

Vinit Dubey
Members
-
Joined
-
Last visited
Everything posted by Vinit Dubey
-
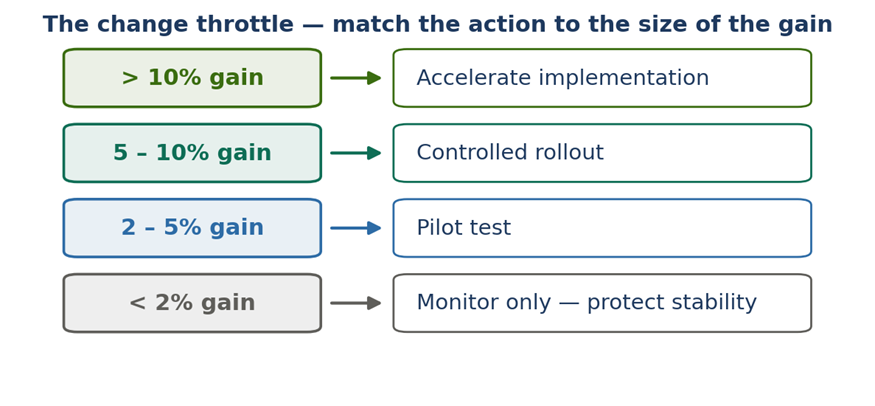
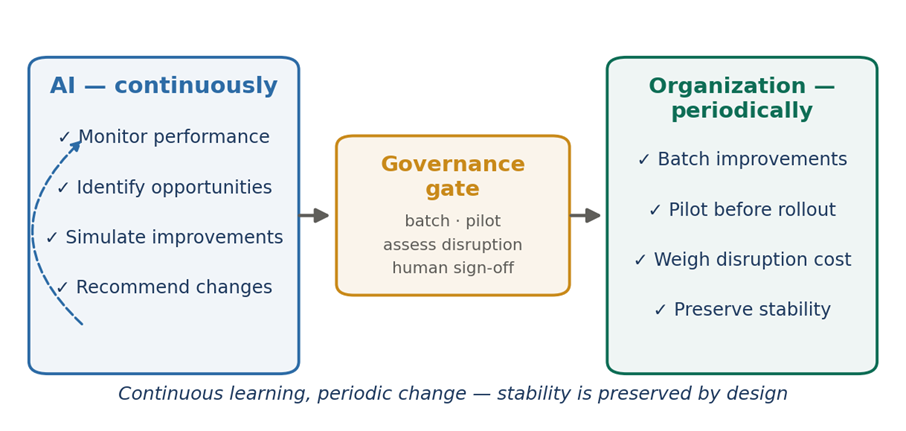
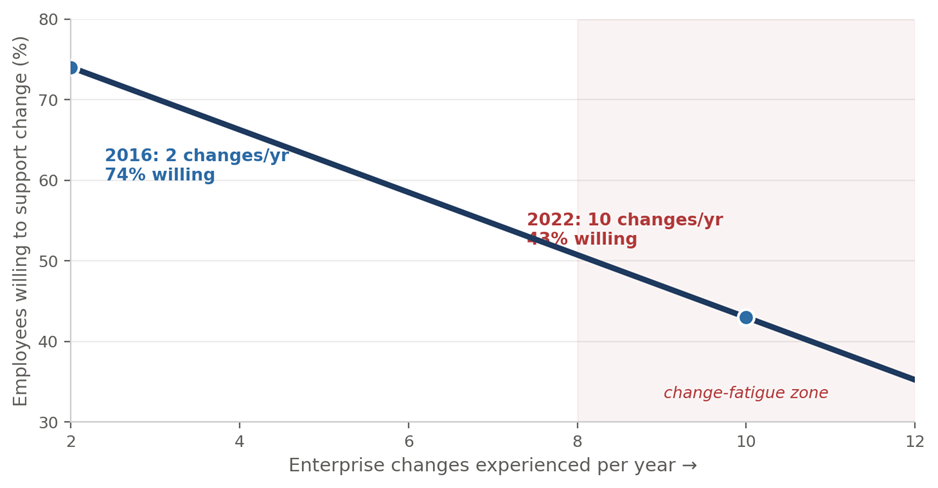
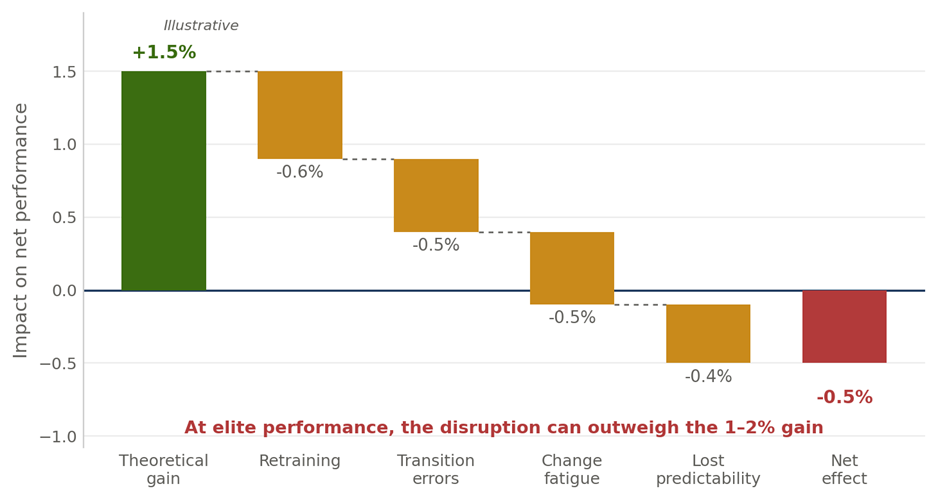
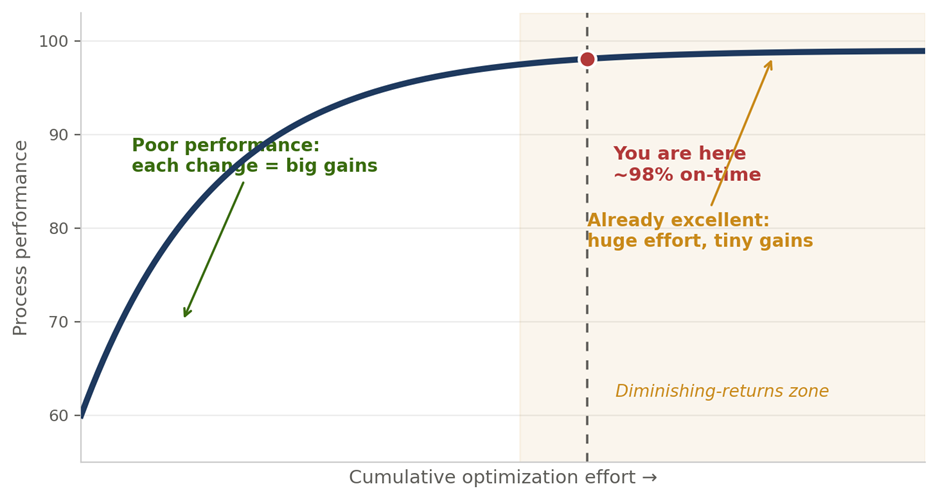
Stability as Strategy Should AI continuously change a process that already performs at an elite level? A position paper in support of View B — Prioritize stability and consistency Case context: e-commerce order fulfilment · 98% on-time delivery · AI proposing continuous 1–2% changes Position. Once an operation reaches elite performance 98% on-time delivery, high satisfaction, stable costs — the greatest threat is no longer inefficiency; it is uncontrolled change. AI should keep learning, monitoring, and recommending continuously. But the organization should adopt those changes selectively and deliberately, because at this level employee confidence, process consistency, and execution reliability are usually worth more than another 1–2% gain. Executive summaryAI is exceptionally good at finding micro-optimizations. Organizations, however, run on people, processes, training, governance, and execution discipline and a continuous stream of AI-driven adjustments can create more operational friction than value. The question is not whether improvement is good. It is whether a 1–2% theoretical gain is worth introducing instability into a process that already works extremely well. In most large-scale operations, the answer is no. This paper argues for View B: let AI learn continuously, but let the organization change periodically and on purpose. 1. Why continuous optimization can become a problem1.1 AI sees local improvementsAn optimization engine evaluates a narrow slice of reality and scores each recommendation in isolation: • Route efficiency, staffing utilization, and inventory placement • Demand forecasts and fulfilment priorities Every recommendation can look beneficial on its own because the model is not pricing in what it cannot see. 1.2 Organizations experience cumulative changePeople do not experience an optimization; they experience the disruption of adopting it new procedures, new priorities, new training, new performance expectations. What looks like a small tweak to the algorithm can feel like a major upheaval on the floor. 1.3 The hidden cost of frequent changeAI benefit (measured) Potential human cost (absorbed) 1% better routing Drivers relearn procedures 2% lower staffing cost Scheduling confusion 1% inventory improvement Warehouse retraining 1% faster fulfilment Increased operational complexity Better forecasting Constant process revisions Table 1: The AI measures the benefit; the organization absorbs the disruption. The two rarely sit on the same balance sheet. 2. The performance plateau: the law of diminishing returnsWhen a process performs poorly, every change produces large gains. When it already performs excellently, the same effort produces a sliver. A 98%-on-time operation sits firmly in the flat part of the curve the diminishing-returns zone where huge effort buys almost nothing, and the risk of the change often exceeds its reward. Figure 1: At elite performance, the optimization curve has flattened. More change yields less, while the disruption it causes stays just as real. Netting the disruption against the gain makes the trap explicit. A 1–2% theoretical improvement, once you subtract retraining, transition errors, change fatigue, and lost predictability, can land below zero. Figure 2 (illustrative): At elite performance, the cumulative cost of absorbing a change can outweigh the headline gain — turning a “win” into a net loss. 3. Change fatigue: the most underestimated riskChange fatigue is real, measurable, and accelerating. According to Gartner, the average employee experienced 10 planned enterprise changes in 2022, up from just two in 2016 and over the same period the share of employees willing to support change collapsed from 74% to about 43%. The performance consequences are equally concrete: fatigue can cut employees’ intent to stay by up to ~42% and their performance by up to ~27%, and 77% of HR leaders now report fatigued staff.