Mokshesh
Members
-
Joined
-
Last visited
-
Issue Tree Issue tree is a management tool used to solve complex business problems. Issue tree diagram approach helps in breaking complex problems into smaller manageable problems. This helps in tackling a large problem by effectively managing the smaller problems. This approach gets its name as ‘Issue Tree’ from the fact that it helps in breaking large problem into branches of smaller problems like a tree structure shown below: Benefits of Using Issue Tree 1. It makes it easier to solve complex problems by decomposing them into mutually exclusive and collectively exhaustive smaller problems 2. It provides a systematic roadmap to solve all the problems and effectively perform causal analysis to understand which few smaller problems when solved are yielding maximum beneficial results (80/20 principle) 3. It helps in prioritizing the problem solving process by focusing on critical smaller problems first and non-critical ones to be picked up later 4. It helps in dividing the problem solving work by grouping the logically related problems into one bucket and assigning it to relevant team for solving it Different Types and Uses of Issue Trees in Problem Solving Issue trees are of primarily two types, viz. diagnostic issue tree and solution issue tree. Diagnostic issue tree tries to answer the “Why” part of complex problem and Solution issue tree tries to answer the “How” part of a complex problem. An example of Solution Issue Tree trying to solve a complex problem of “How to Increase the profits of a lemonade business?” can be illustrated as below: References https://hackingthecaseinterview.thinkific.com/pages/issue-trees https://en.wikipedia.org/wiki/Issue_tree


-
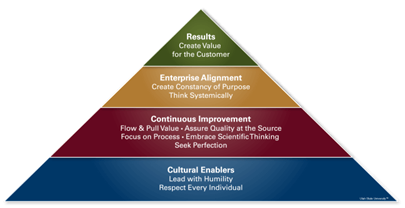
Shingo Model for Operational Excellence Any organization is always under a state of constant transformation. The critical ingredients to success of any transformation are the principled leaders and their clearly defined objectives behind any transformation. The Shingo model of Operational Excellence emphasizes that a successful transformation occurs when leaders create a deep culture of continuous improvement and take personal responsibility in architecting a long-lasting culture of continuous improvement. The most important contribution of Dr. Shingo was his theory on the relationship between principles of leaders, systems and tools in building the organizational culture and driving the results. Over the years many leaders have given extreme importance to systems and tools and neglected the aspect of leadership principles in building the right culture. Application of Shingo Model to build sustainable culture of Continuous Improvement Based on Shingo’s model, the building blocks for a successful and sustainable culture of Operational Excellence is divided into 4 dimensions as shown in the pyramid below Dimension 1: Cultural enablers Dimension 2: Continuous process improvement Dimension 3: Enterprise alignment Dimension 4: Results There are 10 guiding principles of Shingo Model to establish a sustainable culture of continuous improvement. They are as follows: 1. Lead with Humanity – A leader must possess sense of humility. A leader who is willing to seek inputs by listening carefully and continuously creates an environment where employees put their best creative abilities. 2. Respect for Individual – Respect for every individuals must be deeply felt by leaders in an organization 3. Focus on Process – A leader must acknowledge that most of the issues related to defective outcome is rooted in an imperfect process and not people 4. Embrace Scientific Thinking – A persistent practice of systematic exploration of ideas and failure reasons enables organization to understand reality 5. Flow and Pull Value – Value for customers is created there exists a real demand (Pull) and a continuous process (Flow) to fulfil that demand 6. Assure Quality at the Source – Right first time at every step of process can assure quality at the source 7. Seek Perfection – Perfection must be a habit and not an effort to create a mindset and culture of continuous improvement 8. Create Constancy of Purpose – There must exist a firm clarity of why the organization exists 9. Think Systematically – Thorough understanding of the relationships within a system must exist to understand cause and effect systematically and take decisions for improvements 10. Create Value for Customers – Value must be defined through the perspective of what a customer is willing to pay for References https://shingo.org/shingo-model/#headline-66-117 https://the-lmj.com/2012/05/the-shingo-model-for-operational-excellence/

-
