Amlan Dutt
Lean Six Sigma Green Belt
-
Joined
-
Last visited
-
Let’s see an example for DPMO calculation for cinder blocks evaluated on length, breadth and height. Item/Criteria Length Breadth Height Defective # of defects cinder block #1 correct incorrect correct yes 1 cinder block #2 correct incorrect incorrect yes 2 cinder block #3 incorrect correct correct yes 1 cinder block #4 correct correct correct no 0 cinder block #5 correct correct correct no 0 Opportunities/Unit 3 Total Units 5 Total Opportunities 15 Total Defects 4 DPO 0.266667 DPMO 266,667 Area to right 0.27 Area to left 0.73 Sigma level (with 1.5 sigma shift) 2.12 The flaws in using DPMO as metric are obvious, and listed below 1. DPMO/Sigma Level are metrics which can theoretically be used to compare unlike products and processes 2. Complexity of defects can’t be represented with DPMO; not all defects are equal sometimes 3. Defect density is not captured by DPMO; i.e. a needle in haystack OR box of needles in haystack 4. Back calculating DPMO from sigma level, if defects doesn’t follow a normal distribution then sigma level will be overestimated 5. DPMO and PPM are not the same, except if # of opportunities for a defect/unit = 1. These are used interchangeable very often 6. To make a jump from 2 to 3 sigma, DPMO has to be reduced by 241,731 while from 5 to 6 sigma is mere 230 (all with 1.5 sigma shifts). This shows that DPMO is sensitive to tails of distribution which is not always a nice thing. How? a Burr distribution with c=4.873717 and k=6.157568 perfectly resembles a standard normal distribution with mean = 0, sigma = 1, skewness = 0 and kurtosis = 3 but are very difference from DPMO standpoint. i.e. our realization of the ‘true’ distribution of a process will never coincide perfectly with the truth 7. Chasing zero defects in accordance with DPMO, a good process can be made better but not perfect. 8. Over relying on DPMO may give inappropriate approximations of Cpk
-
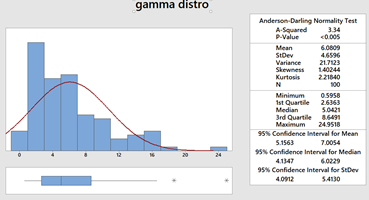
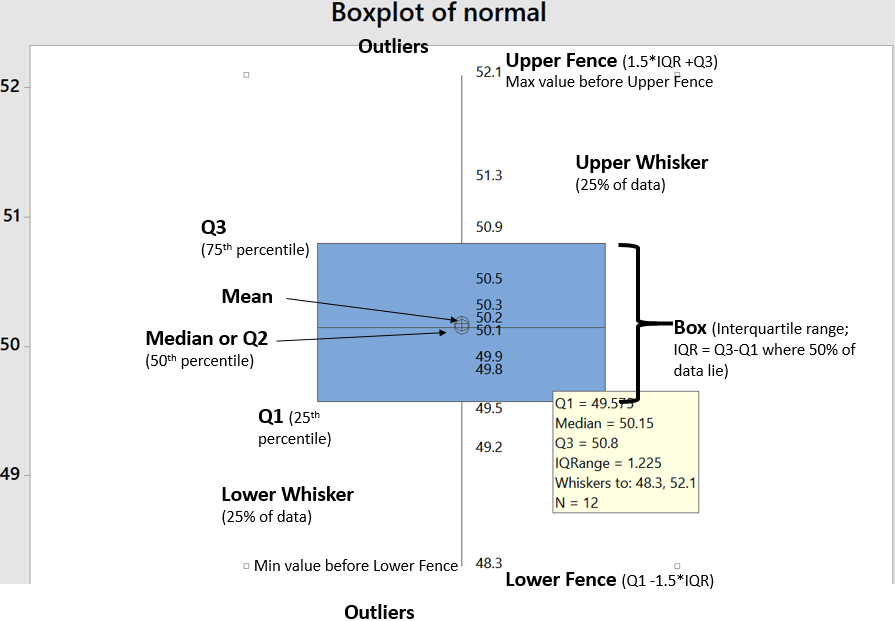
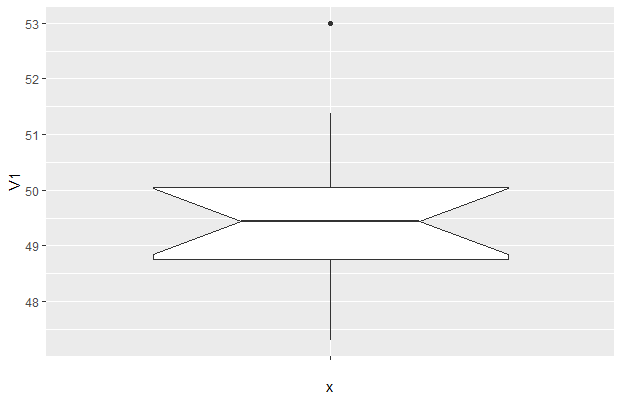
