

Sohan Subhash Mirajkar
Lean Six Sigma Green Belt
-
Joined
-
Last visited
-
Sohan Subhash Mirajkar replied to Vishwadeep Khatri's topic in We ask and you answer! The best answer wins!How the Swiss Cheese Model Helps The Swiss Cheese Model helps me spot where things can go wrong and understand how multiple safeguards can still fail if their weaknesses line up. Imagine each layer of protection in a process as a slice of Swiss cheese. The slices (defenses) try to block mistakes or failures, but each has some holes (weaknesses). If the holes in several layers line up, a problem can slip through all defenses and cause a failure — like a system crash, data leak, or customer impact. In My Work: Slices of Cheese (Defense Layers) These are the safeguards I put in place: Code reviews – to catch errors early. Testing (unit, system, integration) – to find bugs. Monitoring tools – to detect issues in real-time. User feedback loops – to improve the system over time. Documentation and SOPs – to guide teams. Holes (Weaknesses) These are the risks or gaps in those defenses: Rushed code reviews – can miss subtle bugs. Tests may not cover all edge cases – letting bugs through. Monitoring can be misconfigured – failing to alert us. Users might not report issues clearly – delaying fixes. Outdated documentation – can lead to confusion.
-
Sohan Subhash Mirajkar replied to Vishwadeep Khatri's topic in We ask and you answer! The best answer wins!In one of my process improvement IT project, we had used FMEA, Fishbone diagram and Pareto analysis to understand which are the major problems/issues faced by 7 IT work streams by interviewing key stakeholders and understanding the most important 20% issues which led to 80% failures. This was a very time consuming activity to gather and analyse the root causes of problem and discuss the points in meeting to find solutions as part of process improvement. Now, in AI world for reimagining the solution, we can automate and use conversational AI using Agentic chatbots to ask relevant questions and answer the questions using effective AI models which can save time and provide better outcomes to our stakeholders.
-
Sohan Subhash Mirajkar replied to Vishwadeep Khatri's topic in We ask and you answer! The best answer wins!As Gartner describes dark data as the information assets companies collect, process and store during regular business tasks, but generally forget or refrain to use for other purposes (Egs. Analytics, Business relationships and Direct Monetising). Dark data often comprises most organisations’ entire universe of information assets. Hence companies often keep the dark data for compliance purposes only. Storing and securing dark data mostly incurs more expense and sometimes greater risk than value. Dark Data types mainly include: Log files (servers, systems, architecture, etc.) Previous employee data Financial statements Geolocation data Raw survey data Surveillance video footage Customer call records Email correspondences Notes, presentations, or old documents Companies like IBM, BMC, Deloitte, Globallogic have used dark data for successfully tapping the benefits of dark data for analytics.
-
Sohan Subhash Mirajkar replied to Vishwadeep Khatri's topic in We ask and you answer! The best answer wins!Berkson first explained about this paradox in 1946. His original research paper demonstrated that two diseases, which has no real life relationship, can be what he called ‘spuriously associated‘ in hospital-based case control studies. This idea was not widely accepted until 1979, but when David Sackett of McMaster University provided a strong evidence that Berkson’s paradox does exist, it got acceptance. Berkson’s paradox which is also called as Berkson’s fallacy or Berkson’s bias is the counter-intuitive idea that events which seem to be correlated actually are not correlated. Examples of Berkson’s paradox: 1. For example, take 2 events which are completely independent like lung cancer and diabetes. If a study selects for both the presence of lung cancer and diabetes, if there is presence of cancer then it is more likely to have diabetes as well. Although intuitively, there is no sense in this correlation, but the data seems to back this counter-intuitive notion up, showing that there is, in fact, a connection. 2. For example, someone may observe from experience that fast food restaurants in their area which serve good burgers also tend to serve bad french fries and vice versa; but because they would likely not eat anywhere where both burgers and french fries were bad, they might fail to allow for the large number of restaurants in this category which weaken or even contradict the correlation. The most effective way to prevent Berkson’s bias in research studies is to collect a simple random sample from a population. That means that every member of the given population of interest has an equal chance of being included in the sample.
