can be revised/revisited as we get more clarity while we progress through the phases and during the iteration. To keep from overwhelming, goals should be fine-tuned/broken down into action steps and we should not try to take over the world in one night by setting unachievable goals. Few vital pointers with regards to Goal: • Achievable and Attainable – Practical with the assigned target value • Realistic – with the existing resource and available time • Action-oriented – defined plan of action Specifically Goal should be possible within the defined ability. Take Away: Achieving Goal is far more realistic when being Specific.

-
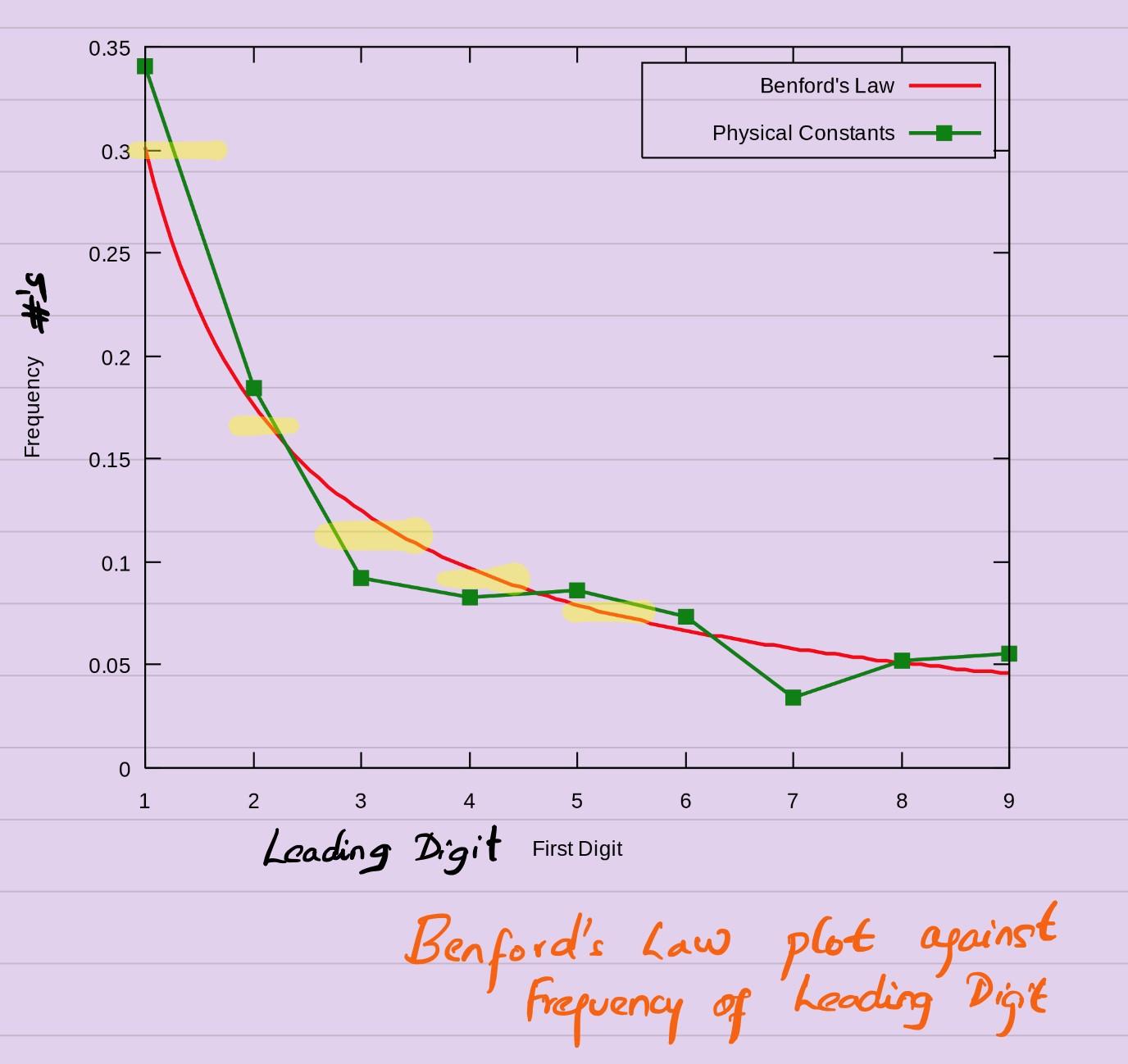
Mohamed Asif Abdul Hameed replied to Vishwadeep Khatri's topic in We ask and you answer! The best answer wins!Benford's law also referred as first digit law highlights about distribution of digits of randomly collected numbers to be in non-uniform way, especially the digit 1 tends to occur with probability of around 30%, which is much greater than expected 11.1% (1 out of 9 leading digits) Flip side, Non-naturally occurring data would have pre-defined number like Zip Codes or Universal Product Code (barcode symbology) for instance. Computer-Generated Numbers using Rand() does not follow Benford's law Scientifically, this Law is based on base-10 log that shows the probability that the leading digit of a number will be n can be calculated based on log10(1+1/n) This is specifically used in businesses and accounting services to detect fraud and have application in organizational and business environment and can be used while dealing with: General ledgers, Trial balance reports, Income statements, Balance sheets, Invoice listings, Inventory listings, Depreciation schedules, Investment statements, Expenses reimbursement, Accounts payable and Receivable reports, Timesheet data, Portfolios, Expense reports. In Risk based Audits: This law could serve as an early indicator showing abnormality in the data patterns Forensic Audits: Checking frauds, bypassing threshold limits, improper payments Financial Statement Audits: Manipulation of checks, cash on hand Corporate Finance: Examine cash-flow forecast for profit centers It is widely used by Income tax agencies, auditors and fraud examiners to detect abnormal patterns It works when, we have large data sets we have equal opportunity for metrics considered and we don't have definitive proof No build-in minimum or maximum values are in the data set Insurance Industry: In US, general accounting office has estimated fraud accounts for up to 10% of annual expenditure on health care or $100 billion in the US. In health insurance industry, there is a large amount of claims data submitted by health care providers. Benford's law can be used to analyze and detect abnormalities in the data. We can use Z-statistics to determine the difference between the actual and expected proportions and check for their significance. One can use this tool as a method of detecting possible fraudulent or errant claims received on behalf of health insurance company. Closure Points: Benford's Law is an excellent tool to predict the distribution of the first digit in a large population of data, given that the data has not been inferred with human touch.