[1][2] Figure 3: The more change an organization pushes, the less of it employees are willing to absorb. Past a threshold, additional change actively destroys adoption quality. The failure mode is predictable. A drumbeat of monthly changes trains employees to disengage: Month AI recommendation pushed live January New staffing model February New inventory rules March New routing logic April New prioritization model May New exception-handling process Table 2: After a few cycles, employees conclude “this will change again next month anyway.” Adoption quality drops, and measured performance follows. 4. Evidence from operations that prize stability4.1 Toyota — the real lesson of KaizenToyota is the world’s reference point for continuous improvement, and it is routinely misread as “change everything, all the time.” It is the opposite. Toyota’s system rests on standardized work and stable processes; improvement is identified, tested, verified, and only then standardized and rolled out. Stability is not the enemy of improvement it is the precondition for it. If procedures change constantly, employees never master them, and there is no stable baseline against which to measure whether a change actually helped. 4.2 Amazon — advanced AI, deliberately throttledAmazon runs some of the most advanced operational AI on earth, yet it does not push every algorithmic recommendation straight to the floor. Its fulfilment centers involve hundreds of thousands of employees, complex workflows, safety procedures, and training programs. A routing tweak that looks valuable mathematically can be net-negative if it raises worker confusion, creates safety risk, or depresses productivity during the transition. Amazon’s answer is to pilot and validate extensively before large-scale deployment continuous learning, governed change. 4.3 Airlines — reliability over marginal optimizationCarriers such as Delta, Singapore Airlines, and Lufthansa could let AI continuously reshuffle crew schedules, gate assignments, and maintenance windows. They deliberately don’t, because the cost of churn lands on the people who keep the operation safe and on-time: Affected group Impact of excessive operational change Pilots Training burden and recertification load Ground staff Process confusion and handoff errors Maintenance teams Coordination failures and safety risk Passengers Inconsistent, less trustworthy experience Table 3: Airlines prioritize operational reliability over marginal optimization, because reliability — not a 1% efficiency gain — is what earns customer trust. 4.4 Microsoft Windows — the product analogyMicrosoft improves Windows continuously, but imagine if menus reshuffled weekly, shortcuts changed monthly, and settings moved every few weeks. Users would revolt despite every change being a technical “improvement,” because people value predictability, familiarity, and consistency. The same is true of an operational workforce: a stable experience often creates more value than endless optimization. 