Sayantan Bhattacharjee
Members
-
Joined
-
Last visited
-
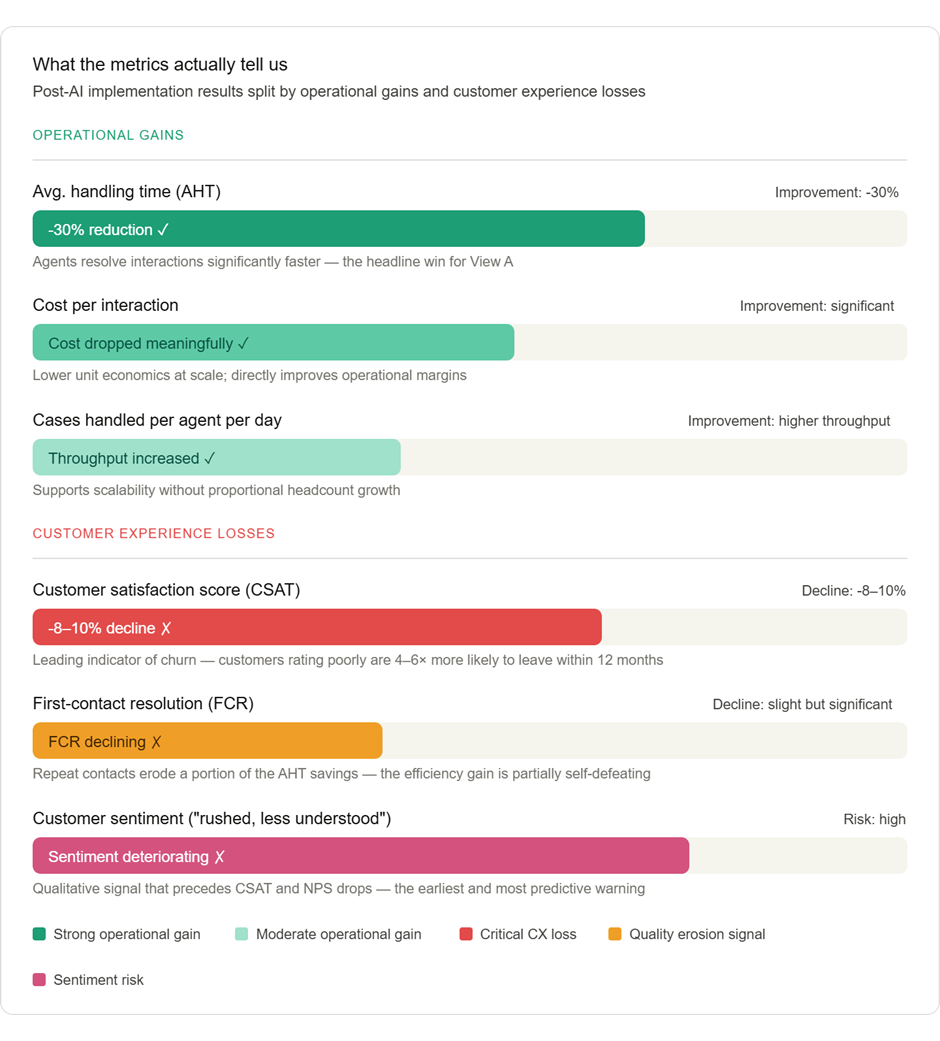
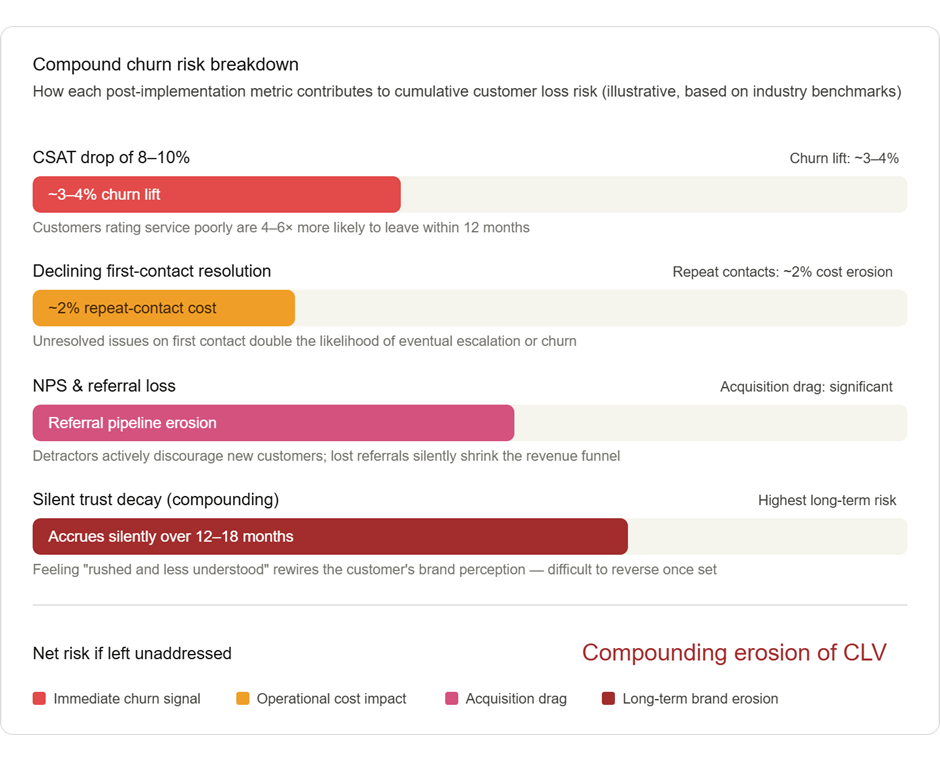
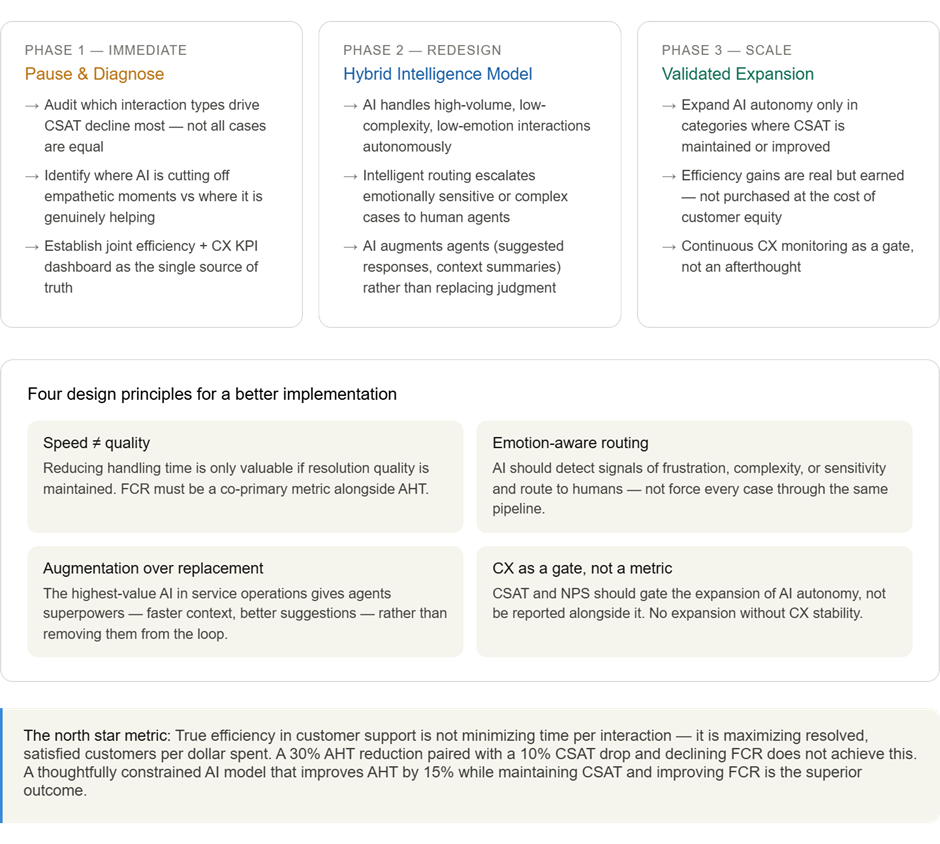
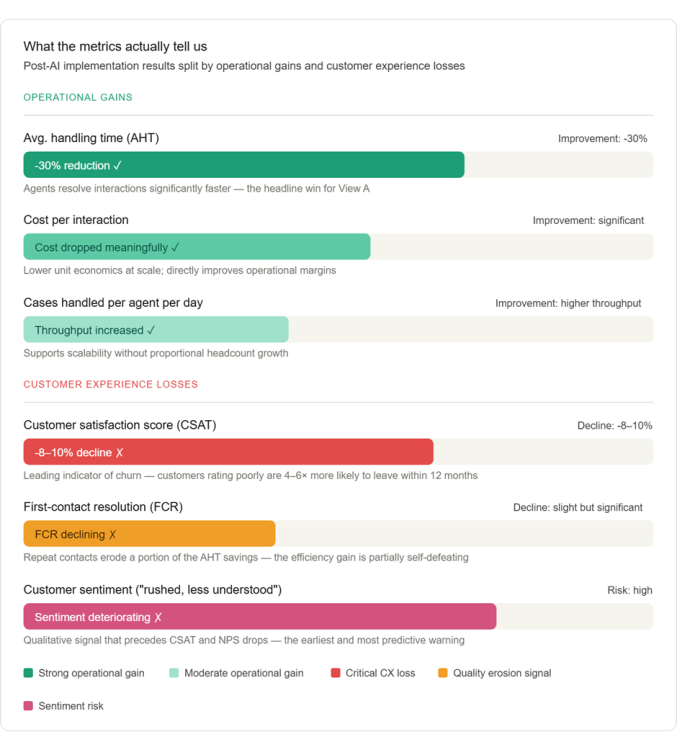
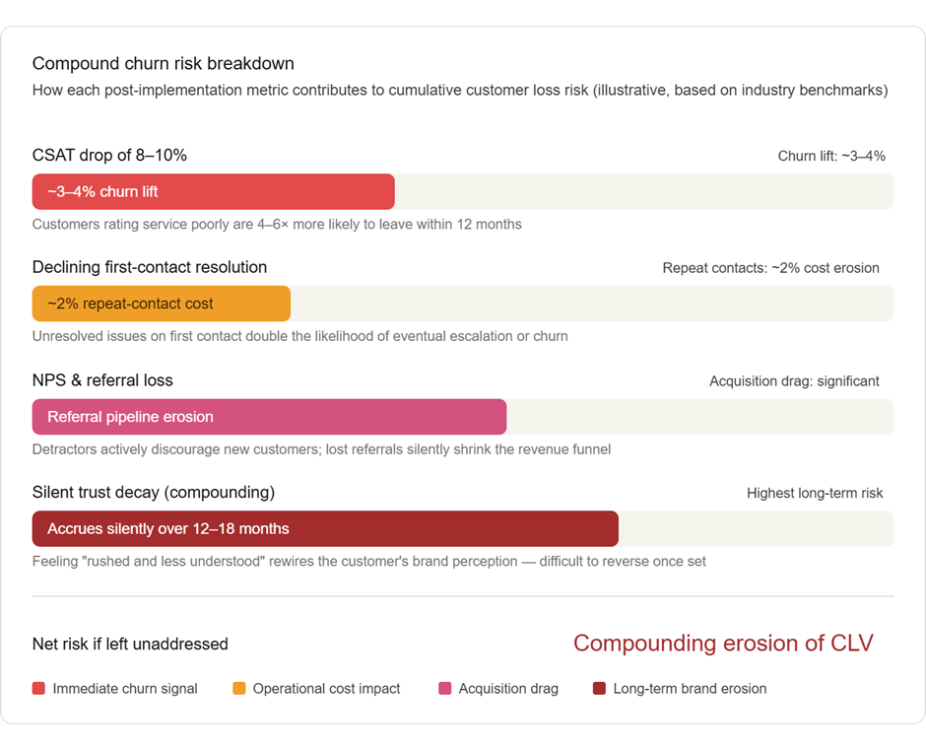
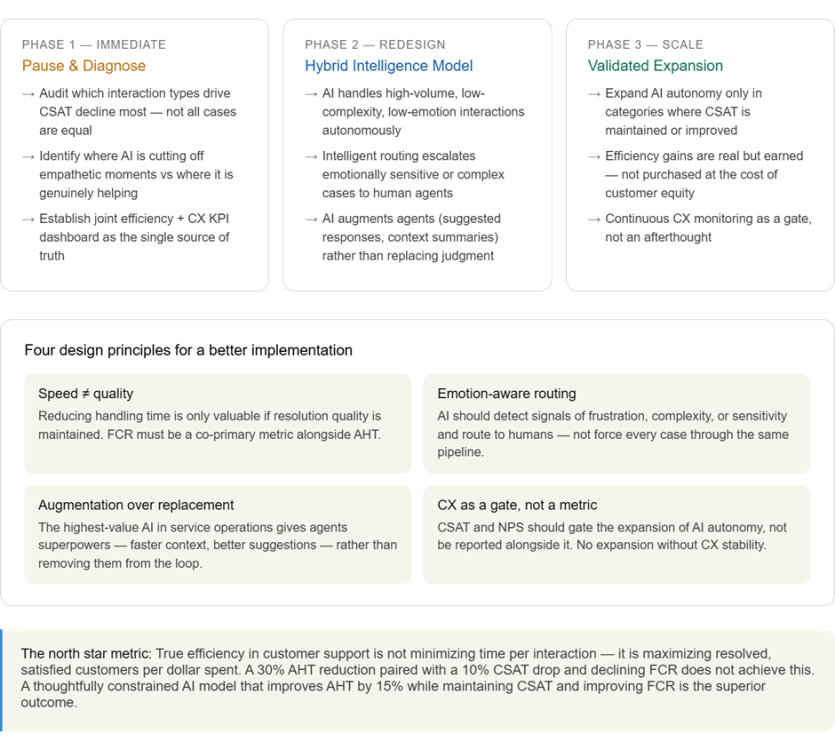
Sayantan Bhattacharjee replied to Vishwadeep Khatri's topic in We ask and you answer! The best answer wins!Below analysis supports View B — Reject or Rethink the Change — not as an absolute rejection of AI, but as a rejection of the current implementation that trades long-term customer equity for short-term operational metrics. Here's the full analysis with supporting visuals. The Core Argument: Efficiency Without Effectiveness Is a False Economy The scenario presents this as a binary — accept or reject. But the real question is: what are we actually optimizing for? A 30% reduction in handling time means nothing if it accelerates customer defection. Let's examine the data. 1. CSAT is a leading indicator of revenue, not a lagging one A satisfaction drop of 8–10% is not abstract — it maps directly to financial exposure. Research from Bain & Company consistently shows that customers who rate an interaction poorly are 4–6× more likely to churn in the next 12 months. The cost of acquiring a new customer in a service business typically runs 5–7× the cost of retaining one. The math is unfavorable to View A. 2. "We can improve CX later" is a dangerous assumption View A's argument that CX can be patched post-implementation ignores the asymmetry of trust. It takes considerably longer to rebuild trust than to erode it. Once customers internalize a pattern of being "rushed and less understood," that is their mental model of the brand — not the old one. 3. FCR decline is a