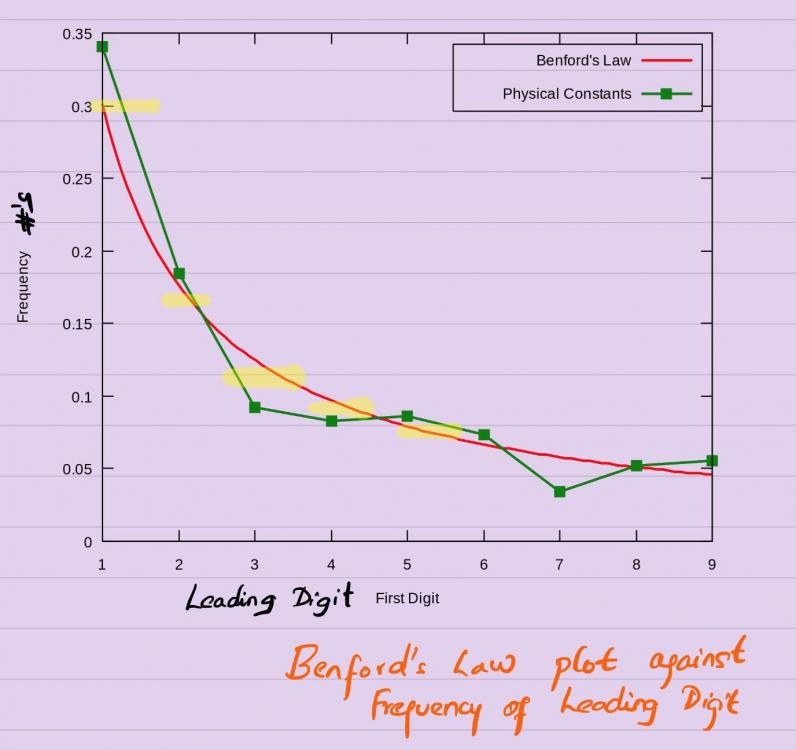
-
Mohamed Asif Abdul Hameed replied to Vishwadeep Khatri's topic in We ask and you answer! The best answer wins!Decision Making can be combination of Logic and Emotions. Analysis paralysis is Overanalyzing/Overthinking (Drowning in Data) Extinct by Instinct is taking decisions by Gut reaction (Disregarding the Data ) Overanalyzing or Overthinking can hinder the productivity It lowers performance on mentally demanding jobs There is high possibility that overthinking can kill creativity It pulls willpower of the individual It makes people less happy Organizations carrying excessive formal analysis is labeled as “dialogue of the deaf,” the “vicious circle,” and the “decision vacuum.” AI and ML tools can help in interpreting big data and it can be wisely leveraged in this technology era rather than overanalyzing. Some tips to overcome Overthinking: Structure and Plan decisions that matter the most Deliberately limit information intake Set a target deadline for Research Focus on primary objective and try not to deviate Discuss, collaborate and be open to take inputs from others Approach problem solving with an iterative mindset and Finally, practice making decision quickly On the other extreme, Extinct by Instinct, that is decisions without assessment and just by Gut feeling can be Fatal. Fatal is all aspects, For example: Stepping over the line in personal relationships Lack of spending control in Finances Ignoring the impacts in Health Not using wisely, the Time Malcolm Gladwell argues in his book, Blink, that the quick decision–the “snap” judgment–is much maligned. Below is the reference grid indicating problem solving and decision-making styles. Organization’s should leverage technology and wisely make decision. It should not get drenched into data pool as well as not discount the data. Quote "If you spend too much time thinking about a thing, you'll never get it done" – Lee At the same time, Quote “Quick decisions are unsafe decisions” – Sophocles

-
Mohamed Asif Abdul Hameed replied to Vishwadeep Khatri's topic in We ask and you answer! The best answer wins!#KeepItSimple If you have got the Bright idea, you have to cash it to get it go. Elevator pitch is the term used for less than 2-minute presentation, the time it takes to go from Lobby to the office floor, used to catch the attention and interest of the sponsor. Points to remember: Keep it simple and put it effortless and natural No need to close the deal in the elevator pitch, it’s all about grabbing interest Keep it ready, set and prepared Below are 10 Do's and Don’ts that can keep your pitch SMART. Do's: First and Foremost, Practice your presentation Start the pitch with a Vibrant Compelling Hook Be Positive Structure your USP Be confident Do take it slowly Have Data/Numbers to back your idea Maintain eye contact Have a quick takeaway point Keep it to a minute or less