Ashish Kumar Sharma
Members
-
Joined
-
Last visited
-
Ashish Kumar Sharma replied to Vishwadeep Khatri's topic in We ask and you answer! The best answer wins!Inventory turns is the measure of the number of times inventory is used in a given time frame. The rate at which inventory is used, sold or replaced is Inventory Turnover Ratio. Inventory in stock and be always available, is preferred from a management stand point but for only those who overlook the working capital / cost invested in purchasing, storage and safety of the inventory. From financial perspective, manufacturer would want the inventory to be used for finished product at the earliest and the finished product be sold out in the market, improving the cash flow cycle will allow them to make another investment. Faster the inventory is put to use, less are chances of incurring extra warehouse / storage cost, loss due to staleness or theft or breakage. Extra inventory has an inverse relationship on the profit margins and to worsen the situation pressure on increasing sales cost may leave no market for the product. Inventory Turns can be put to a ratio by using a formula, as below: = Cost of goods sold or Cost of raw material / Average Inventory · Cost of goods sold = Units sold * Unit Selling Price · Inventory Cost = Average Unit in stock during period * Cost per unit Higher the ratio better it is. Higher ratio signifies that the sales is faster in comparison to average inventory cost. While it depends on the framework or Operations management decision of keeping the stock but most of the matured industry will keep Inventory Turns be around 5 to 10. Dependent on sales number, inventory to be consumed between 1-2 months. A smaller inventory ratio (2-4) or reduced turnover ratio will recommend that either sales team are able to place the product correctly in the market or may be the product is no more a customer choice. Inventory Management over a period of time has provided some best practice strategy – Pull, Push and JIT strategy. While Pull and Push gets a self explanation, ask for inventory when u need and move the product inventory from one stage to another, Just In Time is most advanced form of inventory management, it requires precision and most accurate calculation of lead / takt time, the goods are received from supplier only when the sales order is confirmed and the product needs to be manufactured in time. The objective is to reduce the inventory holding cost and maximize the Turns. JIT is most effective when the cost of maintaining inventory is high and the production model is optimized to deliver the product right in time to the customer. There are some techniques and to name few of the most popular - Consignment, ABC Inventory Management, Material requirement planning. Basis Management decision and need base, ideal technique supports optimizing Inventory Turns. If put to right use, Inventory Turnover is an excellent ratio to make Management Decision. Calculating Inventory Turns over a period, guides the management to know if the product sales is in line with the production pipeline. Higher Turnover means inventory will not be on hold and finished goods has an immediate market. Market Trend Analysis Sales Forecast and Inventory Turns have a tight bounding, If the sales prediction number is on increase trend for future, management can plan how much inventory will be needed. This will ensure that inventory shortage, sourcing or blockage is taken care of. Managing Inventory Keeping the right inventory is line with sales, makes sure that the Company saves associated cost, more working capital for other priority. In turn, Customer gets fresh product and better quality. Management can decide on the Selling price and may take advantage over competition. Improved Margins and manage price stability Stakeholder can evaluate Manufacturing unit efficiency and reward / comment back on the product managers competency. Afterall all owners would want to reduce the inventory level without impacting Sales. Evaluate Management Efficiency Using Inventory Turnover for making decisions has its own risk, especially when in uncertain market, VUCA world, The numbers can be manipulated and lead to an incorrect submission. This average formula, somehow do not highlight the slow-moving inventory parts and hence may restrict the management to better performance. Plus, most importantly, what if the inventory is reducing or is less of? There may be short term appreciation for High Inventory and might be company miss the opportunity of optimizing Sales due to restricted finished good supply. Management is well aware of the fact that if the inventory is periodic or dependent on various influencing availability factors, they may have to pay more on buying small portions or during high demand. “Less off and More off” – both have challenges and keeping the right balance is the key to success.