What is OTED? Continuous improvement professionals have constantly strived to reduce the time taken for changeover. Single-minute exchange of die (SMED), is a technique to figure out how changeover can be accomplished in lesser time with less motion. One-touch exchange of dies (OTED) is an aggressive version of SMED. While SMED is usually termed to any changeover done in less than 10 minutes, OTED advocates that changeover must happen almost instantly with just one touch or in single step or in less than a minute. Why is OTED difficult to implement? 1. It takes more and more effort to improve any process. Every effort to improve a process comes with an additional cost. It becomes important for an organization to decide if there is any value addition happening by improving changeover time from SMED to OTED. Many companies may not be willing to improve changeover process from less than 10 min to a 30 sec process unless they see a substantial value add in doing so. 2. OTED is advanced and challenging. Most of the time, to implement OTED, a complete change of process, machine design and human skill sets are required. The cost required to make these complex changes and cost to sustain them may outweigh the final benefits expected. The cost to benefit ratio shall be much higher making such improvement propositions unviable. 3. OTED becomes really valuable if the changeover time across the process (including the upstream and downstream process) follows OTED approach. If this is not the case then benefit of OTED will not be realized. Suppose a situation where a changeover at more than one point is required in a production assembly. Having one step changeover (OTED) at one point and multiple step changeover (SMED) at other point will not speed up the overall changeover. 4. OTED is also more important for big/complex machines. However, in a lean setup the usual practice is to keep multiple simpler machines throughout the assembly line. These simpler machines usually have lower upkeep costs and designs are relatively simpler. This negates the requirement of OTED approach. 5. The take away with OTED as a lean tool is that it should not be used for the sake of using it. CI professionals must make sure to understand the flow of the process and system and overall cost benefit of expected improvement idea before attempting to use a sophisticated tool like OTED. An example where OTED is achieved The popular example where changeover time is truly less than 30 secs is the process of tyre change for F1 racing cars. Here changeover is done at the pit stop with a single motion instead of multiple steps. The need to implement OTED arises as a time difference between a winning and losing team can be in fractions of seconds. Implementing OTED here clearly explains that benefits outweigh the cost/effort of implementing it. Below modifications in entire process are done to achieve OTED in F1 racing cars. 1. Steps requiring adjustments are eliminated 2. Machine is redesigned to achieve freedom from time consuming steps like screw fastenings 3. Focus on precision is utmost and parts are designed to fit in almost instantly without errors 4. Highly skilled pit stop crew with hundreds of hours of practice 5. Process is redesigned to ensure multiple tasks can be done simultaneously and in same amount of set time 6. Strong 5S is implemented as a pillar to support the entire lean approach of OTED References https://www.velaction.com/one-touch-exchange-of-die-oted/ https://www.leansixsigmadefinition.com/glossary/oted/

-
What is a Shadow Board? As an organization which is practicing lean principles, a shadow board becomes an important means of implementing continuous improvement practices and eliminating wastes. Shadow board is a simple and inexpensive tool to organize workplace tools in a production (manufacturing) and service environments. A shadow board helps in organizing and storing tools, supplies and equipment at appropriate locations close to the work area or work stations. Shadow board helps in eliminating waste, such as: 1. Time for searching appropriate tool. 2. Wasted time in looking for interchanging tools and parts between tasks. 3. Identifying missing or broken tools/parts for re-order. 4. Identifying missing tools or parts for production. Shadow boards are also used in the sort and set in order stages of the 5S implementation at a workplace and during kaizen initiatives. Shadow boards can be of different sizes and located in many different areas of a process or plant. The key is that they are appropriately located and hold all the necessary tools for the area or work station. An illustration of a shadow board is as shown below: Benefits of Shadow Board at Workplace Shadow board offers below benefits that helps in improving the workplace. 1. Helps in keeping right tool at right place at right time for doing right work. 2. Increases accountability amongst the shop floor employees to keep the work stations clean and identify missing parts. 3. Correct storage of tools leads to increase in useful life and savings of cost in long run. 4. Facilitates quality control through visual management. 5. Supports segregation of department and production line specific tools and simplifies the work station maintenance by putting right tools where they belong to on shadow board. 6. Improves safety at workplace when tools are accounted for and kept back to the designated place on shadow board. Randomly left tools can lead to accidents and injuries. 7. Frees up space by de cluttering the work station when all tools are kept back to its designated space on shadow board. 8. Promotes the culture of care, ownership and cleanliness which are essential for building a successful continuous improvement culture. References http://www.leanmanufacture.net/operations/shadowboard.aspx https://www.flexpipeinc.com/us_en/shadow-boards/