Check this one out! A picture worth thousand words. Box plot comic So the benefits are obvious. Box plots are easy to interpret. It is five point summary (Q1, Q2 ,Q3,Upper and Lower Fences) It handles huge uni-variate observations pretty quick; because median doesn't require an analytic solution unlike mean It handles non normal distribution pretty well Let's see at anatomy of box plots. So It helps visualizing 25th, 50th, 75th percentiles along with mean and outliers. Box part of it contains 50% of data while remaining 50% lies with both whiskers collectively (...along with outliers). One question arise that why did John Tukey (inventor of box plot) selected 1.5 times IQR? Well because the tendency really is to consider most distributions to be Gaussian by reflex, and for a Gaussian distribution, it works well. What I mean is, for a nice Gaussian distribution, (with s as Std. Dev and X as Mean) Q1 = -s0.67 + X, and Q3 = s0.67 + X, (from the property of standard scores for a Gaussian distribution) IQR would be Q3-Q1, So IQR = 1.34s (from above) Tukey’s lower bound = Q1-1.5IQR = 1.34s , which is X-2.7s If you chose Q1-1IQR, it would be X-2s (too many outliers), and if you chose Q1-2IQR, it would be 4s (too few outliers) 1.5IQR allows just under 3s, (and is easier to handle than 1.567IQR). In other words, if +-3s gives ~.3% observations as outliers, box plots with +-2.7s will give .7% observations as outliers. It handles mildly non-normal distribution well showing skewness. Below are examples of left skewed, no skew and right skewed data from top to bottom. Notice the differences in respective box plots. Another interesting fact is there are nothing like Q0 and Q4. Why? Try finding 0th or 100th percentile of any uni-variate data. These are undefined! reason being percentiles are calculated from CDF by popular softwares while assuming normal distribution by default. We already know that CDF of normal distribution is unbounded. That's why for highly skewed distributions box plots are not good choice. Some softwares call Q0 and Q4 as minimum and maximum but then they no more remain fences of whiskers because there can be observations as outliers. Notably box plots are poor with representing "holes", below is a box plot with mixture of two normal distributions (mean of 50 and 90; same SD of 1). Although there are no observations between 53 and 88 yet the box misrepresents it (...or it increases chances on misinterpretation). Another variant of box plot is with notches which give 95% CI for median.