-
Ashish Kumar Sharma replied to Vishwadeep Khatri's topic in We ask and you answer! The best answer wins!Showcasing the data analysis and outcome graphically has been a common practice and considered to be a must skill especially Project Management teams. Not just the complex interpretation and understanding improves but it largely facilitates observation, focus on critical aspects and facilitates comparison and decision making. Waterfall is another data visualization technique that shows data trend from a start point and factors contributing positively and negatively to result in end outcome. In a bird’s eye view, it displays which factor and by how much, contributed to the performance. Due to its representation characteristic waterfall chart is often resembled to a Bridge formation and a brick chart, mostly - how did you move from one balance status to another. A typical waterfall will have a start point and this need not be zero and will have an end result. We can add positive and negative levers that contributes together to a specific outcome, that’s the layer that we want to showcase, example – we may want to show case Sales, Revenue, Individual team performance, Project Summary, Quarterly performance, Budget Cash Flow usage etc. Let’s see Waterfall closely with example, in financial year 2022, XYZ & Associates had a revenue of $2.5B USD and made net profit of $30MM. Expense line is bucketized into Cost of good sold and administration expense. Stakeholders were also keen to look at trend compared to last year. An easy and excellent storyboard can be created referring to Waterfall Chart. In the given example, it will be worthy for organization to know the reasons for high cost of goods sold and find reason to reward the Admin. team for being on the path of continuous improvement. Not just financial data but non-financial topics also gets an attractive representation. Example HR lead would want to see Headcount movement during the year and since the focus is specifically on Gender Diversity – status around the same. Waterfall chart are simple to understand, shows the changing trend and enables the representative to point out compelling attributes. In above example, it is very easy for Organization to think of extra focus and efforts on hiring diverse population. Waterfall was designed and popularized by Mckinsey. They widely used Waterfall to create a strong storyline while representing Project Status Update. The visualization was largely accepted and had a great VOC, got fame and now is part of the MS Office Excel tool. Must say – a great practice.





-
Ashish Kumar Sharma replied to Vishwadeep Khatri's topic in We ask and you answer! The best answer wins!Experiment in statistical terms will refer to a method of conducting test in order to learn or identify something. It's like performing series or unique composition of input to observe outcome, an expected outcome. Most common example is measuring a cover box that needs to be in exact dimension to carry an expensive machine part. A mechanic will continue to focus on getting most accurate measure and may need some attempts to get a perfect 10. Experiments are essential to decide nature of the relationship between independent and dependent variables. The intent is always to design a process that reduces and restricts the variable impact on output. Trial and Error – Repetitive attempts made until the perfect expected outcome is attained. In simple words, continue to practice till the desired result is obtained. Often you will notice a Cricket Batsman will continue to practice hook shots, practice till the time he is most certain to hit a six with least chances of getting caught. Ravi Shastri derived a unique way of pulling the ball and still keep the ball grounded. He surely used Trial and Error method to formulate the shot. The idea is to keep learning and adapting basis learning to get close to better than last time, eventually get to a solution. Trial and Error method is most applicable where the risk or damage due to failure is less and affordable, where the chances are often and in some cases in abundant. You may want to keep trying drive a motorbike and fall but would not put same efforts for landing an airplane. Effectively used in Lean problem solving, Repairs, tuning an engine and obtaining knowledge. One Factor AT A Time also known as one variable at a time that involves testing of one cause or factor at a time rather having multiple factors contributing to the outcome. In absence of historical trends providing expertise, it is viable to use One Factor and track the consequences. It is a simple way to notify how much has the result changes due to one factor. This test is much more controlled and helps in moving the decision logically and within a defined structure. Obviously because of its nature, one cannot predict the relationship between multiple factors and hence optimizing the solution by getting the perfect combination is missed. Also, OFAT may result in multiple runs and basis causes list. Example studying the impact on the strength of a glass bottle by changing Temperature, later Silicon dioxide composition and later funnel to hold the base. Multiple Factors at a Time also called as Fractional Experiment is a design of experiment where two or more factors are involved, each having a specified contribution (levels) and all possible combinations across different levels generates a model. These experiments allow the study of each factor and also their interactions. These designs are more efficient and informative, low on cost and fast in deriving the optimal combination and have a better coverage when it comes to factors and at their unique combinations. Example, a motor mechanic may want to observe power consumption of two machines running at different speeds, carrying different weights and on different terrains. Trial and Error method for a simple reason of being fast, agile, less complex and investments is widely preferred over other experiments. Example in preparing new Combinations of drugs and medicine and antibiotics that will largely evolve with Learn Apply Learn Method and over time. This is also called Structure Activity relationship where relationship is built with what chemical will work best with antibiotic. Success of medicines in controlling covid was largely run with test and error experiments before Vaccination got evolved. Someone did the experiment with multiple paracetamol combination and eventually concluded DOLO 650 to be the best. Similarly, most of the sports team will use the Trial and Error method over other options, especially when the opponent in new team and what may click and work in one circumstance may vary for the next time, these sequences best fit in Trial and Error Method.