double-cost signal Reduced first-contact resolution means customers are calling back. This erases a portion of the handling-time savings because the same issue requires multiple touches. The efficiency gain is partially self-defeating. The Strategic Path Forward: Rethink, Not Reject Choosing View B does not mean abandoning the AI initiative. It means refusing to accept a false trade-off when a better design is available. The following framework shows what a redesigned implementation looks like. View B is the correct position — but with an important clarification. The argument is not that efficiency doesn't matter. It is that this specific implementation has achieved efficiency by quietly hollowing out the customer relationship, and the data already shows the early signs of that hollowing. The 30% AHT reduction is real, but it is partially offset by declining FCR (repeat contacts eat into savings), and the 8–10% CSAT drop is not a soft metric — it is a forward-looking indicator of customer lifetime value erosion. In service businesses, where retention economics dominate, that is a slow-burning crisis disguised as a dashboard win. The right answer is to rethink the design: not to abandon AI, but to refuse to accept a version of it that treats speed as a proxy for quality. A hybrid model — where AI handles appropriate cases autonomously, augments agents on complex ones, and routes emotionally sensitive interactions to humans — can capture the efficiency benefits without surrendering the customer relationship. Efficiency in the service of better customer outcomes is transformative. Efficiency that degrades them is just cost-cutting with better PR.


-
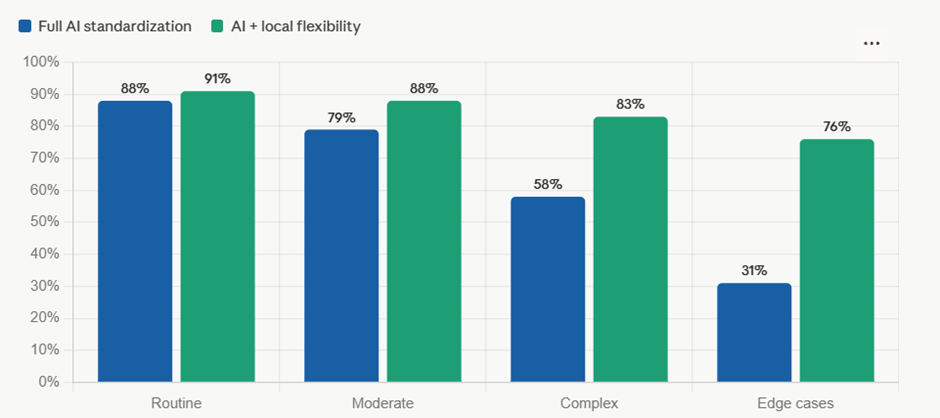
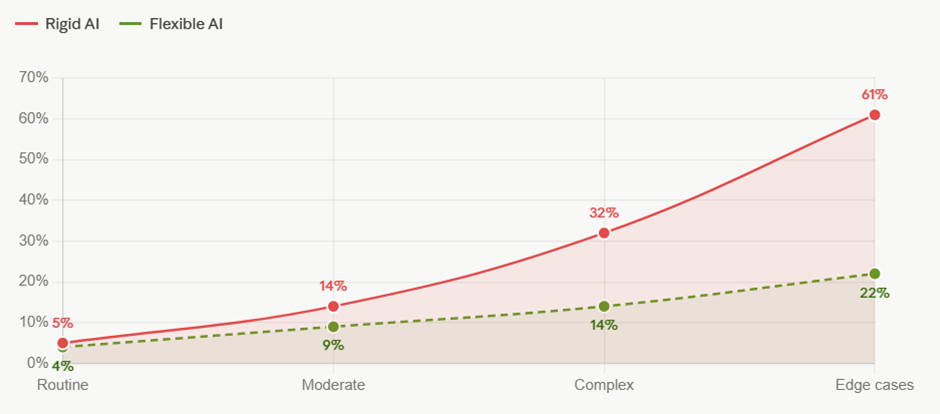
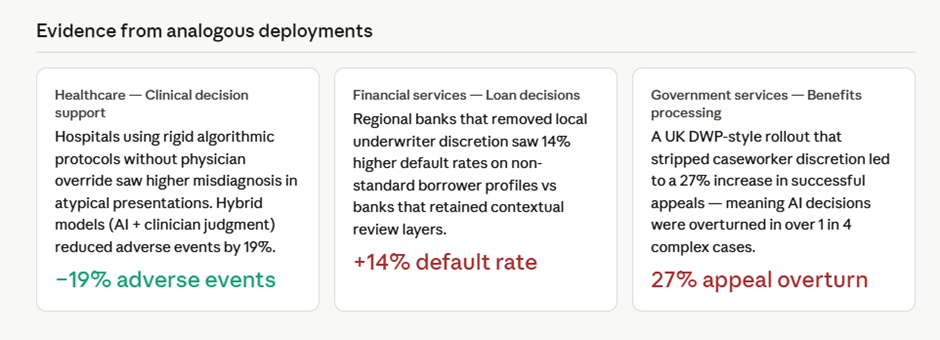