-
What is Heinrich's Accident Triangle? The accident triangle was developed by H.W. Heinrich, an American industrial safety pioneer in 1931. He was an assistant superintendent working with an insurance company when he worked on his theory on behaviour based safety. His work was an important foundation to the safety philosophy in 20th century. He proposed that there is a numerical relationship between near misses, minor injuries, and major (or fatal) injuries at a work place. His theory was further updated and expanded by Frank Bird in late 1960s and hence also called as Bird’s triangle. In their research, both Heinrich and Bird stated that, if the number of minor accidents (or near misses) is reduced then there will be a corresponding fall in the number of major accidents. Heinrich did an extensive study on 75000 accident cases from insurance company’s database and industrial safety records. Through his analysis he proposed a relationship as below: 300 minor injuries/accidents -> 29 minor injuries/accidents -> 1 major injury/accident He drew the conclusion that, there exists a “domino model” of events that works on principle of “linear causal model” with a mathematical relationship as shown above. He further stated that, by reducing the number of minor accidents, industrial companies would see a correlating fall in the number of major accidents. The relationship is often depicted in the form of a triangle (shown below) and hence called as Heinrich’s Accident Triangle. How Heinreich’s Accident Triangle helped in industrial safety? Heinrich’s study showed that: 1. A lower-severity event can be used to predict a future fatal event within the same work place. Or in a simpler way, if a work place has enough near misses then the same workplace will eventually face a serious injury. 2. 95% of work place accidents were due to unsafe work practices and behaviours of workers and management. 3. Many accidents share common root causes (often near miss accidents). Hence addressing more minor accidents that cause no injuries can prevent accidents that can cause major injuries. 4. When employer focuses on what workers do, analyses why they do it, and then applies a research-supported intervention strategy to improve what people do will create a safety partnership between management and employees to prevent major accidents/injuries. This partnership is called as behaviour based safety (BBS) approach. 5. BBS program must include all employees, from the CEO to the front line workers as changes cannot be done without buy-in and support from all involved in safety related decision making. At the core, BBS is based on organizational behaviour management. Limitations of Heinrich’s Accident Triangle Heinrich’s ideas were considered sacred, until Fred Manuele, challenged the validity of Heinrich’s Law. Manuele through his theory claimed that if small incidents are managed effectively, the rate of occurrence of small incident declines, but the probability of major accident rate stays the same, or even slightly increases. Many more experts including Deming further criticized Heinrich’s theory owing to following reasons: 1. Ratios postulated by Heinrich (1 : 29 : 300) do not work when applied to specific activities and sectors. The method used to develop said mathematical relationship itself is unclear and being questioned. 2. Classification of incidents into major and minor by Heinrich could be skewed by the fact that not all minor incidents have outcome of same gravity. Due to this skewness, a minor incident may get classified as near miss or vice versa. 3. Underreporting of minor incidents or near misses by front line staff or their managers can cause skewness in reporting. This can significantly weaken the approach to implement Heinrich’s triangle approach. 4. Heinrich’s theory when practiced, led to excessive focus on the minor accident prevention, at the cost of losing sight of potentially major accident causing activities. 5. Heinrich’s triangle has an excessively simple approach of behaviours leading to incidents/accidents. It excessively focuses on training and procedural compliance. 6. Heinrich’s belief that behavioural aspects leads to mistakes tends to put up excessive blame on individual or group of people for any failure incident. 7. Heinrich’s theory adopts a linear model of causality which is inappropriate to explain the failure of modern complex systems. Complex systems fail in complex ways. 8. Heinrich’s model focuses on actual accident outcomes of various magnitudes and lacks focus on risk potential of various magnitudes. Methods to Overcome Limitations of Heinrich’s Model 1. Near misses and minor incidents must be assessed in light of injury and fatality potential. For example, a near miss of worker from falling in an empty reactor vessel v/s falling into a tank of acid storage must be assessed in light of injury and fatality potential. 2. Focus should be built on eliminating incidents with high potential of injury and fatality. 