

Mike
Members
-
Joined
-
Last visited
-
Value stream mapping is a Lean management tool that is used to visualize, analyze and improve the current flow of process that is required to service a customer. It provides a high level and end-to-end map of the process workflow, identifying inefficiencies, bottlenecks and areas of improvement. Value stream mapping has some key features that makes it a very valuable tool for any organization to implement on a workflow that may be new or old. Some notable features are listed below., 1) Visual Representation: Value stream maps are commonly depicted visually using flowcharts that shows each and every step involved in a process from start to finish 2) Focus on Value Addition: Value steam maps distinguish between value added activities (gives a positive outcome e.g. Customer satisfaction) and non-value-added activities (waste) 3) Two States: · Current State VSM: Shows the existing process map and highlights inefficiencies · Future State VSM: Proposes an optimized process that eliminates inefficiencies and has an improved flow Value stream maps can be applied in Manufacturing, Services, IT and Healthcare industries. How to identify inefficiencies in Current State VSM: Once the process has been mapped from start to finish, we need to identify all the steps that add value to the process and those that do not add value to the process. There may be steps that need to be present so that it adds value to another step in the future and is not necessarily a non-value-added step in the process right now. So, it is very important to see that we do not remove them as waste. Inefficiencies such as bottleneck, redundancies, delays or waste (remember 7 wastes) are key contributors to processes getting misaligned with the organization’s strategic goals such as Customer experience, reducing cost etc., As a service industry example, if we were to map the journey of a patient from admission to discharge the current VSM may reveal help you identify inefficiencies like., a) Long waiting time – In multiple places b) Multiple data entry points c) Unutilized resources like staff, medical equipment etc., Designing a Future State VSM that aligns to Organizations goals: The future state map is one that helps to eliminate the inefficiencies and aligns the process to the organization’s goals. It incorporates lean concepts like flow, pull and eliminate waste while the ensures that the goals are met. This delivers immense and immeasurable value to the organization. It ensures that we focus on A) Customer-Centric Goals – Ensure Customer Satisfaction has the highest priority in any process Efficiency Goals – Create Efficient workflows by reducing operating cost and increasing meaningful results C) Scalability Goals – We will be able to handle higher volumes of patient inflow in the future Taking the same service industry example, if we were to map the journey of a patient from admission to discharge the future state VSM will implement solution like., a) Real time monitoring of patients progresses at each touchpoint with proper scheduling b) Single source of data for all shared services to access patient detail via a Database c) Optimizing resources at each touchpoint based on usage and demand The above solutions will help in streamlining the process and ensure that patient satisfaction and comfort are prioritized while providing the best medical care. This aligns with the organizations goals of providing premier patient care while delivering the best-in-class medical care too. Forum Q10 - C&F-VSM.docx
-
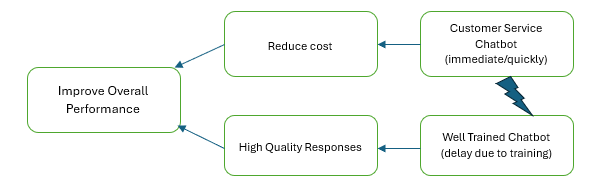
Evaporating Cloud Technique is a conflict resolution technique that is one of the processes of Theory of Constraints. It was introduced by Dr. Eliyahu Goldratt to solve difficult problems that have no clear solution. It resolves the conflict by stating both sides of the problem and reviewing the underlying assumptions that create the conflict. The EC diagram depicting the current problem statement is shown below., Here the conflict arises from two opposing needs, but the goal is the same to improve overall performance NEED A: To deploy customer service chatbot to reduce cost immediately NEED B: To delay deployment so that a well trained chatbot that gives high quality responses is deployed Let us now state the underlying assumptions., a) Deploying the bot quickly will save cost but stand the risk of low customer experience b) Delayed deployment of bot due to training ensures high quality responses but does not give immediate saving c) Reducing cost and getting high quality responses are mutually exclusive d) If chatbot is deployed it cannot learn quickly and improve on quality We need to a challenge the above assumptions to find a win-win solution. Challenging the above we see that we can build a solution that will address both goals. 1) To mitigate issues caused by delayed deployment and to also ensure high quality response, we can deploy the bot in phased manner to address such simpler queries to start off with and parallelly train the bot on much complex queries as it continuously learns over time. This ensures that quality is not compromised, and immediate savings are also realised 2) We can also do a Pilot testing by deploying the bot for limited section of the customers thereby avoiding potential risks or at least minimizing it. This will help improve quality in the long run before full deployment and save cost immediately 3) We can also use Human in loop to answer complex queries and let the chatbot handle much simpler queries ensuring customer trust 4) We can also use the feedback loop post launch and improve the chatbot performance over a period making it handle simple and complex queries. This ensures continuous or real time learning Hence the company can design a Phased and iterative solution to save reduce costs and sustain acceptable quality. This approach stated above will bring in a win-win situation to the company ensuring benefits in terms of reduced cost in the short run and better customer experience in the long run.