-
Sohan Subhash Mirajkar replied to Vishwadeep Khatri's topic in We ask and you answer! The best answer wins!In data visualisation tools , breaking down the data is grouped into measures and dimensions. Measures Measures are of type numerical data which are calculated/aggregated. Examples include the sum of revenue, average cost, or profit-per-capita, or non-numeric data that can be counted. Measures essentially consist of aggregation type associated with them. Example: SAP BusinessObjects Lumira application, sets this type to sum.If the chart includes for example revenue by country & the sum is associated with revenue, then SAP BusinessObjects Lumira allows you to customise the prefix/suffix to indicate data, such as CAD, EUR, INR or USD for currency. Dimensions Dimensions consist of categorical data, for example year, product, country, & salary range. Categorical data is defined as nominal data, and is used for denoting discrete values. For Example, the dimension called product type may include the values such as Men’s Clothing & Women’s Clothing. In use of ordinal data, the dimension have a fixed order. For example, If the dimension denotes the outcome of a survey result, the resulting value can appear to be Agree , Neutral or Disagree showing up in that implicit order. In case of interval data, every value in the dimension denotes a range of values. Example includes dimension salary can be divided into the following values of salary ranges: <$30K $30-$60K, $60-$90K, and >$90K. How to tell the difference When we do the aggregation of the object, it must consider the column to be a measure. Example: Sum of Sales can be considered as a measure and Region as a dimension field to split apart the Sum of Sales into the Sum of Sales per Region. We can create measures from categories by counting their elements. For example, Total Number of Cities visited by the Customers is a measure.
-
Sohan Subhash Mirajkar replied to Vishwadeep Khatri's topic in We ask and you answer! The best answer wins!Dr Goldratt had introduced the term "Mafia Offer" for the first time in his book called "It Not Luck" and then it was defined later as offer that one cannot refuse.A Mafia Offer is actually any offer we make to the market/prospects or customers in order to make them delighted about your products or services and something that your competition cannot match very quickly. Economics suggests us that market value works on function of supply and demand. For example demand for your product suddenly rises. We can thus sell at a higher price and still make more sales because our item is worth far more and better to the customer. The customer has to now buy from you. Mafia offer is different than USP because USP take something what we already do and aimed at one or few of the customers problems or gaps in current market offerings. Many companies offer solutions that solve their consumers different problems or symptoms. But with Mafia Offer we address customer’s core problem as it relates to doing business with within our industry. It offers to address the core problem which deliver value which the customers cannot refuse and competitors cannot make that improvements because they don’t know or willing to do those improvements. Simply it’s the way to create monopoly or operational advantage in the market. Famous Mafia Offer examples are: Hyundai Mafia Offer states that “We will buy back your new car if you get laid off in the next two years (made during a recession year)” Domino's Pizza has mafia offer that “We deliver in 30 minutes less – or you eat FREE” Xerox offers mafia offer mentioning “We offer copies when and where you need them, at an fixed rate per page (instead of selling expensive machines and inconvenient servicing)”
-
Sohan Subhash Mirajkar replied to Vishwadeep Khatri's topic in We ask and you answer! The best answer wins!Fleiss’ Kappa is another way to measure match of opinions between three or more raters. It is advisable to have Likert scale data or other closed-ended, ordinal scale or nominal scale (categorical) data. Similar to most correlation coefficients, Fleiss Kappa ranges from 0 to 1, where: 0 is no agreement/mismatch (or agreement that you would expect to find by chance), 1 is perfect agreement/perfect match It is possible to have values < 1, meaning the values are less than expected by chance. For practical purposes, these values can be counted as 0, or no agreement. In general, a coefficient over .75 (75%) is considered as a “good” match, although what exactly is an “acceptable” level of agreement depends largely on particular field. In other words, check with experts or SME before concluding that a Fleiss’ kappa over .75 is acceptable. In few cases, Fleiss’ Kappa can also return low values even when agreement is actually high. This is why it is less popular. Difference between Fleiss Kappa & Krippendorff's alpha and reason to prefer to use krippendorff's alpha Krippendorff’s alpha (also called Krippendorff’s Coefficient) is an alternative to Fleiss’ Kappa for determining inter-rater reliability. Krippendorff’s alpha has below characteristics: It ignores missing data entirely. It has the ability to handle various size of samples/categories/numbers of raters. It applies to any measurement level (i.e. (nominal, ordinal, interval, ratio). It is commonly used in content analysis to quantify the extent of agreement between raters, & it differs from most other measures of inter-rater reliability because it calculates disagreement/mismatch (as opposed to agreement/match). This is one of the main reason why the statistic is more reliable, but some researchers report that in practice, the results from both alpha and kappa are similar (as explained by Dooley). Computation of Krippendorff’s Alpha The basic formula for calculating alpha is a ratio of observed disagreement & expected disagreement. The ratio is very simple, because the method is actually computationally complex, involving resampling methods like the bootstrap. This is a major disadvantage (explained by Osborne). We can get an idea of the computations involved from the following formula. These values range from 0 to 1, where 0 is perfect disagreement/mismatch and 1 is perfect agreement/match.