3. Approach to consider behavioural mistake at the core of every incident must be changed. Thinking that a flawed process or a poor system design can cause incidents must be instilled. 4. Approach of process re-engineering and system/equipment re-design to avoid incidents must be adopted instead of constantly working on improving human behaviours. Shifting from Baka Yoke (fool proofing) to Poka Yoke (mistake proofing) ideology. 5. Adopt complex causal analysis using tools like “Why Because Analysis/Graph”, “Event Tree/Fault Tree Analysis“, FMEA, etc.. to understand the failure of complex systems instead of relying on simple linear causal model (domino effect) to address the potential risks. References https://risk-engineering.org/concept/Heinrich-Bird-accident-pyramid https://www.skybrary.aero/index.php/Heinrich_Pyramid https://thinkinsights.net/strategy/heinrich-law/ https://en.wikipedia.org/wiki/Accident_triangle

-
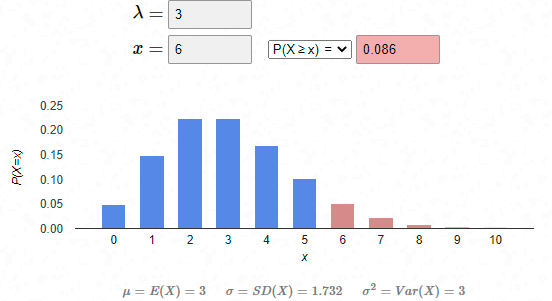
What is Poisson Distribution? Poisson distributions is amongst one of the most practical distributions in answering many of the questions of the modern world. Being used more than a century now, this probability distribution has been useful in solving various problems from medical, banking, agriculture, defence, mining, space research, service and manufacturing industries. Poisson distribution is named in honour of French mathematician and physicist Simeon Denis Poisson. It is a discrete distribution because it shows probabilities of countable distinct values. In simpler terms, this distribution does not take all values in a continuous range. The distribution takes the values 0, 1, 2, 3, 4, etc. with no decimals and fractions. The formula of Poisson distribution is as below: Where, x = 0, 1, 2, 3…. λ is a real number and the expected value of x e ≈ 2.718 Understanding Poisson distribution A Poisson distribution is useful in estimating the probability that something will happen "X" number of times within a given time period. For example, if the average number of students who bunk the tuition class on a public holiday is 5, a Poisson distribution can answer questions such as, "What is the probability that more than 10 students will bunk the classes on a given public holiday?" The application of the Poisson distribution thereby enables tuition teachers to introduce optimal lecture schedules that would not work with, say, a normal distribution. Before applying the Poisson distribution, there are few conditions to be satisfied as below: 1. x is the number of event that occurs in an interval and x can take values 0, 1, 2, .... 2. The occurrence of one event does not affect the probability that a second event will occur. That is, events occur independently. 3. The probability an event occurs is the same throughout the entire time interval. Understanding Poisson distribution and its application from work area (Insurance) (Numbers used are dummy for educational purpose) The number of death claims received per day at an insurance company follows a Poisson distribution. The company receives an average of 3 death claims per day. The claims department needs an expert claims assessor to assess each case and settle the claims within promised timelines. The current staff size is capable to manage daily 5 cases. The department manager is allowed to recruit more staff if the probability of receiving more than maximum manageable cases exceeds by 20%. As a department manager, you would want to evaluate if you are eligible for fresh recruitment in department or not. You may use Poisson probability distribution to answer this question. In this case, λ =3, hence the Poisson distribution for our case becomes as below: ----- (equation 1) The question states you to calculate the probability of receiving more than maximum manageable cases i.e. more than or equal to 6 cases (X≥6). In this case, the probability using Poisson distribution will be calculated as below: Inserting x = 0,1,2,3,4,5 in equation 1 above, we get answer as below. Since the probability of receiving more than manageable cases is less than 20%, the department manager is not eligible for a new recruitment in the department. Visually, one can represent the above Poisson distribution problem as below: Bibliography: https://www.investopedia.com/terms/p/poisson-distribution.asp https://en.wikipedia.org/wiki/Poisson_distribution https://towardsdatascience.com/poisson-distribution-from-horse-kick-history-data-to-modern-analytic-5eb49e60fb5f https://homepage.divms.uiowa.edu/~mbognar/applets/pois.html
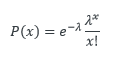
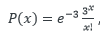
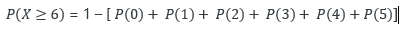

-