5. Applying it to the e-commerce caseThe case company is already operating at the top of the curve. Its strengths are precisely the things that frequent change puts at risk: Metric Current performance On-time delivery 98% Customer satisfaction High Operational cost Stable Employee knowledge Strong Process consistency High Table 4: Current state — an operation that has already achieved excellence. Against that, the AI proposes a bundle of changes whose combined theoretical upside is only 1–2%: Proposed change Expected gain Staffing changes +1% Routing updates +1% Inventory reallocation +2% Priority adjustments +1% Table 5: AI recommendations — a total theoretical gain of roughly 1–2% after overlaps. And the organizational cost of absorbing that bundle is both real and, at this performance level, plausibly larger than the gain: Impact area Risk introduced Training Increased effort and downtime Execution More mistakes during transition Employees Change fatigue and disengagement Managers Lower predictability and control Customers Temporary service degradation Table 6: Potential organizational cost — which, netted against a 1–2% gain, can leave the company worse off. 6. The operating model: continuous learning, periodic changeView B does not switch the AI off it puts the organization, not the algorithm, in charge of the cadence. The AI should run continuously; the organization should change deliberately. Figure 4: The AI monitors, identifies, simulates, and recommends continuously. A governance gate batches, pilots, and weighs disruption before the organization implements — so stability is preserved by design. In short: • ✓ AI should monitor, identify, simulate, and recommend continuously. • ✓ The organization should batch improvements, pilot before deployment, weigh disruption cost, and preserve operational stability periodically. 7. Strategic recommendation: the change throttleThe practical decision rule is to match the response to the size of the opportunity. Tiny gains are monitored, not chased; only large, proven gains earn fast-tracked rollout. This protects stability while still capturing the improvements that genuinely matter. Figure 5: A change throttle — below 2%, monitor only; 2–5%, pilot; 5–10%, controlled rollout; above 10%, accelerate. The bundle in the case (1–2%) sits in “monitor only.” 8. ConclusionThe strongest organizations do not implement every opportunity an AI discovers. They recognize that stability itself is a competitive advantage. A process delivering 98% on-time delivery, high satisfaction, and stable costs has already achieved operational excellence; at that level, employee confidence, process consistency, and execution reliability typically outweigh another 1–2% of efficiency. The lesson from Toyota, Amazon, and the major airlines is consistent: continuous learning is essential, but continuous change is not. Final position. AI should continuously identify improvements, but the organization should adopt them selectively and deliberately. Long-term success comes from balancing innovation with stability not from letting algorithms rewrite proven processes every day. For the case company, the right move is to let the AI keep watching and recommending, batch and pilot anything material, and leave the 1–2% bundle in “monitor only” until it clears the throttle. Sources1. Gartner Workforce Change Survey — via Harvard Business Review, “Employees Are Losing Patience with Change Initiatives” (2023); Gartner Business Quarterly, Q1 2023 (2 → 10 enterprise changes; 74% → ~43% willingness). 2. Gartner change-fatigue research, summarized in change-management reporting (2023–2025): intent-to-stay down up to ~42%, performance down up to ~27%, 77% of HR leaders report fatigued employees. 3. Toyota Production System — standardized work and controlled, verified improvement as the basis of Kaizen (Liker, The Toyota Way; Toyota operational literature). 4. Amazon — public reporting on piloting and validating operational changes before large-scale fulfilment deployment. 