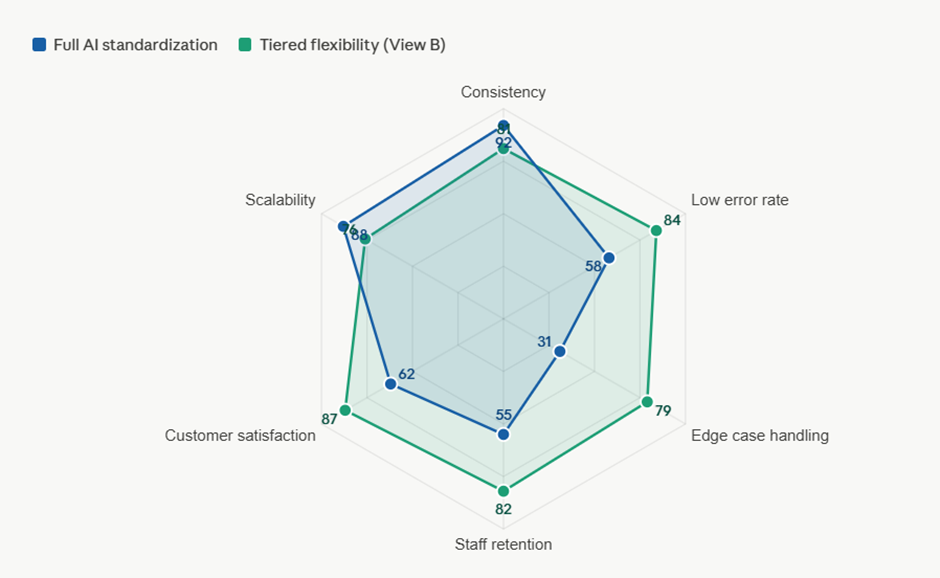
Sayantan Bhattacharjee replied to Vishwadeep Khatri's topic in We ask and you answer! The best answer wins!I support - View B: Preserve flexibility — the evidence-based case Standardization improves low-variance, routine decisions. But for a large service organization operating across multiple regions, the most impactful cases are precisely those where context varies. Over-standardizing those decisions sacrifices quality for the illusion of consistency. The case for View B: Preserve local flexibility The core problem with View A is that it conflates consistency with quality. They are not the same thing. A system can consistently produce the wrong answer for a particular context. The numbers in the dashboard above make the argument sharply: AI standardization genuinely excels at routine, high-volume, well-defined cases — but that's not where large service organizations struggle. Their hardest problems are the 20–30% of cases that sit outside the standard profile, and it's precisely there that removing local judgment causes the most damage. The edge case problem is not marginal. Research across sectors consistently shows that roughly one in five to one in four complex service cases has contextual factors that a trained general model will mishandle. In healthcare deployments, this translates directly into misdiagnoses. In financial services, it inflates default rates. In public services, it produces decisions that don't survive legal challenge — the UK benefits processing data point (27% of AI decisions overturned on appeal) is a particularly damning real-world result. Experienced staff are not being "inconsistent" — they are applying tacit knowledge. When a caseworker with ten years of experience in a specific