What is RICE Scoring Method? RICE scoring is a prioritization framework or a decision making tool that helps product managers to figure out what to build from the pool of available product ideas and what is the highest priority at the moment. This framework uses a simple formula of reach times impact times confidence, all over effort. The acronym RICE is derived using the initials of these factors used in the model. Mathematically it can be represented as below: Let’s understand how to use the RICE scoring method and understand the 4 components with and example: 1. Reach is the estimate of how many people you think your product will ‘reach’ in a given time period. The product manager has to decide both score and definition of ‘reach’ along with the time period in the context. For example: Let’s say a product manager with a credit card division of bank has 4 different discount offer ideas for increasing the spend of their credit card customers in the festive season of November month. Here, time period is 1 month and let’s keep definition of ‘reach’ as the number of credit card customers eligible for the discount offer. The score of ‘reach’ against each discount offer will be the count of customers that are eligible for an offer in 1 month as shown below. Discount Offer Type Reach Score Impact Score Effort Score Confidence Score RICE Score Offer A 45,000 Offer B 75,000 Offer C 30,000 Offer D 60,000 2. Impact is the qualitative goal defining the expected conversions when the product reaches your target customers. For the example of discount offer for credit card, it’s like asking the question “How many customers will spend using the credit card when the discount offer reaches the customers?” In RICE scoring method, the impact is a five-tiered scoring scale as below: · 3 = Massive impact · 2 = High impact · 1 = Medium impact · 0.5 = Low impact · 0.25 = Minimal impact Discount Offer Type Reach Score Impact Score Effort Score Confidence Score RICE Score Offer A 45,000 3 Offer B 75,000 0.25 Offer C 30,000 2 Offer D 60,000 0.5 3. Effort is the estimate of total number of resources required for completing the initiative in a given period. For the example of discount offer for credit card, it’s like asking the question “How many man-days (or man-months) of efforts will be required to roll out the discount offer?” The effort includes everything like design of discount, discount system configuration, campaign launch, marketing mailers design, agreement signing with discount partner, etc. If the estimated effort is 25 man-days then effort score will be 25. Discount Offer Type Reach Score Impact Score Effort Score Confidence Score RICE Score Offer A 45,000 3 45 Offer B 75,000 0.25 50 Offer C 30,000 2 30 Offer D 60,000 0.5 65 4. Confidence is expressed in percentages and is the estimate of how sure are you about your reach, impact and effort scores. This number varies from 1 to 100 percentage and usually defined as a three-tiered scoring scale as below: · 100% = High confidence · 80% = Medium confidence · 50% = Low confidence Any confidence score of less than 50% must be considered a “moon-shot” initiative and must be dropped to focus on other initiatives. Discount Offer Type Reach Score Impact Score Effort Score Confidence Score RICE Score Offer A 45,000 3 45 80% Offer B 75,000 0.25 50 100% Offer C 30,000 2 30 80% Offer D 60,000 0.5 65 50% RICE Score Calculation and Interpretation By filling up the above table, one can arrive at the RICE score using the formula as stated earlier. The initiative with highest RICE score becomes the priority for product manager to work upon from the list of available ideas or choices. In below table, we see that Offer A is the priority initiative for our example. Discount Offer Type Reach Score Impact Score Effort Score Confidence Score RICE Score Offer A 45,000 3 45 80% 2400 Offer B 75,000 0.25 50 100% 375 Offer C 30,000 2 30 80% 1600 Offer D 60,000 0.5 65 50% 231 Benefits of using RICE model: 1. It’s a scalable tool and can be helpful in prioritizing and decision making in any kind of business problem apart from product launch. This is because the RICE score is a form of cost-benefit score with ‘R x I x C’ as benefit and ‘E’ as cost. 2. It gives a method or a framework for prioritization and decision making using data rather than emotions. 3. It is a comprehensive methodology and helps prioritize ideas that may have been overlooked. 4. It can help in finding quick wins. Challenges of using RICE model: 1. The product manager will have to garner all the possible ideas to put them into the RICE framework for prioritization. If this is not done thoroughly then the model will prioritize an inefficient idea. 2. It’s time consuming as product manager has to evaluate each options against the 4 criteria before calculating final scores. 3. The model is constrained to use impact and confidence criteria for prioritization. This can lead to elimination of an idea that is important for an organization, yet low on impact and confidence. 4. The data for calculating all the 4 criteria aren’t always easily available. This makes RICE scoring difficult. 5. Human bias may deter the rational scoring of all 4 criteria in absence of accurate data leading to false prioritization. The results will be flawed if the criteria are flawed. References: https://www.productplan.com/glossary/rice-scoring-model/ https://medium.com/swlh/rice-scoring-model-for-prioritisation-88d879bfbac0 https://ascendle.com/ideas/why-the-rice-prioritization-framework-actually-works/
-