5. Airline operations — industry practice on operational reliability (Delta, Singapore Airlines, Lufthansa). This is a position paper arguing View B. It is fully compatible with continuous AI learning; its claim is narrower and specific — that change adoption, not change discovery, should be governed and paced. Illustrative figures are labelled as such. [1]Gartner Workforce Change Survey, reported via HBR (“Employees Are Losing Patience with Change Initiatives,” 2023) and Gartner Business Quarterly (Q1 2023): the average employee faced 10 planned enterprise changes in 2022, up from 2 in 2016, while willingness to support change fell from 74% to ~43%. [2]Gartner, cited in industry change-management reporting (2023–2025): change fatigue can reduce employees’ intent to stay by up to ~42% and performance by up to ~27%, with 77% of HR leaders reporting fatigued employees.
-
I Strongly Support View B — Adjust for Circumstances The belief that evaluating only results is "objective" sounds appealing, but in reality it often measures opportunity rather than performance. AI should evaluate not only what people achieved, but also the difficulty of achieving it. Otherwise, organizations risk rewarding employees who had easier conditions while penalizing those who took on the toughest challenges. Scenario 1: Customer Support and Case Complexity Many customer service organizations distinguish between routine inquiries and escalated cases because they require different levels of skill and effort. Consider Two Agents Agent A Handles 120 simple password reset requests per day Customer Satisfaction (CSAT): 96% Average Handling Time: 3 minutes Agent B Handles 45 escalated complaints involving service failures, billing disputes, and angry customers Customer Satisfaction (CSAT): 89% Average Handling Time: 20 minutes A results only AI would likely rank Agent A higher. However, most business leaders would recognize that Agent B is handling significantly more difficult work and protecting customer relationships that are at greater risk of churn. If Employees Know AI Evaluates Only Raw Results They will avoid difficult cases They may transfer escalations to others The organization's toughest customer problems receive less attention A context-aware AI prevents these unintended incentives. Scenario 2: Sales Performance Many global companies adjust sales targets based on territory potential because not all markets are equal. Consider Two Sales Representatives Sales Rep A Assigned a mature territory with strong brand recognition Receives 500 qualified leads per month Generates $2 million in revenue Sales Rep B Assigned a new market with little brand awareness Receives 150 qualified leads per month Generates $1.5 million in revenue A results-only system rewards Rep A. However, Rep B may have achieved significantly more relative to the opportunity available. Why Organizations Adjust for Context Territory weighting Market potential adjustments Opportunity scoring Without these adjustments, top performers may simply be those assigned the easiest territories. Scenario 3: Healthcare Healthcare organizations routinely account for patient complexity when evaluating outcomes. A surgeon performing routine procedures typically has lower complication rates than a surgeon handling high-risk cases. If Hospitals Measured Only Mortality rates Readmission rates Complication rates Doctors might avoid treating the sickest patients to protect their performance scores. How Healthcare Solves This Many healthcare systems use risk-adjusted outcome measures, accounting for: Patient age Existing medical conditions Severity of illness The goal is not to excuse poor performance but to compare professionals fairly. Key Lesson The most accurate performance measurement often requires contextual adjustment. Scenario 4: Education Many education systems have moved away from evaluating teachers solely on student test scores. Teacher A Teaches high-performing students from affluent backgrounds Students score highly on standardized tests Teacher B Teaches students facing