-
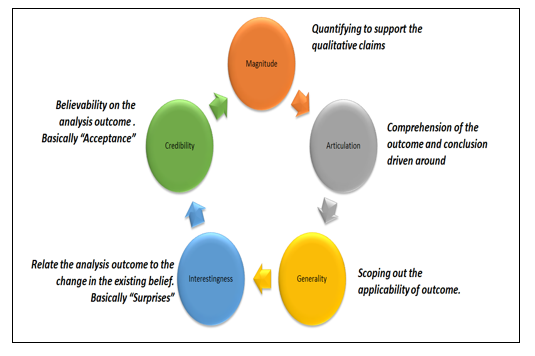
Ashish Kumar Sharma replied to Vishwadeep Khatri's topic in We ask and you answer! The best answer wins!“The central theme is that good statistics involves principled argument that conveys an interesting and credible point.” said Sir Robert Abelson, while describing the intent of writing the book “Statistics as Principled Argument”. Unfortunately, the statistical courses do not focus extensively or directionally influence user around the argumentative nature of claims they make using various statistical theories. This in turn leads to misleading, misinterpreted and misguided theories largely impacting the possible narrative. Data in its various form is characterised with several properties and can be presented differently that widely changes the persuasive forces around acceptability, impact and usage. This is guided by Robert as MAGIC. Intent of defining MAGIC was to allow the Statistical Analysis be used to make compelling or specific outcome and claims. · Magnitude – provide specific details around how BIG or SMALL the effect of analysis is. Larger the effect – more compelling it is · Articulation – Analysis outcome should be precise and restricted interpretation. · Generality – General application has faster acceptance and are more compelling. · Interestingness – Outcome should ideally result in change in the belief system in reference to the topic. More Interesting and Surprising effect – faster is the acceptance and larger compelling · Credibility – Refers to believability. There should be a method displayed and should result in a logical theory base. Any conclusion which is contradictory to already existing belief will have slow acceptance and less compelling. Since DMAIC Methodology is a data driven quality strategy used to improve processes, MAGIC Criteria has an influencing effect. 1) Define – Project Charter VOC, VOP, VOE, VOB and Need for Project has compelling results on the Problem definition and its precise articulation, SMART GOAL and Expected Outcome be clearly defined along with project team, project plan. Historical Data around Metric significantly called out HOW BIG and SINCE WHEN the Problem is. Defining the scope is characterised by Generality principal to know coverage and restrictions around applicability. Communication plan and ARMI Chart articulates responsibility framework and ensures credibility, allowing Stakeholders to approve and make investment and at the same time team to put efforts in making it successful. 2) Measure and Analyze – Process Map, Baselining, Fishbone or VMS approach, 5 WHY analysis tool and Process / Data Door approach makes the analysis and status quo meaningful, inclusive – since the entire team is included and believing in the change becomes easy. Articulation, Interestingness and Credibility are the narrative that best fits the Stage. Potential X’s along with occurrence data (Pareto Analysis) helps in providing meaningful insights - magnitude to the major contributors. 3) Improve and Control – Optimizing Best Solution, FMEA, PHUG, Decision making matrix are some examples that explicitly calls out enhanced believability and interesting way to prove To be Status. Mistake Proofing, Standardization and Automation and phasing out each counter measure to documented SOP relates to compelled Articulation, tracking the improvement and showcasing the growth to Stakeholders is an excellent way to win trust and acceptance of concerned teams - Credibility. While MAGIC Criteria has proved out to have its relevance and applicability across various streams including psychology, ecology, sociology, but due to its elementary composition, MAGIC and DMAIC goes a long way to Optime and Sustain Improvement. DMAIC follows the exact philosophy to highlight the Magnitude of the issue, point out variance and reasons - Articulation, method to identify solution and categorically improve and sustain performance. “WHAT, BY WHEN, BY WHOM, HOW MUCH –is all inclusive and very well resonates with MAGIC”
-
Ashish Kumar Sharma replied to Vishwadeep Khatri's topic in We ask and you answer! The best answer wins!Background In the ever-changing evolving dynamic world, need for skilled base man power is growing and is influencing innovation around reducing rather eliminating all historic time and effort activities, been carried out by human. Just for remembrance from late 90’s, the biggest challenge of BPO sector was to avoid human negligence in copy pasting details from PDF to Excel form and data that use to run in million lines. Often, we will hear now Generation Z expressing their dissatisfaction around repetitive and monotones job profiles. Generation Alpha getting ready to search for job profiles would get surprised to see how accounts were prepared in 90’s. The art of developing human like machines who can do exactly the same activity faster, accurately, all the time and with determined ownership towards end result. Robotic Process