Scope change in DMAIC approach should be allowed up to Analyze phase. After define stage, both measure and analyze phase are exploratory in nature. While measuring the current process performance and analyzing the critical X's impacting the Y, a project team may end up discovering additional insights about the overall process (including upstream and downstream process). It is therefore justifiable for a project team to alter the scope at these stages for successfully completing the project. A need for change in scope at improve and control phase may arise in some scenarios. However, during such instances it is better to scrap the overall project and start afresh instead of continuing it under the pretext of scope change.
-
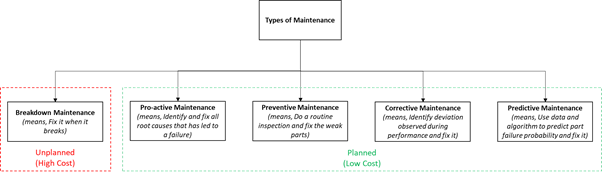
Let us understand the concept of Jishu Hozen systematically and also understand the key levers for its successful implementation. Maintenance can be defined as series of efforts taken to restore the condition of any mechanical object (or a machine) in order to get the desired productivity from it. To achieve the desired productivity, a machine must: a. Be available (no stop time) for operations as per planned time b. Perform (as fast as possible) as per expected cycle time, and c. Produce quality (only good parts) output as per the standards defined The above criteria gives rise to the concept of overall equipment effectiveness (OEE). An OEE of 100% indicates that a machine is producing only good parts as fast as possible without any stop time. Thus, it becomes clear that, maintenance of a machine is important to achieve a 100% or near to 100% OEE. Let’s take a quick look into the below diagram on types of maintenance to understand what a productive maintenance means. In the primitive days of industrialization, there used to be a separate maintenance department for performing the ‘breakdown maintenance’ upon failure of the machine. The production team was focused only on achieving the production targets. With the increasing complexity of the machines and increasing competitiveness (cost pressures), the industries could no longer cope with breakdown maintenance strategy. Industries gradually matured and moved towards planned maintenance strategies. A careful observation at various planned maintenance strategies in above chart confirms one thing for sure – that “a planned maintenance cannot be a job of an isolated maintenance department personnel, but has to be a jointly achieved by involving production department personnel as well.” Therefore the responsibility for maintenance tasks was partially transferred to production employees. This is how the term “Productive Maintenance” evolved. With rapidly changing technologies and practices, the element of continuous improvement in productive maintenance led to emergence of “Total Productive Maintenance” (TPM) One can now self-define the objective of TPM as “A continuous effort towards maintaining and improving overall equipment effectiveness by engaging those that use and impact the equipment.” Jishu (自主, autonomous) Hozen (保全, maintenance) is a Japanese term that translates into “Autonomous Maintenance”. Since TPM depends on involvement of production team to maintain OEE, it becomes evidently clear of having Jishu Hozen as one of the pillars of TPM. The main goal of Jishu Hozen is to empower and enable the employee to make a daily conscious efforts to maintain the performance of equipment. In order to enable the employee to do so, Jishu Hozen can be effectively implemented by implementing below key levers: 1. Improve knowledge of operator: Operators are masters of running their equipment. In order to get an optimal output from machines, they must know in and out of it. Therefore constantly training them on equipment anatomy and improving their problem solving skills will help. 2. Implement machine cleaning & inspection practices: Train operators to clean the machine and restore it to original state after use. Also operators must be empowered to perform daily inspection and do corrective maintenance. 3. Improve accessibility: Operators should be able to access the machine and its components easily in order to perform the inspection and maintenance while working on it. Therefore improving the layout to aid the accessibility must be done. 4. Eliminate cause of contamination: Operators must be encouraged to identify the source of contamination which soils/damages the equipment. Necessary steps must be taken to eliminate the cause of contamination. This will ensure that their daily maintenance and inspection task becomes easy. 5. Promote visual maintenance: Visual technique is an important element in implementing autonomous maintenance. Visual techniques makes it easy for operators at all level to understand messages without speaking in a loud operating environment. 6. Develop and implement standards: Create standards for training operator and inspection procedures based on type of equipment. Implementing the standards will ensure a systematic approach in long run. 7. Implement continuous improvement: A period practice to dissect the standard processes and check for room for improvement is important for sustaining autonomous maintenance. This practice can help in designing new machines and making new designs even easier to access and maintain. 8. Reward and Recognition: Congratulating operators and rewarding them suitably for doing a good job will help in promoting and sustaining Jishu Hozen in a healthy way.