economic hardship and learning challenges Students show significant improvement but still score lower overall If AI evaluates only final scores, Teacher A appears superior. If AI measures student growth and starting conditions, Teacher B may actually be delivering greater educational impact. Modern Approach Many educational performance frameworks emphasize: Student growth Improvement over time Value-added measures Rather than relying solely on raw outcomes. Scenario 5: Professional Sports Even elite sports organizations recognize that context matters. In football, basketball, and baseball, analysts increasingly use advanced metrics that adjust for: Strength of opponents Team support Game situations Quality of opportunities Example A striker scoring 20 goals against weaker teams is not automatically considered better than a striker scoring 15 goals while facing stronger opponents and creating opportunities with less support. Modern sports analytics focus on performance relative to difficulty, not merely raw results. If professional sports—which are intensely results-driven—recognize the importance of context, organizations should do the same. The Core Problem: AI Anchoring Bias in Performance Reviews Research demonstrates a fundamental flaw in AI-assisted evaluations: Anchoring Bias. When managers receive an AI-generated performance score, that number becomes a mental anchor a reference point that heavily influences their final judgment, even if the AI's recommendation is incomplete or flawed. This is not a hypothetical concern. In controlled experiments involving 775 managers, researchers found that performance ratings were significantly influenced by AI recommendations. A high AI score led to different final evaluations than a low AI score, even when employee behaviour remained identical. The Risk If AI lacks context about an employee's challenging circumstances, the resulting anchor can systematically undervalue employees working under difficult conditions. How Companies Are Getting It Right (and Wrong) BCG: Evaluating Judgment, Not Just AI Output Boston Consulting Group (BCG) has integrated AI deeply into its operations, with nearly 90% of employees using AI tools and around half using them daily. However, BCG has redefined performance measurement. BCG Focuses On Problem-solving ability Human judgment Interpretation of AI outputs Delivering client-ready recommendations An employee who receives mediocre AI outputs but demonstrates exceptional judgment in refining and applying those outputs is recognized appropriately. Why This Supports View B Two employees using the same AI tool may receive different results due to: Task complexity Data quality Project constraints Team support BCG evaluates the human value-add, not just the final output. Amazon and Meta: The Danger of Metrics without Context Both Amazon and Meta have strengthened performance systems focused on measurable accomplishments and rankings. Potential Risk An employee: Supporting a difficult client Maintaining a legacy system Managing operational crises May produce fewer visible accomplishments than someone working on a highly resourced, high-visibility project. A results-only system can unintentionally reward favourable circumstances rather than superior performance. Shopify and Amazon: Rewarding AI Collaboration Forward-thinking organizations increasingly evaluate how employees work with AI, not just what they produce. Examples Shopify encourages evaluation of how effectively employees use AI tools. Amazon's robotics and automation groups increasingly expect employees to demonstrate effective AI usage and automation skills. Why This Matters The focus shifts from raw output to: Adaptability Learning agility Collaboration Problem-solving An employee who creatively uses AI to overcome obstacles deserves