-
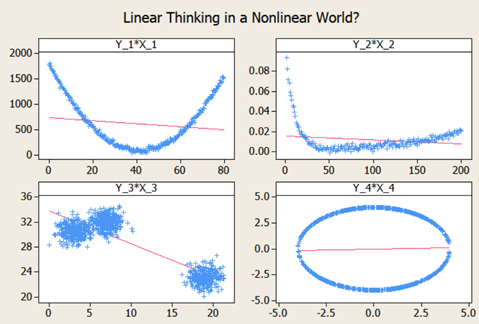
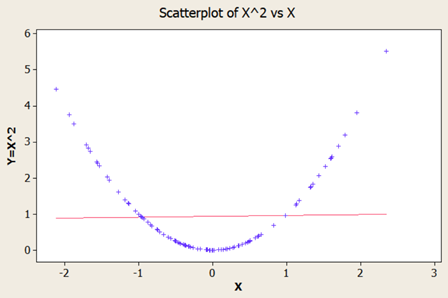
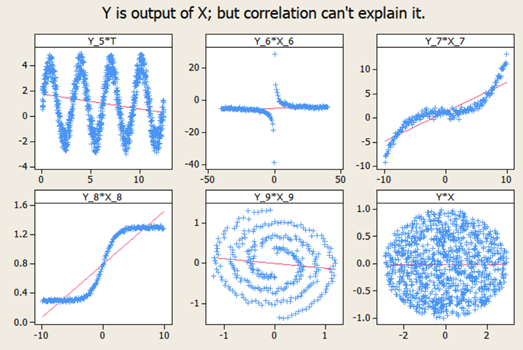
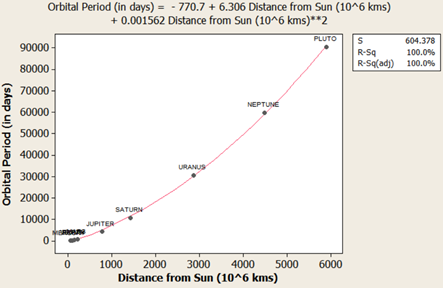
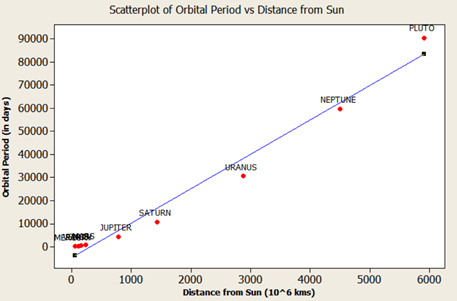
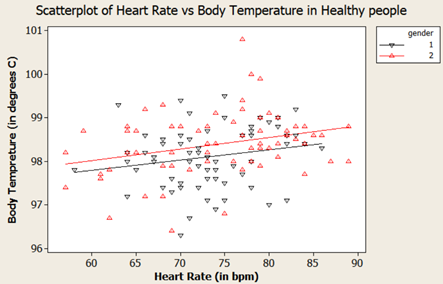
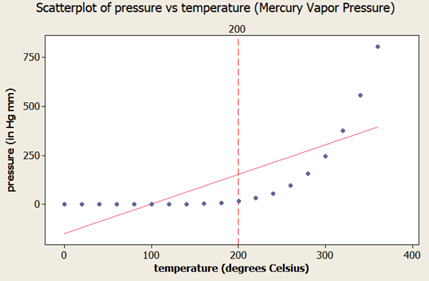
Short answer: Strictly speaking Answer is “No” Long answer: Let’s see the possibilities 1. Correlation weak/not present, causation present. i.e. asking Does causation imply correlation? 2. Correlation present, causation not present. i.e. asking Does correlation imply causation? a. Already covered in LSSGB program 3. Both Correlation and causation present a. Sweet spot! 4. Both Correlation and causation not present. i.e. asking Does no causation imply no correlation? a. Hard luck We will focus on first point. Causation implies change in X impacts Y in certain way; two things are vital to establish this relationship. Understanding of system generating the data and validated Y=f(X) equation. 'Causality' is being expected to be expressible as a function. i.e. X causes Y if and only if there exists a measurable function, f. This f can be linear or nonlinear. Correlation is a bivariate analysis that measures the strength of association between two variables and the direction of the relationship. It can come in the form of Pearson, Kendall, Spearman measures with assumption of ‘linearity’. Let’s see below 4 scatter plots, consider a hypothetical machine which takes X as input, processes it and gives output as Y. Additionally if Y=f(x) is known, then causation is proven. (Data attached) Since the relationship is established and system generating them is well understood (…otherwise these scatter plot wouldn’t have been made possible). We can check the correlation for quantifying strength of linear relationship. Guess what?! correlations are very weak with some perplexing p values. The correlation values are irrelevant here because relationship is NOT linear. If relationship between X and Y isn’t linear, correlation isn’t effective quantifying the relationship. In fact to formulate the right question the word ‘correlation’ must be replaced with ‘dependence’ or ‘mutual information’. Fortunately, correlation is not the only way of measuring dependency. Below are some peculiar patterns which correlation can't explain. Let's see a curvilinear plot, where X defines the output Y with Y=X2. Causation is implied because X determines value of Y. However, correlation is not present. If X is standard normal variable X∼N(0,1) then X2 will follow chi square distribution with df=1; X2 ∼ χ21 For unstandardized X, Z2∼ χ21 Mathematically, the expected values are written as below E[x]=0; E[x2]=1; E[x⋅x2]=E[x3]=0 (…E[x], E[x2], E[x3] are called moments) Cov[x,x2]=E[x⋅x2]−E[x]E[x2]=0 Corr(x, x2)=Cov(x, x2)/σ x⋅σ x2 =0; in other words correlation is zero The above derivation will be true for all symmetric distributions. How about some real-life examples? Consider our solar system, orbital period of a planet is an outcome of its distance from the sun. Higher the average distance, longer the planet will take to revolve around the sun. This causation is implied. Question is does correlation explains it well? It’s not a linear relationship at least, that’s what Kepler discovered after a