-
AI Hallucinations occur when LLM’s make up answers that are not factual. This mostly occurs when the model tries to be extra helpful by fabrication information when the model does not have a factual backing for the data presented. This also occurs when the model has not been trained on that topic. Prompt engineering techniques focus on guiding models to produce truthful or factual data for any query. By refining these prompts, we can minimize the number of hallucinations produced by AI and increase the overall performance of the AI system. Some of the practices we can follow to reduce hallucinations ae listed below., 1) Give clear and precise prompts avoiding ambiguity that may provide irrelevant output 2) Explicitly state the context with some additional background information 3) Break down the tasks into smaller manageable steps ensuring that AI models understand it easily 4) If need arises specify the output format required for the answer 5) Incorporate examples to get the desired output 6) Ask the model to differentiate between factual vs speculative answers 7) Ask the model to prove the references for the source of the information and prove its limits or in simpler terms ask the model to validate its own responses 8) Usage of domain specific terminology also helps to align responses reducing nonsensical information When working with highly specialized domains, we can use some of the below mentioned methods to reduce hallucination., 1) RAG – Retrieval Augmented Generation: This method combines the model’s capability to generate information with reliable information sources like knowledge bases. Example: Who is called the “Father of the nation” in India? This will make the model look up information in the knowledge base before generating a response. Likewise, if any question is asked pertaining to a specific domain the model will investigate the relevant knowledge bases before responding 2) ReAct Prompting – Reasoning + Acting: This method is used reduce hallucination by incorporating a step-by-step reasoning and an external tool such as an API to ensure that the responses are grounded in factual data. Example: In medical diagnosis, instead of asking for symptoms of a disease, we break down the question into smaller steps and narrow down to the specifics based on reliable medical data and then ask it to respond with prognosis There are several other methods to reduce the impact of hallucination in generative AI but there is still a long way to go to build trustworthy intelligence as the knowledge bases are vast and susceptibility to nonfactual information which is a reality today.
-
Self-serving bias is the human tendency to attributes success to internal factors and failures to external factors. For Example: A Manager may attribute the success of the project to his skills of management but will attribute the failure of the project to the team’s skill or situation that were not conducive to complete the project successfully. In Six Sigma, Self-serving bias can have a very significant impact on identification of root causes. It will lead to inaccurate root cause analysis where reasons may be flawed, poor judgement will arise and ultimately leading to ineffective problem solving. Team members may refuse to accept accountability for the mistake contributed by them which will impact the solution. Attributing possible root causes to external factors like market conditions rather than key internal factors like process inefficiencies. Selective data interpretation can also lead to bias. Strategies to mitigate self-serving bias: 1. Training & Awareness: Six Sigma practitioners should be trained to recognize and address bias. They should be encouraged to build a culture of data integrity, objectivity and critical thinking 2. Data Transparency: Ensure that all data collected is transparent and documented and report anomalies 3. Diverse Teamwork: Ensure that cross functional teams are be enabled to provide root cause analysis, challenge assumption and biases in the project via calibration sessions 4. Data Driven Decision Making: Ensure all decisions made are based on data. No assumptions are to be made, Discussions should be done on factual data. 5. Declare Assumption: All assumptions should be avoided. But if assumption is necessary then it must be well documented. 6. Usage of Proper tools and Statistical approach: 5 why, Ishikawa diagram and affinity diagrams should be used to systematically explore root causes. Sensitivity analysis can be performed to weigh in the impact of assumptions. 7. Independent or Peer review: Use project enthusiasts to review the analysis and findings. Six Sigma certified peers can be used to question the usage of assumptions Hence during analysis phase, a clear plan needs to be developed so that we can check the effectiveness of process improvement. We should also be able to identify and mitigate such bias. Using the above-mentioned strategies will help us enhance the integrity of the project and deliver proper results.