Automation is a software technology, easy to build, deploy and manage work eliminating defined repetitive human actions. Using a software do human task allows later to concentrate on complex decision making or processing stuff which as on date is yet not covered by a automation software and at the same time is faster, cheaper, maintain standard flow and is extremely manageable. Example, a software can screen 100+ profiles to categorize most relevant to Finance Profile and recruitment team will save 10 days of TAT and appropriate screening man hours. Robot can reach out to all eligible relevant profiles and schedule a meeting, providing all the essentials in attachment or voice message. Now the precious time of recruitment team is to interact and decide basis one on one interaction and only because the human aspect on emotions recommends this discussion should ideally not be automated. The choice of deploying, to what extent and where allows organization to be more flexible, relevant, profitable and be available. In fact, it’s best suitable for automating workflows that involve old legacy systems that lack APIs, database access and virtual desktop infrastructures (VDIs). Intelligent Process Automation also serves the same purpose as RPA but its advanced model and technology that combines artificial intelligence, cognitive automation and machine learning. IPA will take RPA capability to the next level on deployment, is cheaper and covers a larger landscape. IPA is a cheaper, smarter and efficient technique that serves a lot more around productivity and comfort on usage. Instead of just mimicking like human being, IBA will allow thinking, learning and adapting to the situation and data work flow. Signing into desktop, recognizing natural language and interpretating, filling up a form with basic information are all example of IPA. Now do we see any similarities in RPA and IPA, of course. IPA in a way is advanced, upgraded and next level to RPA. It handles more complex processes, critical data formation and most importantly takes decisions. RPA is a simple and continuous repeat of what has been mentioned while IPA can take smarter decision in order to reach to an expected outcome. RPA can help and very well be the initial road and allow organization to get matured with automation initiatives involving IPA. Similarity statement between RPA and IPA also voice out logical difference. Some of them are narrated below for a quick reference. S. No RPA IPA 1. RPA uses structured input and logics but is not impactful with variables. IPA uses unstructured input and develop its own logic, adapts with Variables 2. Is a software-based Robot, rule based that needs a rule feed on what do with Exceptions Combination of RPA with AI Technology. Smart enough to interpretate and handle exceptions. 3. Automate repeatable human action and behaviour. “Mimicking like Humans” Handle more complex processes and have the ability to learn and decide. “Act like Humans” 4. Evolved from Screen Scrapping, Workflow and Artificial Intelligence Build in with RPA along with Natural Learning Processing, Machine Learning, Data Extraction and AI 5. Best suitable for High Volume Processing. Saving Time and efforts Best suitable where decision making is needed to move between steps. It will be everything which is RPA but smarter and flexible 6. RPA has its restrictions; analyst still need to spend time in retraining Bot IPA automates more and automates more efficiently, adapts, learns on its own. 7. Productivity is limited to the scope of work is with activity rather processes Cost of Adaption is cheaper and generates more productivity 8. Easy to use and don’t require deep technology skills and ranges from basic to mature Significantly complex and hence skill requirement ranges from matured to advanced. 9. Generally Human Dependency is reduced and not absolutely avoided. IPA can elevate the process to run without manual intervention needed Where is IPA heading towards…. It has been said about “Chess” it is a mind game and works to sharpen the human mind. World Champions across world are considered to brilliant mind. But with technological advancement, Automated game is very much capable of defeating human mind for its adaptability to think, react and act just like human being except for the fact it will not forget to make a loop of what best it learnt in giving situation. An example from mail management, with a simple RPA we can deploy a Bot to send one pre-formatted mail across individually to multiple mail id. With IPA, Bot has the capability to read the body of the mail and interpretate the severity, category and assign the mail to a specific individual. Another example from a Call Centre, RPA can assign calls to the specified calling agents and note the Call Handling Time. Using IPA, the BOT can measure and comment on the Agents Call Quality. It can interpretate the sentiments and reaction of the customer and guide logical solutions.