recognition, even if final output appears similar to someone operating under easier conditions. The Social Penalty Problem Research from Duke University Fuqua School of Business found that employees who disclose AI usage may be perceived as: Less competent Less diligent More dependent on technology Even when AI improves their performance. Interestingly, this bias largely disappears when evaluators themselves frequently use AI. Implication AI evaluation systems must consider organizational context and evaluator bias. Otherwise, employees working in AI-resistant environments may face unfair disadvantages. Business Impact of Ignoring Context Organizations that evaluate only results often experience: Employees avoiding difficult assignments Increased competition for easy work Lower morale among top performers handling complex tasks Higher attrition among experienced employees Reduced trust in performance management systems By Contrast, Context-Aware Evaluations Encourage Employees To Take ownership of challenging work Support struggling customers Accept difficult projects Focus on organizational success rather than gaming metrics Develop skills in high-complexity environments What Organizations Should Do The evidence is clear: outcome-only AI evaluations create systematic unfairness. Organizations should: 1. Audit Existing Metrics Ensure performance measures capture: Quality Complexity Collaboration Business impact not just output volume. 2. Train Managers on AI Biases Help managers recognize: Anchoring bias Automation bias Overreliance on AI generated ratings 3. Incorporate Contextual Indicators Include: Work complexity Resource availability Staffing conditions Customer difficulty Project constraints 4. Encourage Transparent AI Usage Employees should not be penalized for using AI responsibly to improve productivity. 5. Evaluate Judgment, Not Just Output Measure: Decision quality Problem-solving ability Adaptability Effective use of AI-generated insights Especially in challenging situations. Conclusion AI-based performance evaluations that ignore circumstances are not only unfair they are inaccurate. They reward the lucky, penalize the challenged, and fail to recognize the human judgment that creates real business value. Organizations such as Boston Consulting Group demonstrate that a context-aware approach is both fairer and strategically superior. The goal of AI-powered performance management should not be to evaluate the final number alone. It should be to evaluate the whole person, operating within their real-world circumstances. The strongest performance evaluation system asks not just “What result was achieved?” but “What result was achieved given the complexity, constraints, and challenges involved?” That is why View B is the better approach.
-
I support View A - Make the AI fully transparent. Organizations achieve sustainable high performance when employees trust the systems used to evaluate them. If AI influences performance ratings, promotions, compensation, or development opportunities, employees deserve to understand how those decisions are made. Transparency is not just an ethical requirement it is a business advantage that improves trust, engagement, and performance. A common argument against transparency is that employees may "game the system." However, this concern is often overstated. In reality, if employees can significantly improve their scores without improving outcomes, the problem lies with the design of the evaluation system rather than with transparency itself. A robust AI model should measure outcomes that matter to the business, making it difficult to manipulate scores without delivering genuine value. Why the risk of gaming the system is overstated Modern AI models use multiple metrics, not a single score. An employee cannot simply optimize one factor