decade of research and published as laws of planetary motion in early 1600 AD. (...now done with Minitab in seconds!) Thus, a quadratic term fits better giving R2 of 1 while linear regression throws R2 of 0.97. Although the difference may not be huge but laws are deterministic in nature. Yet another one, vapor pressure of mercury (Mercury is a metal which exists in liquid state at room temperature). When liquid mercury is stored in vacuum container, it begins to evaporate producing vapor. This vapor in turn exerts pressure on liquid which is known as vapor pressure. Relationship of vapor pressure with temperature is so complex that there is no law in theory that specifies it. Yet causation is implied, and we use correlation on it. As evident there is causality, correlation would be underestimating the strength of relationship at higher domain value (>200 degrees C) of X but overestimating at lower domain value of X. After physics and chemistry, an example from biology. The relationship between heart rate and body temperature. When you do intense physical activity, the heart rate increases to pump more blood to muscles and as a result body temperature rises with increased metabolism. This is well established causality and everyday observation. However, correlation value is mere .25 here (but significant p). This isn’t what we expect, do we? Question is why? Because dependencies vanish in self-regulatory system. i.e. as counter action body also sweats to reduce the temperature. How to overcome? piece wise correlation and distance based correlation come for quick rescue. Causation_Correlation.MPJ
-
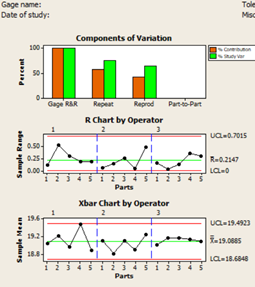
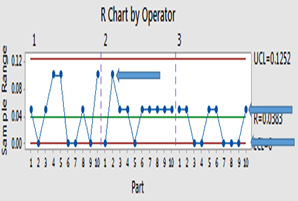
Well! I would try to keep it short Why GR&R? You are basically measuring Part-to-Part variation, Equipment Variation (Repeatability), Appraiser Variation (Reproducibility). We expect most of the variation to be caused by variation between the parts than caused by the appraisers and equipment. If the one or more appraiser can’t get the same measurement on same part, then the measurement system is source of error. How it is done? (An example of 5 parts, 3 appraisers, 2 trails each on all parts, See file attached) 1. Pick a part (identified by unique part number, say a hexagonal bolt) with known specification tolerance level. Ex. 20 cm with ±1 cm 2. Choose 5 specimens of same part from one batch or lot, that covers the specification tolerance. i.e. if the specification tolerance is 20 ±1 cm; select specimen that start at 19.1 and go to 20.9 (19.1, 19.6, 20, 20.5, 20.9) 3. The part should represent the actual or expected range of process variation. if you're measuring to 0.1 cm, the range of specimens should be 10 times the resolution. Number each specimen for the study but don't put them in any kind of order 4. Three appraisers (people who measure the specimens) 5. One measurement tool or gage; Resolution of 0.1cm 6. Two measurement trials, on each specimen, by each appraiser 7. Randomly have each appraiser measure each specimen at least twice (In text books, the word specimen doesn’t appear but I used it for clarity) The second step above is noteworthy. It’s not a random sampling from assembly line but cherry-picked specimens of part which covers expected range Gage R&R