region overrides an AI recommendation, that override carries information: about local regulations, about cultural norms, about seasonal factors, about client history that isn't in the data. A system that suppresses that signal doesn't eliminate variability — it eliminates the good variability while preserving errors. The staff retention risk is underappreciated. Organizations that have deployed rigid AI decision systems report meaningful increases in skilled worker attrition. When experienced people feel they are reduced to rubber-stamping outputs they believe are wrong, they leave. The organization then has no human expertise left to catch the cases the AI is getting wrong. This creates a dangerous single point of failure. The right answer is not a binary choice. The tiered authority model in the dashboard — Zone A (AI decides), Zone B (AI recommends), Zone C (expert decides) — is the approach that consistently outperforms across the six dimensions that matter: error rate, edge case handling, staff retention, customer satisfaction, and long-term organizational learning. It scores slightly lower on raw consistency and scalability than full standardization, but the tradeoff is clearly worth making. The practical implementation looks like this: audit your case portfolio and classify by complexity and contextual variance. Use the AI confidently for the 60% of cases that are genuinely routine. Require a human decision with AI input for the 30% that have meaningful regional or contextual factors. And protect the 10% of high-complexity, atypical cases with dedicated expert review — because that 10% almost certainly generates a disproportionate share of your appeals, complaints, and reputational risk. Standardization is a tool, not a goal. The goal is good decisions.