while ignoring others. For example, reducing call handling time at the expense of customer satisfaction would be detected by the model. AI can identify abnormal patterns. Advanced systems can flag unusual behaviour such as avoiding difficult cases, selectively handling easier customers, or manipulating workflows. Gaming becomes visible when outcomes are measured. If an employee improves response speed but customer complaints increase, the AI can identify the mismatch between activity and results. Transparency drives learning rather than manipulation. Most employees want to succeed and improve. Understanding evaluation criteria helps them focus on behaviours that create value rather than wasting time guessing how they are being judged. Hidden systems create distrust. Employees who do not understand evaluation criteria often perceive the process as biased or unfair, which can reduce motivation and engagement far more than any potential gaming risk. Real-world examples of AI and data-driven performance evaluation Microsoft Microsoft uses AI-powered workplace analytics through tools such as Viva Insights to help organizations understand productivity patterns, collaboration effectiveness, employee engagement, and work habits. Employees and managers receive visibility into the metrics being measured, enabling them to improve performance and well-being rather than operate in uncertainty. IBM IBM has been one of the pioneers in applying AI to talent management and performance evaluation. The company uses AI-driven insights to assess skills, identify development opportunities, recommend career paths, and support performance discussions. Transparency regarding skills and performance expectations helps employees understand how to grow within the organization. Salesforce Salesforce leverages AI and analytics to evaluate customer-facing teams based on multiple indicators such as customer outcomes, productivity, sales effectiveness, and engagement. The emphasis is on providing visibility into performance drivers so employees can improve results and align with organizational objectives. Customer Service Industry Many large contact centers use AI-based quality management platforms that evaluate: Customer satisfaction scores Resolution quality First-contact resolution Repeat contact rates Compliance adherence Customer sentiment Escalation trends Agents who understand these metrics are better equipped to improve customer experiences. Organizations consistently find that clarity around expectations leads to better coaching, higher employee engagement, and stronger customer outcomes. Transparency creates better business outcomes When employees understand how impactful evaluation performance works: They trust the system more. They can identify specific areas for improvement. Managers can coach more effectively. Employee satisfaction increases. Organizational goals become clearer. Google's success with transparent goal-setting through Objectives and Key Results (OKRs) demonstrates that visibility into performance expectations drives accountability and alignment rather than manipulation. Employees perform better when they know what success looks like. The strongest organizations do not hide evaluation criteria they build systems that are robust enough to remain effective even when employees understand them. If transparency exposes weaknesses that allow gaming, the solution is to improve the AI model, not to keep employees in the dark. Ultimately, AI should not be a black box that judges employees. Full transparency promotes trust, fairness, engagement, and continuous improvement. These benefits directly contribute to higher employee satisfaction, better customer experiences, and stronger organizational performance making transparency the superior choice for both people and business results.