study is evaluating measurement system and NOT part, it doesn’t care not care how good parts are but how well they are measured over the specified range You also need bad parts to perform a Gage R&R study, a bad part can be outside tolerance limits Now the answer lies in the way the X-bar and R Charts are constructed. The values on the R-Chart are calculated by taking the differences between the highest and lowest measurements obtained by each appraiser for each part through random trials. It represents only measurement variation in the system. The control limits for the X-bar Chart are based on the R-Bar of R-Chart. Thus, the area between the control limits on the X-bar Chart represents the amount of measurement system variation. When plotted on the X-bar Chart, it contains both part-to-part variation and measurement variation. Hence, >50% of points on X-Bar chart should fall outside the control limits representing acceptable measurement system variation while highlighting prominent part-to-part variation. (provided range of specimens is very high as compared to resolution of gage) However, it’s not so with R-Chart but is used to compare operator bias. If there are values above UCL of R-Chart then it should be investigated for invalid measurement or data entry error before proceeding. Nevertheless, when values are within CL it shows acceptable discrimination by measurement system. If the R-Chart cannot discriminate between different sample parts then measurement system is not sensitive enough to be used any further. Below is an example of poor R-Chart in GR&R, it can discriminate only 3 distinct categories shown with blue arrows. Below are output of doing GR&R right way (right) vs. wrong way (left) using fictitious data generated from normal distribution. The right way is discussed above in “How it is done?” while wrong way is elaborated below in last section. (The so called right way is not so good as one of the point is outside UCL in R-Chart but it’s computer generated data!) The X-bar chart (right image above) looks like a process out of control with many point outside the control limits but it is NOT a process chart but a measurement system analysis chart. The tighter the limits and the more point outside those limits, the better the measurement system. Thereby contributing very little to the total variation in GR&R. It's apparent from R-Chart that the number of distinct categories = 6 (minimum 5 is desirable) As explained control limits are calculated based on measurement error. Consequently, the control limits define a blackout zone inside which the gage cannot see anything. The gage can only see a measurement when the it exceeds this blackout zone. Ideally, you would want as many points as possible to exceed this zone. So, when will >50% of the data points NOT fall outside of the control limits, just the opposite as expected from good GR&R study Measurement system has errors (…is blind as stated above); measurement system shows more variation than manufacturing process Using only one specimen measurement for all 5 specimens of same part. If you only use one specimen, there can’t be any part variation, so people and equipment will be the only source of variation. This is shown above as the wrong way! Process width has reduced beyond the gage can detect at current resolution, gage can measure at resolution of 0.1cm while part to part variation is measured down to .001cm Range of specimens is very low as compared to resolution of gage. Using parts between 19.6 cm and 20 cm in current example Can't edit it anymore! fictitious data.MPJ