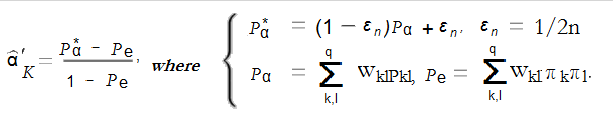
-
Sohan Subhash Mirajkar replied to Vishwadeep Khatri's topic in We ask and you answer! The best answer wins!Sandboxing is a part of automated technology for malware detection that’s widely used by several antivirus programs and other security applications. We place a potentially dangerous program into a controlled virtual environment where it cannot cause any harm, security software can then analyse the behaviour of the malware and develop security measures against it. Sandbox-evading malware is a new type of malware that can detect if it’s inside a sandbox or virtual environment. These malwares don’t execute their malicious code until they’re outside of the controlled environment. The first malware that surpassed the sandbox protection was detected in the year 1980. Real world examples of sandbox evading malware Locky ransomware which was released in 2016, is a good example of a sandbox-evading virus. It was spread through JavaScript code that was infected with encrypted DLL files. In mid of 2018, a new version of malware called the RogueRobin trojan was detected in the Middle East. This government organisation based malware was spread via email in an attached RAR archive. In 2019, hackers used the HAWKBALL backdoor to attack the government sector in Central Asia. This malware exploited vulnerabilities for Microsoft Office to deliver payloads and collect system information. In March 2019, a new sample of macOS malware using improved sandbox evading techniques was detected. As opposed to its ancestors, OSX_OCEANLOTUS.D had a Mach-O signature with a UPX string that allowed it to be not noticed during static analysis in a virtual environment. Protection from sandbox-evading malware: 1. Dynamically change sleep duration 2. Simulate human interactions 3. Add real environmental and hardware artifacts 4. Perform static in addition to dynamic analysis 5. Use fingerprint analysis 6. Use behavior-based analysis 7. Customize your sandboxing 8. Add kernel analysis 9. Implement machine learning 10. Consider content disarm and reconstruction (CDR) as an extra security layer
-
Sohan Subhash Mirajkar replied to Vishwadeep Khatri's topic in We ask and you answer! The best answer wins!A q-value is a same as p-value that has to be adjusted for the False Discovery Rate(FDR). The False Discovery Rate (FDR) is the proportion of false positives you can expect to get from a test. While a p-value gives you the probability of a false positive on a single test; If you’re running hundreds or thousands of tests from small samples commonly used in fields like genomics, we can use q-values. Usually we need to decide ahead of time the level of false positives we are willing to accept for which under 5% is the norm. This means that you run the risk of getting a false statistically significant result every 5% of time. As we know false positives (p-values) form facts of life and are unavoidable. While 5% might be an acceptable false positive rate for running one test, it becomes completely unacceptable if you run thousands of tests on the same small data set. Circumstances to prefer to work with a q-value instead of p-value Imagine we are planning scratch off lotto system, and we have a 5% chance of getting a winning lotto ticket. One lotto ticket gives us a 5% chance, but if we buy enough lotto tickets, probability tells us that we will eventually get a winner (Buying 1000 lotto tickets should do the solution and will in fact give us, on average, 50 winning lotto tickets). The same is also true for laboratory test results. In the first test on our lab data, we have a 5% chance of a false positive. In the second test on our lab data, we have another 5% chance of a false positive. In the thousandth test on your data, you have had a 5% chance of a false positive a thousand times. We can get a false positive, a false significant result, if we run enough tests. For example at a 5% FDR, we get 5 false results for every 100 tests we run, or 50 for every thousand. This is a pretty high value. This is known as multiple testing problem. The False Discovery Rate (FDR) approach to p-values assigns an adjusted p-value for each test. This is called the “q-value.”