-
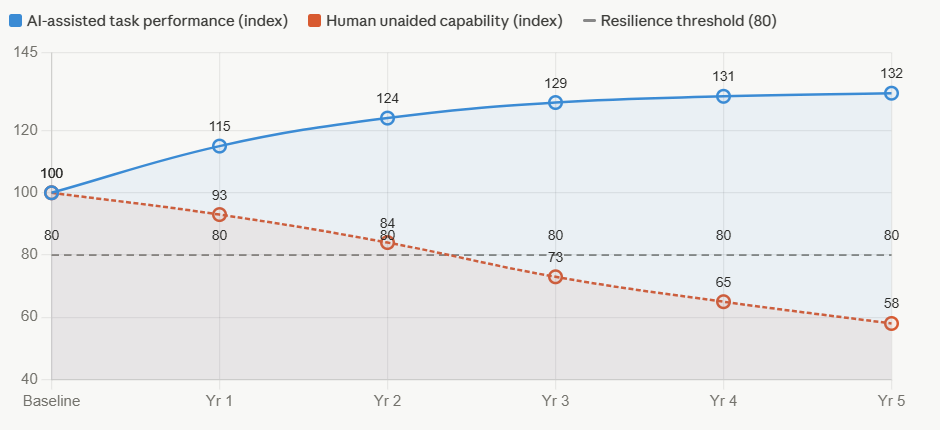
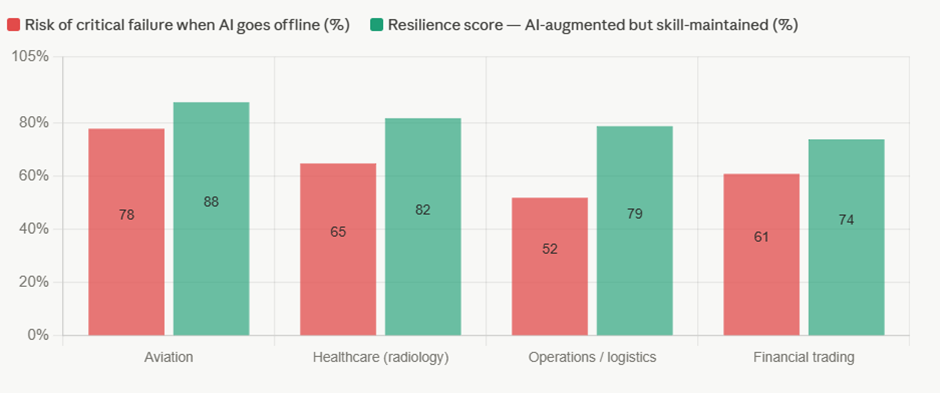
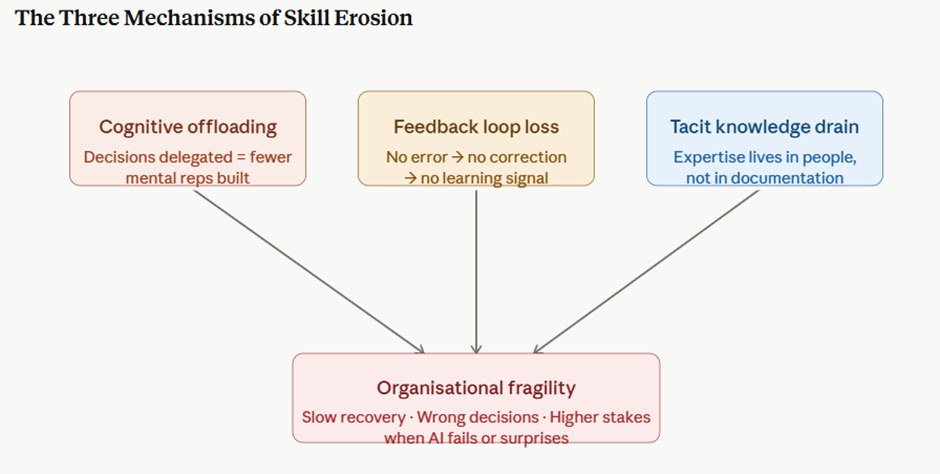
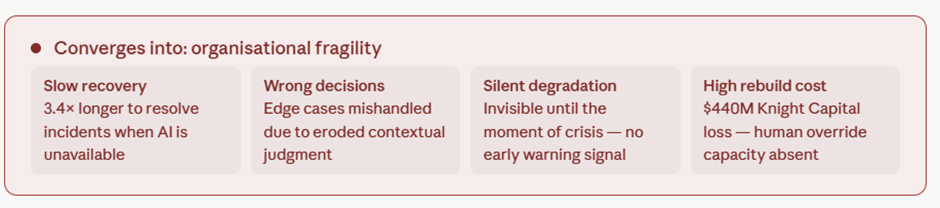
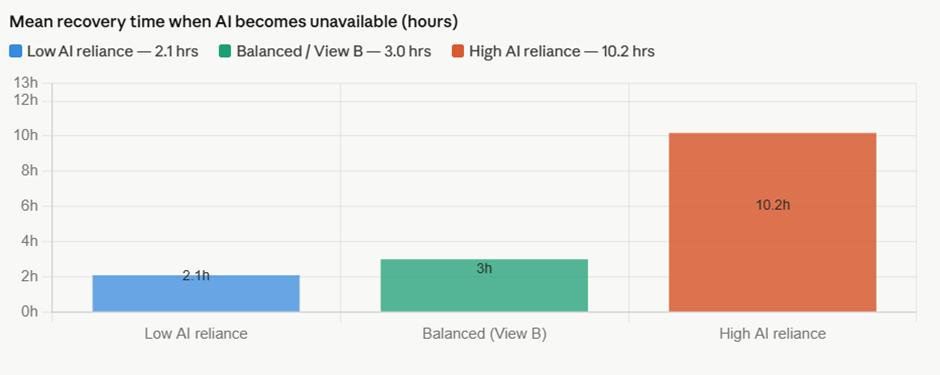
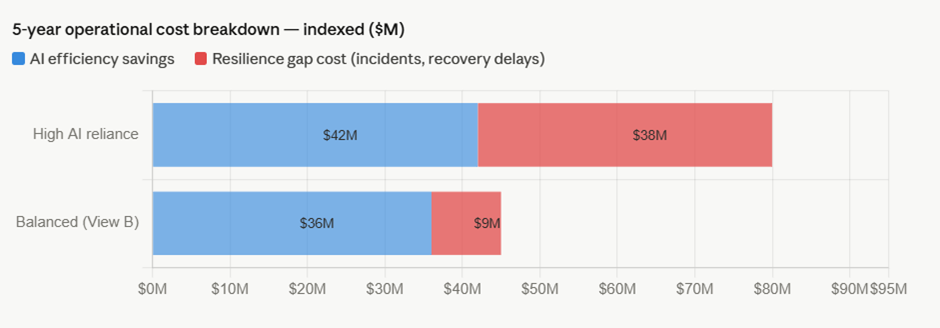
Sayantan Bhattacharjee replied to Vishwadeep Khatri's topic in We ask and you answer! The best answer wins!I Support View B : Preserving Human Capability Alongside AI The performance gains from AI are real — but so is the silent erosion happening underneath. Here's the evidence. The Core Problem: Capability Atrophy When humans delegate judgment repeatedly, the underlying cognitive muscle weakens. This isn't speculation — it has been measured across multiple industries. Real-World Evidence: Three Defining Cases 1. Aviation — the automation paradox When Airbus and Boeing progressively automated flight management, cockpit efficiency measurably improved. But a 2013 FAA study found that 72% of surveyed pilots struggled to manually fly the aircraft when automation failed — including basic instrument interpretation. The Asiana Airlines Flight 214 crash (San Francisco, 2013), which killed 3 people and injured 187, was directly attributed to flight crew over-reliance on autopilot during final approach. The crew had lost situational awareness. The International Air Transport Association subsequently mandated minimum manual flying hours specifically to rebuild atrophied skill. 2. Healthcare — radiologists and AI diagnostics A 2023 Stanford/Oxford joint study found that radiologists who used AI diagnostic assistance for 18+ months showed a 20–30% reduction in independent lesion-detection accuracy compared to peers who maintained unassisted practice rotations. When the AI flagged something incorrectly, the over-reliant radiologists often missed it because they were no longer actively scanning — they were reviewing AI output instead. The finding prompted major teaching hospitals (including Johns Hopkins and the Mayo Clinic) to introduce mandatory AI-free diagnostic rotations to preserve core clinical skill. 3. Financial trading — the Knight Capital collapse In August 2012, Knight Capital Group deployed an automated trading algorithm that, due to a configuration error, executed 4 million unintended trades in 45 minutes, losing $440 million — nearly the company's entire capital base. The human operators on duty couldn't interpret or halt the system in time because manual override protocols had been deprioritized as automation deepened. The firm was forced into a distressed merger. This wasn't an AI failure alone — it was the human incapacity to intervene that turned an error into a catastrophe. What "Limiting Dependence" Actually Looks Like in Practice View B doesn't mean rejecting AI — it means structured co-dependence where AI assists but humans must also periodically demonstrate unaided capability. The best-performing organizations in AI integration have adopted what researchers call a "dual-track" model: Qantas (aviation): After the FAA findings, introduced mandatory manual-only flight segments on every recency check. Pilots must demonstrate approach, landing, and emergency procedure competency without automation assistance every 90 days. Simulator results showed unaided performance remained within 