-
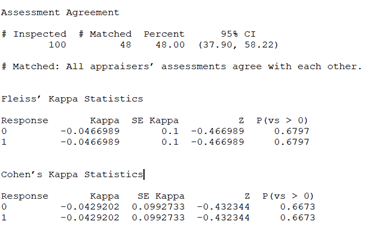
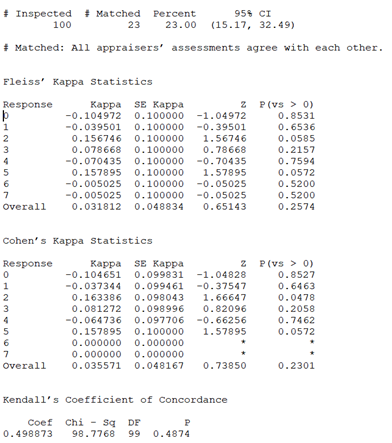
Consider two unbiased coins tossed 100 times simultaneouly and results put through Fleiss’ Kappa and Cohen’s Kappa (Kappa values range from –1 to +1) spitting out the results below; Since these are statistically independent events, any match will be purely due to chance alone. p-values >0.6 tells (at 5% Type 1 Error Risk) fail to reject the null hypothesis that the agreement is due to chance alone. Notice Agreement is nearing 50%; thanks to Bernoulli random number option in Minitab. So far so good. Let’s test it on liar’s dice! Consider two dice (…from a Martian liar) which can show values from 0 to 7 tossed 100 times simultaneously. It’s basically two random Poisson variable of 100 observations with mean=2 (mean=variance is a property but that’s another story) As narrated before any match will be purely due to chance alone (…being random). Presto! What went wrong? The curious readers will notice for Responses "2" and "5" the p-values are below 0.06 (i.e. only 6% risk by chance alone). Which means we can reject the null hypothesis that the agreement is due to chance alone. i.e. numbers on 2 dice match NOT by chance for at least "2" and "5". (The negative kappa values tell very poor inter-rater reliability) While the fact is data has been randomly generated. Hence, any matched would be purely by chance alone. These opposing statements indicate a null hypothesis accepted even though it’s wrong. i.e. alternate hypothesis is right. In other words, we have committed a Type 2 Error. Why? Because of using Kappa instead of Kendall, Kendall give a Coefficient (values range from 0 to +1) but highly insignificant [0.4874]. i.e. Kendall tells it’s due to chance alone Why? Because kappa treats all misclassifications equally, but Kendall's coefficients do not treat all misclassifications equally. i.e. Kendall's coefficient considers the consequences of misclassifying “4” as “0” more serious than as “3” (…being ordinal) while cute Kappa is not so serious. Why? The devil is in the details; i.e. concordance and discordance. These 2 little mischiefs don’t appear in Kappa unlike Kendall’s formula. Why? The first mention of a kappa-like statistic is attributed to Galton 1890s while Kendall’s work predominantly appear during 1930s. The last why was googled!
-
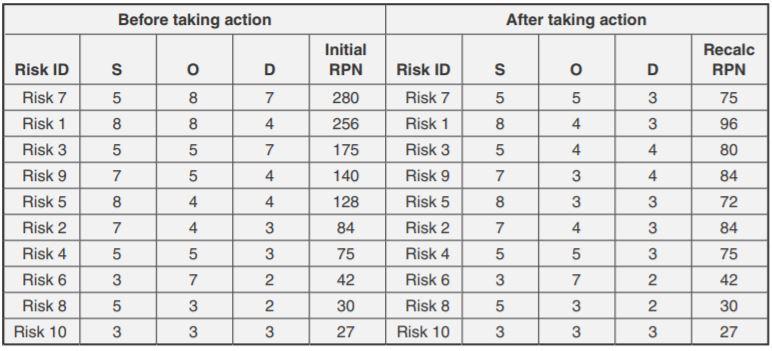
PFMEA can be applied when: new technology/process introduced current process with modifications current process exposed to new location hence it can be applied in following ways: Define: Project risk analysis including Resources, Timelines, Serviceability Measure: Measurement error quantification, MSA validation and Statutory risks Analyze: Resolve contradictions to reflect before/current conditions, prior to a pilot Improve: Improve function to the extreme to reflect after conditions, after the pilot Control: Corrective/productive functions in control plan to ensure/restore control