-
Sohan Subhash Mirajkar replied to Vishwadeep Khatri's topic in We ask and you answer! The best answer wins!Kepner Tregoe method is based on 4 rational processes in which 4 fundamental questions are answered: In Situation analysis it clarifies the problem situation on what happened ? In Problem analysis the actual cause of the problem & the relationship between cause and result were searched for why did it happen ? In Decision analysis it was based on the decision making criteria, choices are made to arrive at potential problem resolutions on how should we act ? In Potential Problem analysis the potential future problems were anticipated and preventative actions are developed as to what will the result be ? KT method is a 8 step process namely: Step 1 – Create a decision statement Step 2 – Define operational objectives Step 3 – Weight operational objectives Step 4 – Generate a list of alternatives Step 5 – Assign relative scores to each alternative Step 6 – Rank the highest-scoring alternatives Step 7 – Generate a list of problems Step 8 – Compare rankings Examples: 1. In order to better serve its customers, Microsoft’s Customer Service & Support (CSS) incorporated the Kepner-Tregoe methodology into CSS systems and metrics around the world. 2. Target Corporation implemented the Kepner-Tregoe (KT) approach to improve IT incident management performance to speed up the resolution process of the incidents with minimal impact on operations and customers
-
Sohan Subhash Mirajkar replied to Vishwadeep Khatri's topic in We ask and you answer! The best answer wins!Thematic Analysis as the name gives us an idea is all about analysing the patterns or themes of data. It is useful for qualitative data analysis which means it can be used to analyse non-numerical data like may be audio/video/text during data collected from focus groups, interviews or surveys. In this method qualitative data is analysed and coding label is provided through a process of coding to understand explicit and implicit meanings of the data and then convert it to themes through iterative comparison. Different types of Thematic Analysis are: 1. Inductive 2. Deductive 3. Semantic 4. Latent Steps in Thematic Analysis: Step 1: Familiarization Step 2: Coding Step 3: Generating Themes Step 4: Reviewing themes Step 5: Defining themes Step 6: Writing Example in Six Sigma: Inductive Thematic Analysis: 1. Observation– a office lift is busy 2. Look for a pattern– the office lift is busy from 10 am to 7 pm. 3. Develop a theory– a office lift is busy during working hours. Deductive Thematic Analysis It depends on the Inductive approach, Starting with a theory– the Office has busy lift during working hours. Formulate a hypothesis– generally, all offices are having busy lifts during working hours. Collecting data to study hypothesis- observing all the office lifts during the working hours every day. Analyse the result (does collected data reject or validate the hypothesis)- since all the office lifts are busy during working hours -> support a hypothesis.
-
Sohan Subhash Mirajkar replied to Vishwadeep Khatri's topic in We ask and you answer! The best answer wins!I would prefer any of the Grubbs vs Box Plot based on the situation. If someone wants to detect presence of single outlier one at a time in in an univariate data set that follows an approximately normal distribution then we can use Grubbs Test. For simplicity I would go for Grubbs test by following points I will find the G test statistic. I will find the G Critical Value. Then I would compare the test statistic to the G critical value. The reject the point as an outlier if the test statistic is greater than the critical value. I will compare G test statistic to the G critical value: If Gtest < Gcritical: I will keep the point in the data set; it is not an outlier. If Gtest > Gcritical: I would reject the point as an outlier. Also Grubbs test is defined when we have following hypothesis H0: If there is no outliers in the dataset Ha: If there is only one outlier in the dataset. We can use Box plot when we want to compare the shapes of distributions, find central tendencies, assess variability and also identify outliers. Boxplots display 5 number summary. Box plots present ranges of values based on quartiles and display asterisks for outliers that fall outside the whiskers. Box plots work by breaking your data down into quartiles. When your sample size is too small, the quartile estimates might not be meaningful. These box plots work best when you have at least 20 data points per group. The upper whisker = top approx 25 % of data Box = middle 50% of data lower whisker = bottom approx 25 % of data If we have multiple distributions box plots are good method Example: Suppose we have five groups of scores and we want to compare them by Agile Coaching method we can use Box Plot method.
-
Sohan Subhash Mirajkar changed their profile photo
-
Sohan Subhash Mirajkar replied to Vishwadeep Khatri's topic in We ask and you answer! The best answer wins!I can suggest following guidelines for the operations team: 1. There are seven types of wastes namely Overproduction, Inventory, Defects, Motion, Over-processing, Waiting, Transportation, Underutilised staff which should be taken into consideration. These wastes adds cost without adding any value and does not change in the existing process nor customer will be ready to pay for it. 2. Operations team need to establish an SLA workflows in their system , so that they can prioritize their tickets as per the business impact and customer needs and deliver without delays. Then create a Value Stream Map to understand which are the waste activities which delay the customer delivery and remove it to optimize the flow that adds value (Quality/less defects), reduces cost (Over processing), transforms positive change (Motion) in the product delivery and increases profit & customer satisfaction. 3. Also their should be collaboration of operations team with the customer to give feedback regularly, so that time is not wasted in creating a wrong product or service delivery (Defects/Defectives).