-
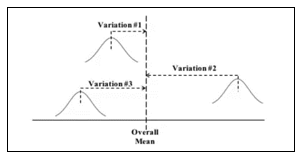
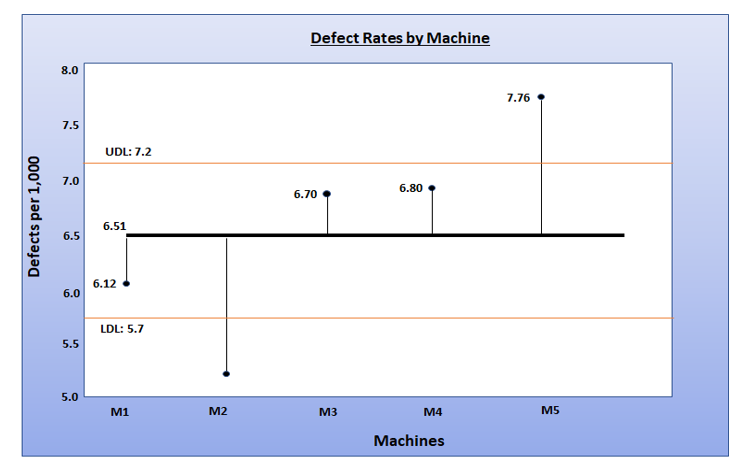
Ashish Kumar Sharma replied to Vishwadeep Khatri's topic in We ask and you answer! The best answer wins!ANOVA helps in analysing the hypothesis if mean of two or more populations are equal. It is a statistical method that examines the amount of variation within each sample and hence difference among the mean of populations. Example – which one of the exercising methods is better – Weight lifting, Gymnasium or Yoga. Or a manufacturer may be interested to know whose outcome is better - the old machine or two new machines purchased from different brands. ANOM is a common statistical quality assurance tool that compares multiple sub groups with an Overall Mean. ANOM has the capability to highlight with sub group is different from the Overall Mean. Example, ANOM can tell us which production line in the factory is not producing product in line with the mean. Both ANOVA and ANOM are attempting to ultimately achieve the same result. There are some similarities between ANOVA and ANOM as both are meant to serve variance analysis. They both require the data to be distributed normally (approximately), can analyse variation of several means and more than 2. Both of them can do 1X variable or 2X Variable analysis. Let’s look at the difference between two largely around the way they measure variations. S. No ANOVA ANOM 1. Variation is measured among the population Calculates Overall Mean and measures the variation of each mean from that 2. Can only identify if there is significant difference Can identify which group mean is significantly different 3. Identity of each sample within the group is lost Identify is retained and available for comparison 4. Compares a group mean in study with another group mean Compares group mean with the overall Group Mean 5. ANOVA uses three different estimates of variation and calculates the Ratio Specifies the number of groups being assessed and then Overall alpha level for analysis Clearly basis above, if the expected outcome and decision requires not just the understanding of variance but to know which sample population has defect compared to Overall Mean and how much … ANOM is used. Let’s see this with an example. Suppose, of 5 machines is production line, Supervisor wants to know which one of them is performing fine and which one has more defects and a comparison with all. The below defect data collection and respective Means showcase the difference. Machine 1 Machine 2 Machine 3 Machine 4 Machine 5 Sample 1 6.0 5.2 6.8 7.1 7.4 Sample 2 6.5 4.3 7.0 6.7 7.9 Sample 3 6.1 5.1 6.7 6.5 8.2 Sample 4 6.2 5.3 6.4 6.9 7.7 Sample 5 5.8 5.9 6.6 6.8 7.6 MEAN 6.1 5.2 6.7 6.8 7.8 Clearly Machine 5 has the most defect rate and others have marginal difference but are these defect rates statistically different. This will get showed when we use ANOM. Graphical ANON displays a Confidence Level. · The dots show the Mean for each Machine · Means outside the UDL and LDL indicate statistically significant difference from the Overall Mean (6.51) · M2 and M5 Machine are the most significant contributor to defects

-
Ashish Kumar Sharma replied to Vishwadeep Khatri's topic in We ask and you answer! The best answer wins!Both Bayesian and Frequentist approach of hypothesis testing are important and relevant method to facilitate determination of an event. Dependent on the approach for decision making, a choice can be made between the two well known ways of hypothesis Bayesian Hypothesis testing is a method of assigning probability to unknown parameter, compared with available historical trend and gathered knowledge and later extended with most recent information about the unknown parameter in consideration. It is like simulating with the in-scope data multiple times which will ideally provide more details on the alternatives and firm up the probability factor on occurrence, with time. In simple terms, it is somewhat how we normally think and affirm an opinion. Start with a prior belief and keep improving this in light with new evidence. We regularly update our knowledge in light of the known facts – focus on what is known via knowledge and existing data, identify an issue with unknown fact that is in scope to decision making and carry out multiple / repeated actions that allows us to evolve and firm up a decision. Scientifically, It has 3 stages, specifying a prior probability distribution on unknown parameter, observed data summarized using Likelihood function hypothesis and posterior distribution also known as updated knowledge. Frequentist Approach is more of making predictions basis Data from the current experiment and is driven by what is known at a given point of time. The Hypothesis test (Null and alternative) based on applying statistics conclusion to identified data and when compared to P Value, will either recommend acceptance or denial of the specific outcome. In simple terms, Frequentist approach confirms the probability of having the same outcome if the condition is repeated again and again. This model only uses data from the current experiment when evaluating outcomes. Statistically it has 4 stages, Defining the assumption (Model), Null and Alternative Hypothesis, Test data basis available tools and use outcome to from mathematical conclusion. Despite of having same intent on outcome, the basics around theory and independent characteristics differentiates them from each other, some of them are noted below: S. No Bayesian Hypothesis S. No Frequentist Approach 1. Derives Probability by inferencing past knowledge combined and upgraded with outcome from current experiment. 1. Makes predictions purely basis data from current experiment, it is long run frequency of repeated experiments. 