-
Quantile based analysis involves dividing the dataset into equal segments in size based on the data values and analysing these data segments to understand the distribution of data. We will be able to interpret data distribution by looking at the median, spread and extremities of the data. Benefits: 1) Simple and Flexible: This type of analysis is easy to compute when summarizing large data sets and is applicable to any type of numerical data regardless of distribution type 2) Robustness to Outliers: The data set when analysed is least sensitive to outliers. It can reveal skewness of a distribution (Left or Right) or if they are symmetrically distributed. 3) Targeted Analysis via Segmentation: Since data is divided into meaningful segments, each segment can be analysed separately to make decisions Limitations: 1) Sample Size issue: Accuracy of quantile estimates can be impacted if the sample size is very small 2) Relationship issue: This type of analysis does not establish relationships between variables Example of usage: 1) Healthcare: In healthcare, we can use quantile-based analysis to segment patients based on health parameters to understand the risk 2) Marketing: Customer grouping can be done to study customers based on spend patterns for developing market strategies. Challenges in real world data: 1) Missing data: Missing data can impact the accuracy of the quantile estimates and affect the outcome or interpretation 2) Dynamic Data issue: Quantile based analysis cannot be applied to dynamic data as constant recalculation of quantiles for each update can be challenging and becomes a never-ending process.
-
Short-terms benefits and long-term value creation when assessing ROI from AI solutions depends on a few important factors and their impact on the organization. They may be referred to as metrics used to gauge the impact. They are listed below., 1) Time 2) Cost savings 3) Revenue reduction 4) Satisfaction / Experience Short-Term Benefits: These types of benefits are the benefits that are realized in a very short period (6 months to a year). Intelligent Automation (IA) can be used where repetitive tasks can be automated thereby freeing resources and improving operational efficiencies. This brings about cost savings. AI can very efficiently be used to work with large volumes of data to make better decisions rather than having an analyst surf though it for ages before a decision is made. Hence faster decision making is a short-term benefit that can arise from AI where decisions can be made in real time because of readily available insights. Faster solutioning can be done using pre-trained models readily available in the market to achieve the business goal. These AI products have enhanced predictive analytics that can accelerate the development of the product or solution. Hence from a Short-term benefit point of view, assessing the ROI on an AI solution will depend on the following factors., Cost Savings, Faster decision making and Faster solutioning Long Term Value Creation: These types of benefits are realized in the long run with a 3–5-year strategic goals for the Organization. Scalability: Any organization that plans to scale needs to invest in infrastructure. Organizations must make investments in AI infrastructure if that are to scale faster and efficiently. This provides a competitive edge over others in the same market. Transformation: Organizations transform as they grow. It is also important for the organization to upskill employees to work with the AI technologies. This will also enable the population to make better decisions. Customer Loyalty: In the terms, AI can enhance customer satisfaction and employee experience through personalized support and proactive problem solving. To maximize ROI on AI solutions, it is always prudent to start small and scale gradually focussing on high impact areas. Creation of Cross functional teams is critical as all-round expertise is required to build such solutions. Last of all we need to ensure that the solution that is being prepared is Monitored continuously to see if will deliver the intended goal.