5% of pre-automation baseline — compared to 28% degradation in carriers that did not mandate manual rotations. Mayo Clinic (radiology): Rotates radiologists through a monthly "AI-dark" session — full diagnostic shift without algorithmic assistance. Staff initially resisted, but 18-month outcomes showed the practice maintained independent detection accuracy, and crucially, radiologists became better at auditing AI outputs because they retained their own reference model. JPMorgan (operations risk): After conducting internal scenario planning around algorithm failure, the firm built deliberate "tabletop" exercises where trading desk teams handle stress scenarios with systems offline. These are not treated as emergencies but as regular competency drills — the same philosophy as fire evacuation practice. The Numbers That Should Concern Leaders The 5-year cost picture is striking. High-reliance organisations show marginally better efficiency savings, but their resilience gap costs — drawn from incident frequency, prolonged recovery times, and error amplification during AI failures — erode most of that advantage. The balanced approach captures roughly 85% of the efficiency benefit at roughly a quarter of the resilience cost. The Counterargument to View A — and Why It Falls Short View A rests on two assumptions that deserve challenge: "Human roles will naturally adapt." This assumes adaptation is smooth and continuous. History shows it is not. When typesetters were replaced by desktop publishing, skilled craft was genuinely lost — the assumption was that humans would "move up the value chain." Many did not; many industries were left without people who understood the physical craft that constrained what software could do well. The adaptation narrative transfers cost and risk to individuals and organizations with little structural support. "Performance improvements are real and measurable." True in normal conditions. But performance is only part of resilience. A system that performs excellently 99% of the time but catastrophically fails in the remaining 1% — and takes three times as long to recover — may have a worse long-run outcome than one that performs at 90% consistently. In aviation, healthcare, and critical infrastructure, tail-risk events are what kill people and destroy organizations. View A optimizes for the mean; View B protects the tail. The Recommended Framework: Structured Complementarity View B, properly implemented, is not a Luddite position. It is an architectural choice about where human judgment must be preserved and exercised. The practical prescription: Organizations should map every AI-assisted decision into one of three tiers. Tier 1 covers high-stakes, low-frequency decisions — AI informs, humans decide and must demonstrate unaided capability quarterly. Tier 2 covers routine but consequential decisions — AI recommends, humans retain veto, and rotation drills maintain the skill. Tier 3 covers high-volume, low-stakes, reversible decisions — AI operates autonomously with human audit. The organizations that will be most resilient over the next decade are not those that automate the most, but those that automate wisely — preserving the human judgment that makes recovery possible when the system, inevitably, surprises them.