2. Parameters are random variables and data is fixed 2. Parameters are fixed and data is replicated 3. Probability is assigned to both hypothesis and past data 3. No probability is assigned to the hypothesis 4. Performs well with small data set, one can start with as small as one data set 4. Gives confidence in large data sets, since the later is randomized 5. Driven by ability to form prior model and relate to the difference in the answers 5. Easy to calculate and formulate hypothesis – statistical analysis based 6. Inferences here will lead to better communication of uncertainty 6. Based on fixed data and hence lacks the flexibility to adapt uncertainty 7. Easy to relate to the outcome, since the advantage is of having a prior parameter and knowledge 7. Mostly difficult to interpretate P Value and hence somehow keeps the confusion on absolute interpretation 8. Comparison is with P value with prior probability and prior is subjective 8. Hypothesis testing uses comparison with P Value that has never been observed Let’s also look at unique preposition around Bayesian way of thinking compared to a Frequentist way with an example, If someone asks us what is the probability of getting King of hearts in the given image, when picked from blind side of the cards? Most often than not, the response will be ½ or 50%. Absolutely right!! But if the cards are jumbled again and if I ask you to choose one of the cards and raise the same question.. what is the possibility of getting king of heart? Will the answer be different now? Some of us will say, now since I have picked one card, either the King of heart has been picked 100% or not picked which is 0%. Obviously, now there isn’t a choice anymore between two options to be considered as Heart or Club? That’s how Frequentist will think. Some of you will record the previous hold knowledge on probability and say it is still 50% and unless proved otherwise with series of trials. We win some and we lose some. You just choose Bayesian way of thinking. Similar example from real life may be how doctor examines the health condition of a patient. In a typical Bayesian way of thinking, doctor will take weightage around prior diagnostics, do fresh investigation and later recommend meditation basis fresh assumptions and result. But a Frequentist way would lead basis current diagnostic results and prescribe related mediation. These examples will direct us to think of below characteristics … · Bayesian way will tell you what you want to know, which one is better · Frequentist will keep It difficult for you to interpretate uncertainty since comparison is with P Value · Frequentist do not explicitly call out assumptions · Bayesian method is immune to data peeks, whether you update prior parameter with every experiment or at any given point of experiment – makes no difference

-
Ashish Kumar Sharma replied to Vishwadeep Khatri's topic in We ask and you answer! The best answer wins!Analytic Hierarchy Process (AHP) is an organized decision-making method that enables analysis around a problem, needed for making a choice between available alternatives by determining the criteria basis which selection or prioritization will be done. It is a process of quantifying criteria and alternatives and relating each element to the desired outcome. Pugh Matrix is most popular decision making six sigma tool that uses scores awarded to criteria and scoring them for each alternative. It is a qualitative technique which allows stakeholders to make a choice between alternatives basis scores. While both are used for the same purpose but preference and usage are largely driven by the stakeholder approach, problem in hand and proof of concept needed. Let’s look at some of the differences. AHP PUGH Matrix 1. Pair wised Matching – compare two criteria at a time and amongst alternatives 1. Each alternative is independently awarded a score and compared with DATUM and against the weightage decided for each criteria 2. Quantitative method used for evaluation 2. Qualitative method by awarding scores 3. Complex Statistical Method 3. Simple Method based of Ranking 4. Enables a direct comparison between alternatives and via defined criteria 4. Each Alternative is not compared with each other 5. Consistency Index (<10%) aids validation of the comparison outcome. Improving a decision is possible 5. No such validation and standard are possible 6. Based on Continuous Data – Ratio 6. Based on Discrete Data – Ordinal Data Type 7. Is not LEAN SIX SIGMA QUALITY Tool 7. Is integral part of the LEAN SIX SIGMA QUALITY Playbook 8. Very difficult and time-consuming process especially with more criteria 8. Preferred tool to handle several criteria’s 9. Based on stimulus – response, a mathematical numeric relationship is established 9. Based on Logical thinking, experience and willingness of stakeholders. 10. Individual and Group decisions can be combined. Everyone has a strong reason to believe in the outcome 10. Stays Subjective to a great extent, enables understanding of each alternative compared to existing one The complexity involved and the ability to run AHP, differentiates the choice to be made in comparison with Pugh. AHP is more time consuming and requires complex calculations to reach towards conclusion, ability to handle data and using the method is the key. Hence, AHP is less preferred compared to Pugh and mostly due to simplicity factor. Example scoring movies to judge the most preferred for annual reward compared to a preference of IT Software involving investments. In first case Experience and Knowledge of stakeholders in reference to the problem in hand, governs the success and accuracy of Pugh Matrix outcome. Hence Pugh Matrix can handle sensitive analysis better and where quantitative data is available in abundant. Where as the client would want to have more statistical proof concept for deciding which Software to install and WHY, AHP will be the preference.