-
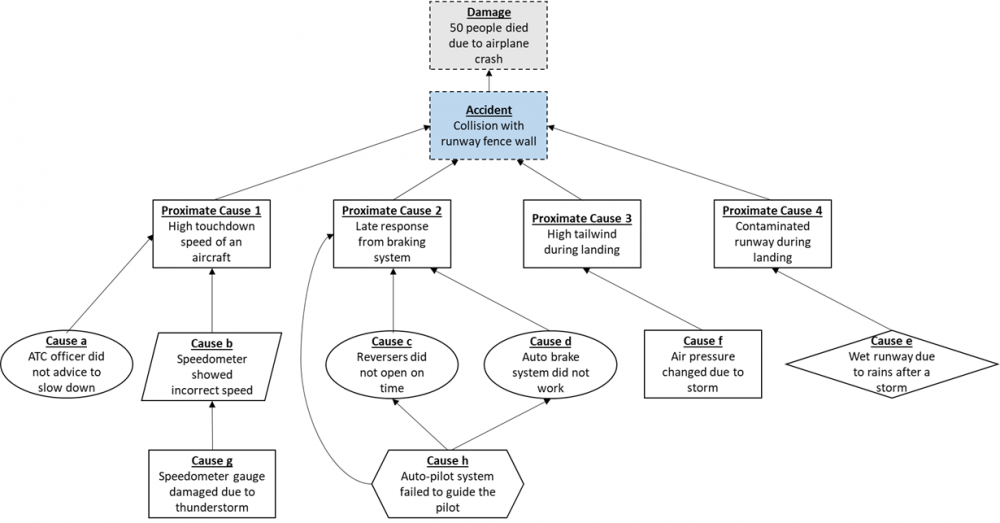
Q) Why Because Analysis (WBA) is a variation of 5 Why analysis which is particularly useful in accident causal analysis. Explain WBA along with its output Why Because Graph (WBG) with an example. Answer: What is a ‘Why Because Analysis’ (WBA): Accident causal analysis (or incident investigation analysis) is a type of posterior analysis which uses inductive reasoning to develop a theory which can give a satisfactory causal explanation of the accident (incident) being analysed. Causal analysis is one of the many methods available for performing accident (incident) analysis. With modern engineering, humans are able to build advanced systems that can fulfil a complex task. However with the advent of sophisticated systems, it has become intellectually difficult to do the failure analysis of complex systems using traditional causal analysis method. Let’s understand this with an example. Suppose that there is a standalone computer (a simple system) which has failed to start. A causal analysis using conventional ‘5 Why’ analysis method could be something like as shown below. The above causal chain shows a simple cause-effect relationship which may be sufficient for simple incidents. But suppose that the computer is part of a complex network, with connection to other computers, servers, internet, external devices, human operators and changing environment. In such a situation if a computer shuts down suddenly while operating then it becomes difficult to do an incident analysis with a simple cause-effect relationship. Complex systems show a complex cause and effect relationship and requires a more rigorous approach to causality. One has to not only assess the individual components, but also the interactions between them. What adds to the difficulty is that, at times, many complex system failures have been observed even without the breakdown of individual components of a system. Why-Because Analysis (WBA) as an alternative causal analysis method was therefore developed by Everett Palmer, a research engineer at NASA Ames Research Centre (California) to perform the failure analysis of such complex, open and heterogeneous system. The term ‘open’ means that the system’s behaviour is highly affected by the environment in which it is operating and ‘heterogeneous’ means that system has many components that must work together for entire system to function smoothly. In fact, Everett Palmer made the Why-Because Graph (WBG) first which led to development of WBA then. Understanding a ‘Why-Because Graph’ (WBG): Accident analysts use a Why-Because Graph (WBG) to map the complex cause and effect relationships. WBG is essentially a directed acyclic (non-circular) graph to respect the laws of causality. Let us understand some concepts & terms to be able to make a WBG for an accident analysis. 1. Counterfactual Test (CT): WBA uses a rigorous notion of causality known as counterfactuals. British empiricist David Hume in his theory of causation propounded the counterfactual test. He argued that two occurrences are causally related as cause and effect if they pass this test. Test: X is a cause for Y, if and only if, had X not occurred, Y could not have occurred. To apply this test, ask this question: If X had not happened, could Y had happened? If the answer is ‘No’, then X becomes the necessary causal factor (NCF) for Y to happen. If the answer is ‘Yes’ the X is not necessary for Y to happen. Y would have happened anyway. Here importantly, we must understand that while X is a necessary factor for Y to happen, it alone may not be sufficient for Y to occur. This brings us to our next concept as follows. 