Don'ts: Don't be too fast Don't use Jargon/acronyms that might get you off track Don't focus just on yourself Don't hesitate to update your speech as the situation changes Don't be robotic (monotone way) or sound that you have memorized Don’t oversell or undersell Don't sound too salesy Don't restrict to a single pitch, have different versions Don't wrap up early if your listener is more interested or their eye's glazing over Finally, don't forget to say "Nice to Meet you" End lines, referring to the quotes from great physicist

-
Mohamed Asif Abdul Hameed replied to Vishwadeep Khatri's topic in We ask and you answer! The best answer wins!With reference to Weight of Ox, Galton discovered that average guess was awfully close to the actual weight. Sporadically, it makes sense to go with guess from crowd intelligence, specifically when there is no scale, or when the measurement is expensive or when it is time-consuming for accurate measurement. Few considerations and points to be factored before we rely on this method would include the below pointers: Diversity of opinion Independence of opinion Trusting the group to be fair in terms of giving the opinion Should be cautious of Groupthink Consideration on activity time Distribution of expert panel is important to avoid dominance and skewness Diffusion of responsibility We still use similar versions of Wisdom of Crowds in organizations. Ref 1: When we do Story Point Estimation in Agile development During development, it is critical and vital to plan budget, time and resource required to complete the module in every sprint. Entire project is broken into different levels and function point analysis and story points is assigned to each user stories. Story point estimation gives rough estimation (more like a guess) for the product backlog items with relative sizing. This is a comparative analysis. Key estimators include developers, testers, scrum master, product owner and other related stake holders. Some of the common estimating methods are T – shirt Sizing Using Fibonacci Series Animal Sizing Typical measures used in T – shirt sizing comprise XS, S, M, L, XL, XXL; In Fibonacci sequence measures includes numerical 1,2,3,5,8,13,21,34,55, etc.; In Animal Sizing team uses Ant, bee, cat, dog, lion, horse, elephant, etc. It’s fun to use animals instead of numbers Based on the efforts required, points are assigned for the stories during planning. Quick and effective way of using crowd intelligence while doing story point estimation. Ref 2: Delphi interview technique This method relies on expert panels decision, considering opinion from experts more like that of getting crowd intelligence in wisdom of crowd Ref 3: Group Decision Support System (GDSS) Many organizations use this method for idea generation, to select optimal solution, for voting and so on. By using this technique, it easy to arrive at solution for complex problems Other effective methods and applications includes below, Brain storming Nominal group technique Devil’s advocacy Fish bowling Didactic interaction Closing quotes to go with Wisdom of Crowd.