-
Ashish Kumar Sharma replied to Vishwadeep Khatri's topic in We ask and you answer! The best answer wins!Artifacts in Project Management Background and importance Project Management involves extensive planning, execution and effective communication within teams and with stakeholders. Documentation holds the soul of any effective project management skill. Artifacts are the documents that provide relevant information to project that may be Vision and Need for project, from Business case, VOC, VOB, VOP, VOE to Scope, Specification and Stages of project along with timelines, expected impact, templates, analysis reports, etc. All these elements are of high importance for the team and all related parties to the project keep referring back to artifacts during various stages of project. Management can do a comparison between planned and actual status, take corrective actions, be proactive in taking decisions and enhance effective and efficient closer of the project. Type of Artifacts There are 9 different types of Artifacts known and extensively used in project management. 1) Strategy Artifact Client expectation, Need of the project, Scope and Metrics, Charter etc are documents created at the beginning of the project. These documents basically define the objective of running a project. Stakeholder’s agreement, commitment and sign off for investment is generally initiated with these set of documents. This artifact is vital as it allows the team to refer back to Strategy decided in the beginning and allows them to course correct the execution plan to deliver the desired result. DMAIC – prepared mostly in Define stage but is referred back at each stage. 2) Communication Plan Most of the projects will have their focus around ARMI and Communication. Starting with the core team responsible to participate / deliver to sponsors, champion and aligned Quality team, the frequency, content and medium of communication varies. A well lay out plan and shared with the interested team improves credibility, expectation, transparency and ensures accountability. DMAIC - prepared mostly in Define stage but is referred back at each stage. 3) Logs and Register Projects has dependency of various types of data gathering and its analysis. This is important for team to focus on the identification of relevant potential aspects and create an action plan to improve the performance. A project manager should always keep a record of all data analysis and records used and mentioned during decision making and execution. Risk, Assumptions, Historical output data, Stakeholder feedback etc all should be documented in form of a standard register. DMAIC – Mostly prepared during measure and analysis phase but is quite relevant in Improve and control stages 4) General Plans Ensuring in time progress and expected outcome is Project Manager’s core responsibility. Usually, manager will prepare multiple plans aligned with the core vision and committed objective. Example logistics, accuracy, iteration and exception handling, UAT results etc all should have an exclusive plan. This allows focus and continuity to the project progress. DMAIC – most used in Improve phase but often is important in all phases including Measure to Control. 5) Reports Periodic report submission is an integral part of stakeholder and team management. A summary view on how project is progressing against target, influences the authority to take decisions and ensure success to the project. Investments, Quality, Risk etc are some of the examples that gets officially submitted as record for stakeholders. DMAIC: Created in all stages of the project mostly from Measure stage 6) Organization Hierarchy Charts Depending on the scope, landscape and characteristics, a relationship exists between various process, departments, products, teams and stakeholders. A well-defined representation via a chart shows the value flow and inter dependency between various parties. This also helps to establish an Escalation channel, ownership of process breakdown and associated risk. DMAIC – Most often prepared in Define stage but it keeps getting updated and at different layers during every stage of the project. 7) Visual Dashboarding and information Day wise performance, month on month comparison, inter operator level performance etc all are considered to be live documents. The visual representation of performance and status is an easy way to communicate all teams on how progress is compared to defined targets. An excellent tool for Operations as well as stakeholders, enables GENBA and documented response and explanations serves in Root cause analysis and appraisals. DMAIC – Improve and Control stage has most relevance but can also be leveraged for various stages of Analyse phase. 8) Baseline Baseline is the defined set and approved version of how the project should perform. Budget allocation and usage, man power deployment, timelines to milestone and performance are some examples where Baseline is used extensively. Baselines can get updated as the project progresses during each stage of the project starting with Define stage. DMAIC – used in all stages of the project but Improve and Control stages has most focus and attraction as it facilitates a performance comparison for team and stakeholders. 9) Agreement and contracts Depending on project, the various binding and agreed clauses in an agreement are documented. The only one assurance cover or guard that both the service provider and investor to a project may have to resolve the dispute in the eyes of law. Price, delivery time, material quality and reimbursement contracts are various example of agreement that stakeholders get into either before or during the course of project. DMAIC – Often the generic agreements are signed off during Define / Pre-define stage of projects but dependent on the outcome and progress, agreements can be made between the interested parties. Measure and Analyse phases would witness most the real time document. A quick summary of Artifacts adaption in DMAIC Define Measure Analyse Improve Control Strategy P R M R R Communication P M M M M Log and Register P P P P P General Plans P P P M R Reports R P P P P Hierarchy Charts P M M M M Dashboards R P R P M Baseline P R M R R Agreements P R M P P P – Prepared, Maintained and Referred, M – Maintained and Referred, R – Referred mostly The chart is a directionally generic recommendation and with the assumption that all the artifacts can be prepared and maintained during any stage of DMAIC and need be.