-
I support View B — Do not experiment on live operations. Bex argues that allowing AI to test a new picking and routing method on 20% of live orders is a reasonable way to drive innovation. I disagree because customers and frontline employees should not bear the cost of validating an AI's uncertainty. The flaw in Bex's argument is the assumption that a 20% live test is a limited and contained risk. In a warehouse environment, that is rarely true. Fulfillment centers operate as synchronized ecosystems where picking, packing, inventory management, labor allocation, and shipping are tightly interconnected. If an AI's unproven routing method creates a bottleneck in one area, the impact does not remain confined to the 20% test group. Congested picking aisles can delay packing stations, disrupt shipping schedules, and reduce productivity across the entire facility. Physical assets and human labor cannot be neatly segmented like software code in a sandbox. A failure in one part of the operation can quickly cascade through the whole system. The human cost is equally important. Frontline warehouse teams work against strict productivity, quality, and safety targets. Introducing temporary inconsistencies through an unproven AI process can create confusion, increase cognitive workload, reduce morale, and potentially introduce safety risks. Employees should not be forced to absorb the operational consequences of an experiment that has not yet been proven to work. There is also a significant customer and brand risk. In modern e-commerce, consistency is part of the product. Customers expect reliable fulfillment and on-time delivery. A customer whose order is delayed because they were unknowingly included in an AI experiment is unlikely to appreciate the organization's optimization goals. They are more likely to lose trust in the service and take their business elsewhere. Customer trust, once lost, is far more difficult and expensive to rebuild than operational efficiency is to achieve. History provides several examples of the risks associated with deploying unproven systems into live operations. In 2000, Nike implemented a new demand planning and forecasting system intended to optimize inventory management. Instead, forecasting errors created shortages of popular products and excess inventory of slower-moving items, resulting in significant operational and financial consequences. The expected efficiency gains failed to materialize because the system behaved differently under real-world conditions than anticipated. A second example is Target Canada's expansion in 2013. The company launched with inventory and supply-chain processes that were not fully mature at scale. The result was widespread stock inaccuracies, empty shelves despite available inventory, poor customer experience, and major operational disruption. Within two years, Target exited Canada, closing all stores and eliminating approximately 17,600 jobs. The failure demonstrated how weaknesses in operational systems can rapidly undermine customer trust and business performance. An even more dramatic example is Knight Capital Group's software deployment in 2012. A defect in newly deployed automated trading software triggered millions of unintended trades and generated approximately $440 million in losses within 45 minutes, pushing the company to the brink of collapse. While the industry was different, the lesson is universal: when automated systems are tested in live environments, unexpected consequences can escalate far beyond what was originally anticipated. Organizations should absolutely experiment and innovate. However, experimentation should occur in simulations, digital twins, controlled pilot environments, and staged validation processes before affecting real customers and employees. Innovation is most effective when organizations learn without exposing stakeholders to unnecessary risk. For these reasons, I support View B. The potential benefits of a 15% efficiency improvement do not justify using live customer orders and frontline employees as a testing ground for an uncertain AI system. Responsible innovation requires proving that a solution works before deploying it into real-world operations.