-
Let us first understand what are RPA and Hyperautomation? RPA or Robotic Process Automation is a software technology that helps build, deploy and manage software robots that emulate human action and can interact with digital systems and software. RPA is a simple rule-based system that will automate repetitive tasks done by a human in a process. Hence RPA is process driven. Hyperautomation is more of a strategy than a technology. Hyperautomation is a strategy that applies AI powered automation with advanced technologies, tools and systems to streamline and optimize processes. Hyperautomation aims to automate complete business processes (as many tasks as possible) while RPA work on standalone functions. There is a key bridge between Hyperautomation and RPA. Intelligent Automation or IA as they call it, is all about using AI, NLP and ML technologies with RPA to bring intelligence into processes. While RPA can be a single tool, IA uses multiple tools. IA provides the core capabilities towards Hyperautomation. IA ensures seamless interoperability and integration of the enterprise systems which are key to driving the process towards Hyperautomation. There are several industries that can benefit from hyperautomation. Industries like Insurance, Manufacturing, Healthcare and banking can benefit immensely from hyperautomation. 1) Insurance: Claims processing time can be accelerated and accuracy can be increased. It can strengthen compliance and broaden connectivity across systems to make better decisions 2) Manufacturing: Using computer vision powered by AI, it can reinforce quality assurance by checking and assessing products for quality, defects and apply corrective actions 3) Healthcare: In healthcare, it can streamline administrative tasks to reduce errors during billing and other also securely handle sensitive data. Hence compliance is ensured 4) Banking: In banking it can ensure that complex tasks like loan initiation and its associated activities are automated to improve efficiency, TAT and cost According to Gartner, 3 Key strategies are required for enabling hyperautomation in any organization. 1) Plan the Process Automation Journey 2) Apply Digital-Ops Toolbox (for integration) 3) Augment with AI How do we bring Hyperautomation together? “Integration” is key to the success of implementing strategies like Hyperautomation. Integration Systems, API’s and iPaaS serve as foundation to Hyperautomation allowing large scale complex workflows to be automated. A platform is provided for systems that are disparate to be interconnected, streamlined, work real time and have data exchanges done easily. Pre-built API’s and Connectors offer easy integration. Cloud facilities like iPaaS provide support to execute automations. Generative AI can be brought in to accelerate hyperautomation strategies by automating and augmenting multiple aspects of automation lifecycle and business process execution.
-
In Six Sigma Projects, we often need to analyze data and draw conclusion about the population from the data given. There are two types of statistical tests that can be done depending on the distribution of data. If the data is normally distributed, then we use parametric test. If the data is non-normally distributed, then we can use non-parametric tests. Non-parametric tests are also referred to as distribution free tests. In non-parametric test measure the central tendency using the median values. Predominantly such tests are done on nominal/ordinal/skewed data where population knowledge is limited. Nominal data means that data cannot be arranged in any specific order and no mathematical calculations can be performed. Example: Blood groups for a human being, Gender, Religion. Ordinal data contains data that can be arranged in an order but cannot be computed. Example: school grades, ranking of products Non-Parametric test can be used in Healthcare, Pharmaceutical, Manufacturing and Media industries (rating/ranking). How are they used across the above industries: 1) In the Media or Film industry: Comparing the ranking of movies A, B and C across different age groups. We can compare the median ranking of different age groups to see if there is a significant difference 2) In the Pharmaceutical industry: We can use non-parametric test to compare data. Eg: Comparing the adverse effects of different type of covid vaccines 3) In the Healthcare industry: We can use non-parametric test to compare patient satisfaction levels acquired from internal surveys 4) In the Manufacturing industry: We can use non-parametric test to compare before and after results Eg: Performance of a machine after a new part has been fitted. There are several kinds of non-parametric test with their functions listed below., 1) Mann- Whitney Test: to compare continuous outcome in 2 independent samples 2) Kruskal-Wallis Test: to compare continuous outcome in > 2 independent variables 3) Friedman Test: to compare difference between 3 or more groups 4) Chi-Square Test: to categorical variables for Independence 5) Mood Median Test: to test medians of two independent samples 6) Sign Test: to compare continuous outcome in matched pairs of samples 7) Wilcox Test: More powerful than sign test and compare the magnitude of difference