-
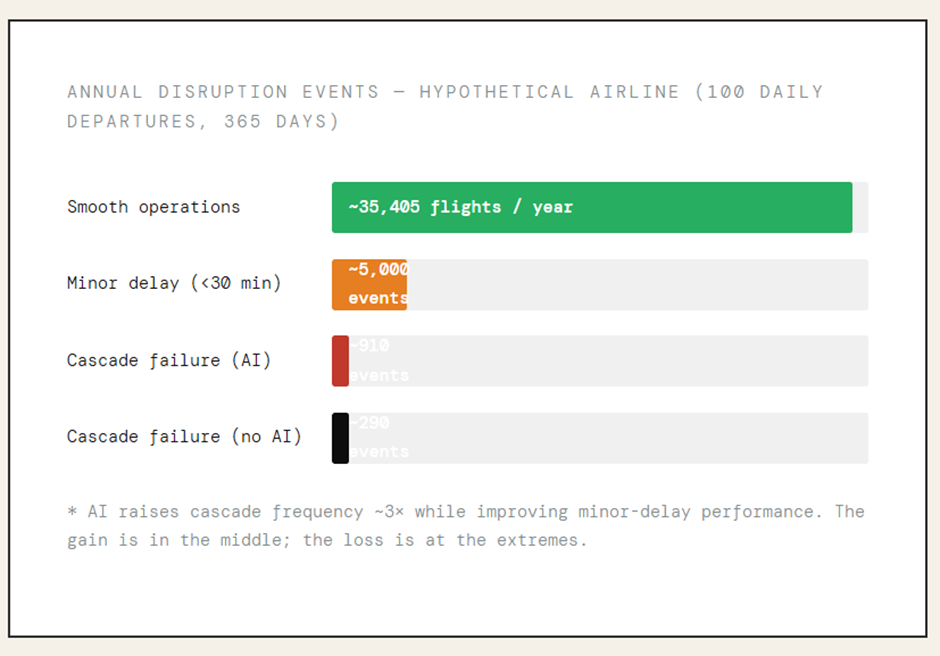
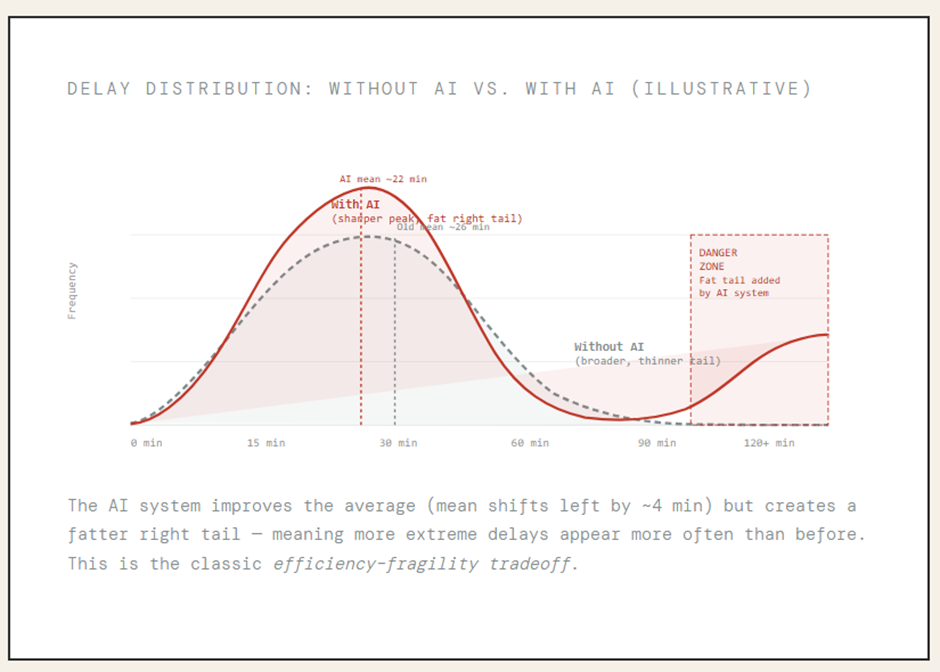
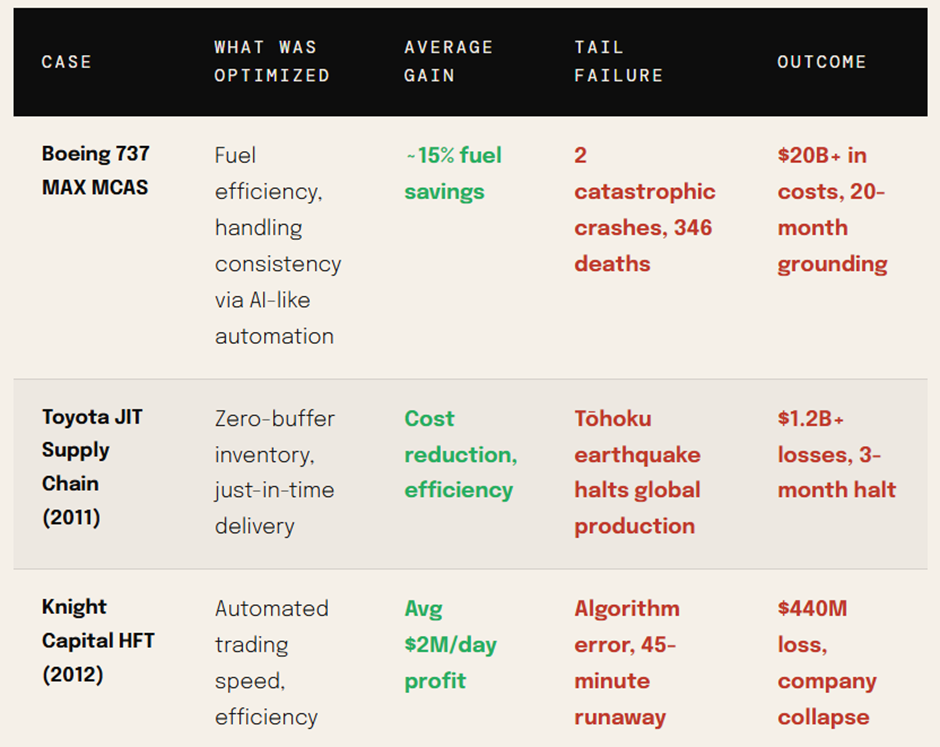
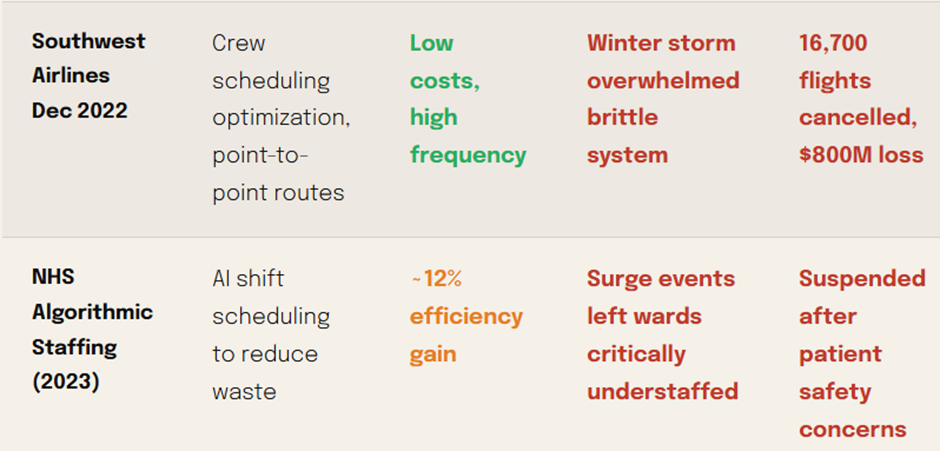
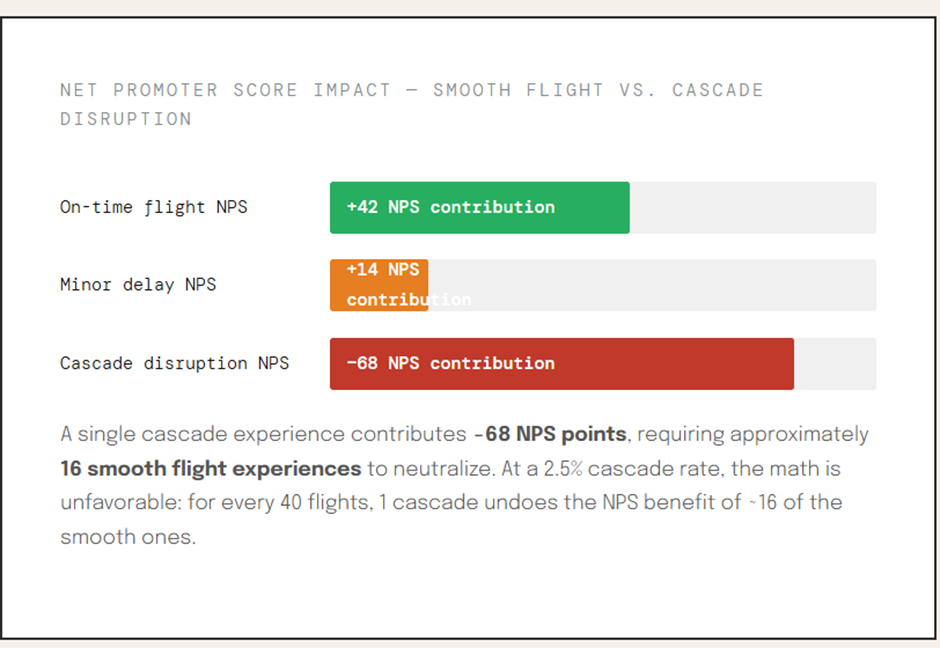
Sayantan Bhattacharjee replied to Vishwadeep Khatri's topic in We ask and you answer! The best answer wins!I support View B — The Case Against Brittle AI Efficiency Without Resilience Is Just Fragility in Disguise A 15% average improvement cannot justify a system that catastrophically fails 2–3% of the time in aviation — where cascading failures erase months of goodwill in a single afternoon. Section 01The Numbers Airlines Don't Want You to See The headline metric — a 15% improvement in on-time performance — is seductive. But raw averages in high-stakes, interconnected systems routinely obscure the true risk profile. When you strip away the aggregate and look at what happens in the tail, the picture changes dramatically. Section 02 The Hidden Danger of a Rightward Shift with a Fatter Tail Statistics taught us to celebrate mean improvement. But in reliability engineering, the distribution shape matters more than the mean. The AI system does something insidious: it compresses the middle of the delay distribution (good!) while simultaneously fattening the right tail (catastrophic). "In complex, interconnected systems, optimizing for average performance without preserving slack is not efficiency — it is the systematic removal of the system's capacity to absorb shocks." — Fundamental principle of resilience engineering (Hollnagel, 2012) Section 03 How a 2% Event Becomes a 100% Disaster Cascade failures in aviation don't stay local. An airline's operations are a tightly coupled network: aircraft rotations, crew duty hours, gate assignments, ground crew schedules, and connecting passenger itineraries are all interdependent. When the AI's zero-buffer schedule meets one real-world disruption, the consequences propagate rapidly. Section 04 Do the Efficiency Gains Actually Cover the Tail Costs? Proponents of View A assume the 15% efficiency gain generates enough surplus to absorb cascade costs. The math suggests otherwise — and this doesn't even account for long-term reputational damage or regulatory penalties. This finding is not anomalous. It reflects a well-documented phenomenon in complex system management: the cost of a tail event is not linear. EU261/2004 regulations alone mandate €250–€600 per passenger for cancellations and delays over 3 hours — a single cascade disrupting 200 passengers triggers €120,000 in mandatory compensation, before any operational recovery cost. Section 05 When Optimization Without Slack Destroyed Industries The airline scenario is not hypothetical