2. Causal Sufficiency Test (CST): In CST, the objective is to decide whether a group of causes are sufficient for an effect to happen. Test: X1, X2, X3…..Xn are causally sufficient for effect Y to happen, if and only if, Y inevitably happens when X1, X2, X3…..Xn happens. Summing up both the above tests, one can say that the group of causes under consideration creates an effect only when both CT and CST are positive. A positive CT indicates that each cause is necessary and a positive CST indicates that all listed causes are sufficient for an incident to occur. 3. Accident: An accident is an occurrence that results in a significant loss and is within our area of interest. Let’s represent this with a blue dotted line rectangular box. 4. Damage: The loss occurred as an outcome of an accident is termed as damage. Let’s represent this with a grey dotted line rectangular box. 5. Factors: Factors are the set of causes that are considered to be responsible for an accident and the resultant damage. Factors can be broadly classified as Events, Process, Un-Event, State and Assumption. Let’s understand these briefly: a. Events: Events are simply the changes that have happened in the system. Ex: In a car as a system, if the speed changes from 50 km/hr to 60 km/hr, then this acceleration is called as an event. Let’s denoted it by a rectangular box. b. Process: They are sequence of similar events. Ex: If a car increases its speed incrementally from 50km/hr to 51 to 52….60km/hr, then this sequence of similar events is called as a process. Let’s denote it by a parallelogram. c. Un-Event: An un-event is an event that should have happened, but did not. Ex: A car crossing a red signal is an event. But if you carefully think over it, then it is an un-event. Let’s denote this with an oval. d. State: State is a condition that is true across the events and process. Ex: A car must stop before the red signal is a condition that is true over the various events and processes. Let’s denote this as by a diamond shape. e. Assumption: These are factors that do not have enough evidence to support a cause but are important as a part of causal sufficiency test. In an on-going investigation, these assumptions are loose ends which can be resolved as a real factor as investigation progresses. Let’s denote this by a hexagon shape. f. Proximate Causes: All those factors that immediately precede the accident are termed as proximate causes. These factors are primarily some events or processes as explained above. Now let’s understand an example of WBG using above terms and concepts that we learnt. (Below WBG is a simple diagram for learning perspective and does not indicate complete analysis of any real investigation) Let’s assume that each cause (factor) in the above WBG has passed the counterfactual test (CT) as we move from bottom most factor to the accident node. Also, let’s assume that all these factors have passed the causal sufficiency test (CST). One can now say that above WBG is a complete representation of cause and effect analysis behind failure of a complex system. What follows after any cause and effect analysis is the finding of countermeasures to avoid occurrence of these set of causes to avoid the future accident and damages. In an advanced WBG practice, the analysts also place the countermeasures as one of the factors to check if they are efficient enough to avoid various factors, especially the un-events.