-
Let’s understand what a knowledge management system is. Knowledge management system (KMS) can be seen as an entity like an IT system in an organization that implements knowledge management. It will deal with organising, storing and retrieving a lot of knowledge relevant to the various processes within the organization. It ensures that the necessary information is available on demand and can be used for process guidance. Well, what is a knowledge base then? Knowledge base (KB) can be defined as a centralized repository of information that relate to policies and procedures. It also helps you create, store and share documents across your company. It is made available to the employees for easy access in case any guidance is needed. Now what are the common reason for a KB becomes unusable in a KMS? Some of the common reason that contribute to KB becoming unusable are listed below. 1) Poor user experience 2) Incomplete knowledge base 3) Complex knowledge base 4) Low user adoption 5) Easy access 6) Poor structure 7) Outdated content 😎 Security issues 9) Scalability issues How do we ensure that these reasons are mitigated? What are some of the strategies that can be employed to improve the usability of the knowledge base are listed below., 1) Structuring a knowledge base – Using a proper hierarchy, tagging and linking content 2) Optimizing a knowledge base – Employing proper search engines 3) Knowing your audience – Understanding user groups and their search patterns 4) Promoting the knowledge base – Ensuring that the KB is promoted to resolve FAQ’s and Complex searches 5) Collecting feedback – User feedback on the KB usability and its effectiveness 6) Scalability ready – Easy Integration with advanced technologies 7) Easy Transition – Version control adaptations 😎 Broadcasting Updates – Ensure all users are notified about updates through various channels (Chat, Email, etc.,) We can ensure that the usability and effectiveness of a KB can be drastically improved if the above are adopted. With the future of technology focussed on Artificial Intelligence, Knowledge bases can be used extensively with AI to increase reachability, robustness, accuracy and effectiveness. In terms of Organizing the KB, AI can help in streamlining content. AI can use NLP to understand and interpret the user’s intent behind the queries asked. AI can help in organizing information effectively by employing Hierarchical structuring, identifying metadata and tagging and help in content linking. In terms of efficient retrieval of information, AI can help in optimization in searches. This enhances performance and improves user experience. AI also offers multilingual support. AI can be used to take the existing SOP’s into near accurate decision trees by analysing data, identifying patterns and generating new content. AI enhances data security. Bringing in AI allows us to incorporate Analytics of the highest order giving us insights on user interactions, common queries (FAQ’s) and thereby system performance. Over time this will lead to better and accurate answers. As a closing statement, while a knowledge base as an entity is susceptible to failure, Artificial Intelligence can bring in higher robustness, greater effectiveness and a level of security to ensure that the Knowledge base remains usable and relevant across time.
-
Let’s first understand what a BRD is. BRD in short stands for Business Requirement Document. What is the purpose of a BRD? Business Requirement Documents are used extensively to do the groundwork before building a new application. They are used to gather all business requirements and hence it also outlines the objectives and expectations of a project from a business perspective. Now let us see what are the basic components of a BRD? A basic BRD will need to contain some of the below mentioned., 1. Project Overview & Objectives 2. Project Scope & Constraints 3. High Level Architecture 4. Stakeholder Identification 5. Identifying Roles and Responsibilities 6. Business requirements | Security & Compliance 7. Defining Success Criteria and KPI’s 8. Quality control measures 9. Cost-benefit analysis All the above if documented correctly will ensure the success of the project. Each component by itself is a key to the project’s success. Next, what is the importance of a BRD? BRD’s ensures that there is alignment on business goals, it ensures that there is clear communication of what needs to be done between the stakeholders and the technical teams, and it also covers the Risk mitigation elements which helps to identify potential challenges and allows for proactive solutioning for the project’s success. So, in-short from a Tech product or a Tech Tool perspective, BRD is the starting point for any software project or business solution design and development. Now that we understand what a BRD is and what are the components and what is the importance of a BRD for a project, let us address the main question “Is it correct to say that most failures in a Tech Product or Tech Tool can be traced back to a flaw in the Business Requirement Document (BRD)?” The Answer is YES. Most Tech Product or Tech Tool failures can be traced back to a flaw in the BRD. Sometimes even design and development failures are influence by a BRD to an extent. Let us look at an example’s situation. 