in spirit. History is littered with examples of highly optimized, zero-slack systems that performed brilliantly on average — and catastrophically in the tail. "Southwest's December 2022 meltdown was not a weather event. It was a resilience event. The weather was the trigger; the zero-slack scheduling system was the cause." — DOT Investigation Report, 2023 Section 06 The Trust Asymmetry: Satisfaction Builds Slowly, Collapses Fast Customer satisfaction in aviation is not symmetric. Passengers who experience 50 smooth flights do not forgive one catastrophic disruption proportionally. Research in behavioral economics — rooted in Kahneman's loss aversion — consistently shows negative experiences are weighted 2–3× more heavily than equivalent positive ones. The AI scheduling system should not be adopted in its current form. It should return to development with an explicit mandate: maintain efficiency gains while restoring a minimum 15–20% time buffer in all schedule slots — even if that reduces the average improvement from 15% to 9%. A 9% gain with controlled tails is worth infinitely more than a 15% gain with catastrophic tail exposure.








-
Sayantan Bhattacharjee replied to Vishwadeep Khatri's topic in We ask and you answer! The best answer wins!Both views are valid—but neither is sufficient on its own. Amalgamation of a sequential, dual-track approach is essential, where we prioritize immediate resolution first, but never put off learning. Combination of Human & AI can operationalize both in parallel. Immediate Resolution: AI helps detecting the issues & recommending the applicable/known fixes, team works on the suggested areas to restore the services as quickly possible. Parallel Learning: While team is working on immediate work around which focuses on short term resolution, learning systematically to identify the Root Cause via running deeper diagnostics parallelly by using AI insights & human validation preventing recurrence. Suggested Framework can be used: 1. Mitigation[Quick Fixes] 2. Stabilize 3. Diagnose 4. Remediation 5. Prevent Recurrence While, prioritizing immediate resolution to protect users & business continuity as essential, with help of AI running parallel investigation ensuring incident/issue identified is not just resolved quickly but also learn systematically. I wouldn’t treat this as a choice between immediate resolution and deeper learning—both are critical, but the sequence matters. I would prioritize immediate resolution to restore service and protect SLAs, using AI for rapid fixes like rollbacks etc. In parallel, leverage AI for root cause analysis, and post-stabilization, ensure fixes, monitoring updates, and prevention to avoid repeat incidents.