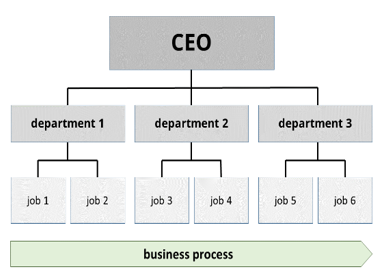
-
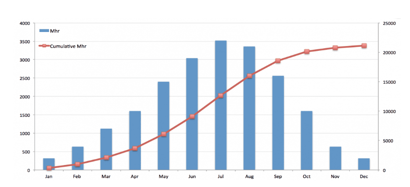
Ashish Kumar Sharma replied to Vishwadeep Khatri's topic in We ask and you answer! The best answer wins!S Curve – Project Management Background and Need Project Management is a strategic initiative of any organization and has focus and attention of entire leadership and stakeholder. It is not just about the expected impact from Transformation but also about the risk associated with Return of investment while prioritizing ideas that influences stakeholders to invest in the project. Hence effective governance and communication of Project Milestones, Investment, Timelines - planned vs actual analysis takes the center stage. Stakeholders are focused on investment made, planned and related outcome whereas Project Management Organization should have their focus on execution, analysis and proactive communication. When it comes to Project Analysis and Communication, while there are many visual tools and techniques to visually monitor and communicate Project Progress, S Curve stands out and serves to be a perfect tool to showcase comparison of important data sets of a project with Timelines. In simple words, S Curve allows the Project team to monitor project progress at a high level. It is a graphical representation of how the project is trending compared to plan for identified lever and in respect to Timelines. WHY an “S” Curve? Typically, all Projects have a slow start where core teams are formed and stakeholders get on boarded, more of planning stage and less of doing. Investment are needed more as execution begins (point of inflection) and slows down as the project reaches its end stage. Here investment might be Man hours, quantity inventory, Machine deployed etc. show cased cumulatively on Y axis and Timelines is always on X axis. The graphical image is very similar to the Alphabet S and hence it is called as S Curve. Types of S Curve? S Curve is may be used to show case: 1) Target Stage (Milestones) 2) Cost invested 3) Growth, Revenue 4) Man Hours invested 5) Baseline vs Actual Comparison All of the above levers are displayed on Y Axis and Timelines is always shown as X Axis. Uses of S Curve 1) Performance Evaluation and Stakeholder Communication: A lot of performance discussion are around the progress made against the commitment. Often there is an element of best in class and past performances that works like a Benchmark. S Curve has the capability to display Actual, Benchmark, Target and Future forecast in the same graph and displayed against the timelines. It sets the tone around how good or how far the project performance is. 2) Forecasting: The Management team while evaluating progress, would also want to have a close look on the next stage investments and obviously be comfortable with the planning around it. S Curve can showcase the trend around the forecast. Example, S curve can showcase how many man hours are deployed as on date and how much is the expectation for coming month / quarter. Human Resource team would relate to and own the plan well to ensure in time availability of labor. 3) Project Management Organization The PMO team can effectively use S Curve to strategize next steps along with various possibilities. A combination of levers in S Curve graph is a fantastic medium to get a direct representation on the gap in performance, management can identify various possibilities to influence the outcome. It is also called as Banana Graph. 4) Baselining and Growth S Curve in Project Management supports estimating time, cost, material, data to be mapped with expected outcome and often against the best in class. It promotes discussion around what is needed to influence the change rather than reactions and explanations around the delays. 5) Determining Slippage There are often differences observed between the schedule start, baseline and plans for end of the task. This difference is monitored effectively via S Curve and hence reduces the chance of surprise outcomes. Limitation and Conclusion S Curve aids more like a descriptive tool unless it is complemented with a team that can comprehend decisions and tap the variances. S Curve is dependent on the Project team to go deeper and understand the root causes to deviation between actual and plan. But that’s the basic characteristic of most graphical tools. The S Curve is not a great serve to investments in new areas example new software technology replacing old configuration. Project Management requires a lot of matured strategic base in the organization, from winning stakeholders trust to deliver and meet the expectations. Hence it is inevitable for team to track multiple parameters and scale them up to past performance as well as planned future. S Curve is very helpful in displaying the progress and invites comparison. It is a great tool to track cost in comparison with timelines and most of the projects fail or get discarded due to failure in comparing the actual with plan and in time re addressing the execution plan. It is a great way to convince stakeholders and get sign off on future budgets.