1. Failure Example of Data breach: Company A developed a product (HIYE – How Is Your Experience) that ensure that all in-patient feedback is collected in an app which will help assess the experience during hospitalization. This Product will collect real time data from the patients, analyse data and deliver insights on experience. These reports will be released to the hospital administration. From this data set hospitals will be able to understand patient sentiments, staff responsiveness, facility rating and other services provided that have influenced the overall satisfaction rating. What happened: Personal data of patients was exposed due to security breach Cause of Failure: Inadequate Data Protection Policies and Procedures Impact on Company A: Multiple lawsuits levied against them leading to hefty fines leading to huge expenses impacting financials and margin in adding to loss of reputation. How could have this been avoided: A BRD must clearly state and capture all data protection policies and procedures followed as per the industry standards to ensure that there cannot be a breach of any sort of security or data leakage. All stakeholders must sign off on this and the regulatory boards consent is required before the product is placed on the market. All this can be done during the testing stage itself using ethical hackers to hack into the system and see how strong the product is. From time to time after the product has gone live, the team must ensure that the latest policies and procedures are rolled out based on the evolving statuary standard. ISO standards must be followed. 2. Failure Example of User Privacy and Data Ethics: Company A developed a product (HIYE – How Is Your Experience) that ensure that all in-patient feedback is collected in an app which will help assess the experience during hospitalization. This Product will collect real time data from the patients, analyse data and deliver insights on experience. These reports will be released to the hospital administration. From this data set hospitals will be able to understand patient sentiments, staff responsiveness, facility rating and other services provided that have influenced the overall satisfaction rating. What happened: Company A shared patients’ sensitive data for research to a third-party consultancy Cause of Failure: Inadequate Data handling practices and failure to obtain user consent Impact on Company A: Regulatory fines levied | Trust factor impacted and hospitals refused to adopt the app leading to lower customer base and business loss How could have this been avoided: A BRD must clearly state and capture all data handling practices must maintain user privacy and cannot be used without user consent. Ethical handling and consent mechanism are vital to maintain user trust and comply with laws. GDPR standards must be followed to comply with privacy laws. How do we ensure that these kinds of failures do not happen. There are some key best practices that we can follow to avoid these major setbacks. They are listed below., a. Clarity & Precision – Use clear language to define technical and compliance terms. Avoid ambiguity and use standard terms that are consistent throughout the document b. Stakeholder Management – Ensure a collaborative effort is done in requirement gathering phase. Ensure that the stakeholders needs are balanced, and a regular communication channel is always open to address updates and realignments c. Document Organization – A proper hierarchical structure needs to be followed in document organization. Hence structure is key to success. Usage of templates signed off by all parties is a way of standardizing documentation which allows ease of understanding. Usage of visual aids like flowcharts and diagrams should be encouraged. d. Documenting Ethical considerations – Explicit ethical requirements need to be captured. Bias mitigation strategies should be employed. Transparency and explain-ability are key to behaviour and decision-making process. e. User Privacy and Data Ethics – Data handling practices need to be defined to maintain privacy. Compliance with privacy laws such ad GDPR are mandatory f. Governance Framework – Clear governance and accountability structures that define how the company manages user information/content. Policies and Procedures that are essential for data governance and security. Oversight mechanisms to ensure safety and compliance. g. Regulatory Compliance – Addressing Legal requirements during planning. Employing compliance strategies for legal and financial sustainability. h. Security Requirements – Ensuring strong security standards and protocols (ISO). Threat modelling or having a team work on hacking the system internally that can proactively identify and mitigate security threats. Having an incident response plan that ensures rapid detection to security incidents. If all the above recommended practices are followed, BRD creation will turn out robust and reduce if not prevent tech product or tech tool failures.
